Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
欢迎使用Bookshelf-Qabot,这是一个个人知识库助理项目,旨在快速,准确地使用大语言模型的力量来简化您对大量信息的访问。该多功能工具非常适合研究人员,企业主和需要有效的信息管理的任何人。它的可扩展性使其非常适合希望增强其客户服务能力的企业,从而对客户查询提供快速准确的响应。无论您是优化个人生产力还是提高业务运营,该项目都是为您量身定制的。
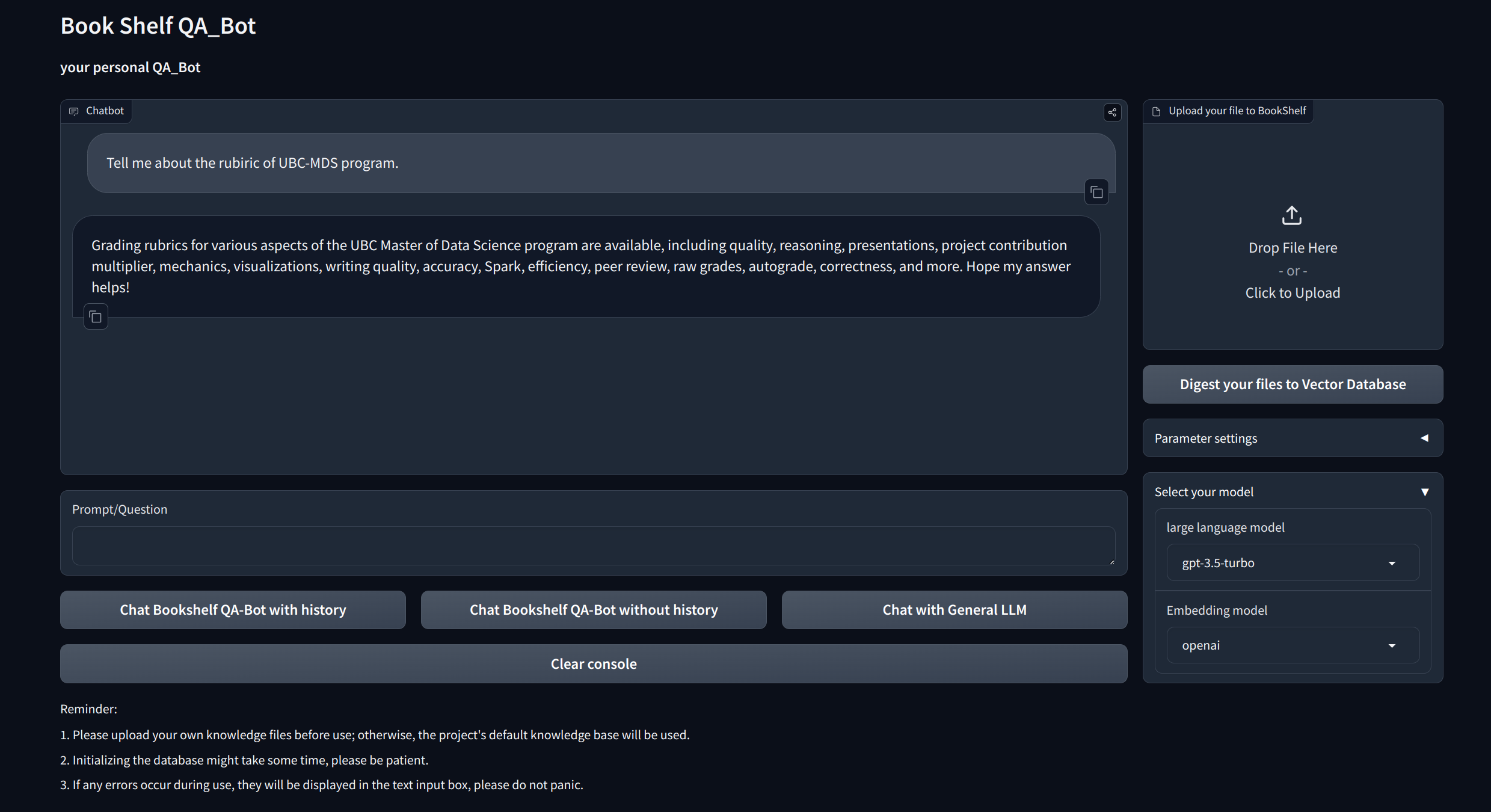
与抹布的交互式问答:利用检索功能的生成(RAG)体系结构来促进动态和精确的问题回答。
可视化接口:通过FastApi通过Gradio和API提供易于启动的接口,以启动项目,演示问答和展示示例。
自定义知识管理:提供个性化选项,以根据您的喜好调整知识库。用户可以上传和矢量化自己的凝结,以构建一个独特的“书架”,该“书架”涉及某些特定领域的信息。
多模型兼容性:支持多个大型语言模型(LLM)(例如GPT-3.5,GPT4等)之间的无缝切换。这种灵活性使用户可以为特定任务选择最佳模型,从而优化准确性,响应速度和成本。
克隆并设置该项目:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txt设置API密钥
从OpenAI获取API键,并在root Directory下创建.ENV文件。复制并粘贴API字符串,并使用以下格式。
OPENAI_API_KEY= " you openai api key string "启动本地API服务器:
cd app
uvicorn api:app --reload
或者您可以简单地运行
bash app/run_api.sh
通过Gradio运行项目:
python app/run_gradio.py该项目利用基于大语言模型的全栈方法,该方法建立在兰班框架上。核心技术包括LLM API呼叫,抹布,矢量数据库和检索问答链。该项目的整体架构如下:
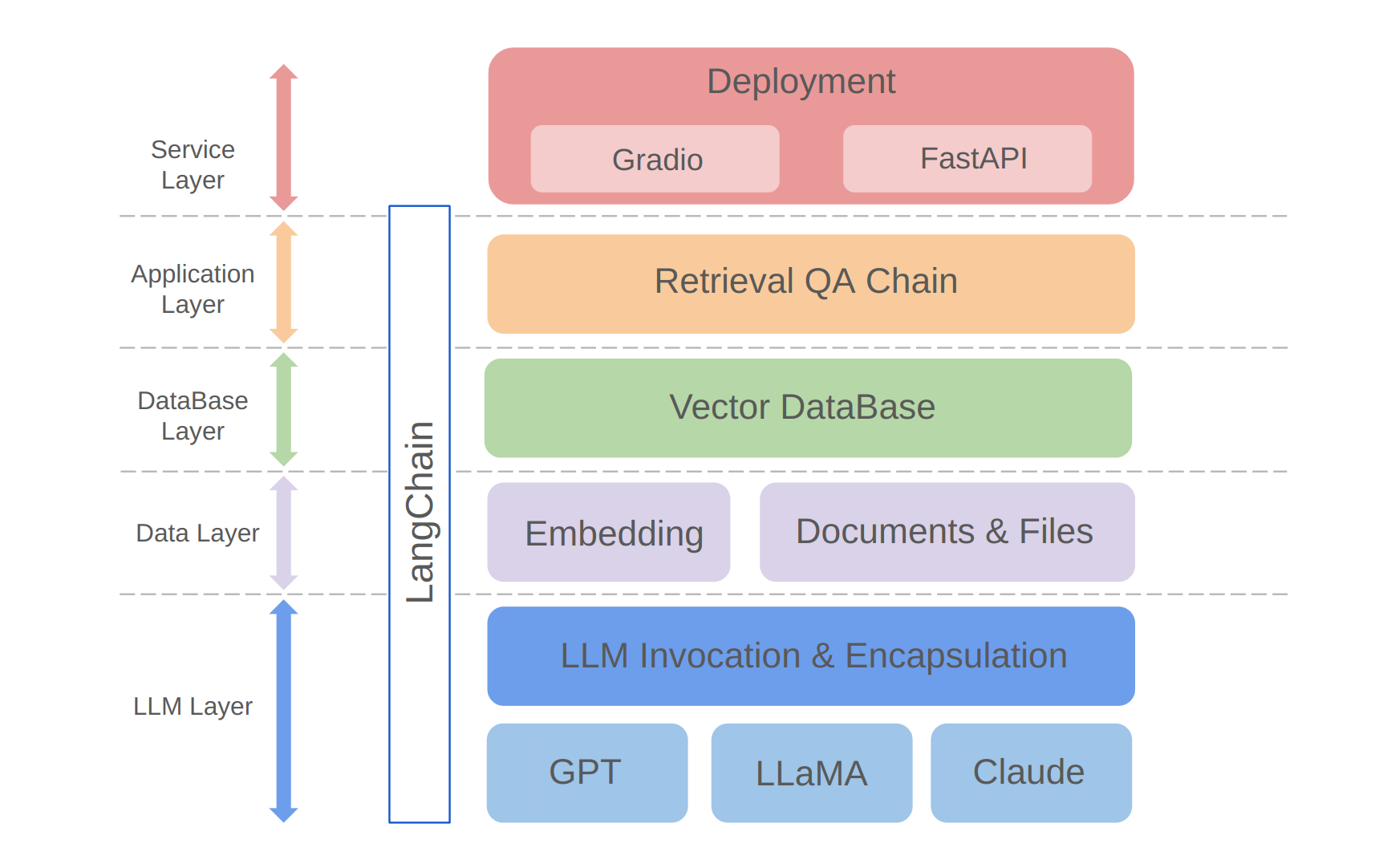
如上所示,该项目是从自下而上的LLM层,数据层,数据库层,应用程序层和服务层构造的。
①LLM层主要涉及LLM的封装,要求使用几个流行的LLM API和型号,从而使用户有一个统一的入口和访问不同型号的方式,支持在线模型切换;
②数据层主要包括个人知识库和嵌入API的源数据,在该数据库中,嵌入处理后的源数据可以由矢量数据库使用;
③数据库层主要基于基于个人知识基源数据的向量数据库,我在该项目中选择了Chroma;
④应用程序层是核心功能的顶层封装,我们根据Langchain提供的检索问答链基类进一步封装,从而支持不同的模型开关并促进基于数据库的检索Q&A的实现;
⑤顶层是服务层,在那里我实施了Gradio来构建演示和FastApi来组装API以支持项目的服务访问。
感谢您对该项目的关注。我期待着您的贡献,并了解如何使用它来增强信息管理和检索任务,或将其扩展到客户服务等业务应用程序!


