Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
Willkommen im Buchhandel-Qabot, es ist ein persönliches Wissensbasis-Assistant-Projekt, eine Lappenlösung, die Ihren Zugriff auf große Mengen an Informationen schnell und genau mit der Kraft großer Sprachmodelle rationalisiert. Dieses vielseitige Tool eignet sich perfekt für Forscher, Geschäftsinhaber und alle, die ein effizientes Informationsmanagement benötigen. Die Skalierbarkeit macht es ideal für Unternehmen, die ihre Kundendienstmöglichkeiten verbessern und schnelle und genaue Antworten auf Kundenanfragen liefern. Unabhängig davon, ob Sie die individuelle Produktivität optimieren oder einen Geschäftsbetrieb verbessern, ist dieses Projekt für Sie zugeschnitten.
Interaktive Q & A mit LAG : Nutzen Sie die Architektur (Abruf-ausgereihter Generation), um eine dynamische und präzise Beantwortung der Frage zu erleichtern.
Visualisierungsschnittstellen : Bietet einfach zu navigierende Schnittstellen über Gradio und APIs über Fastapi zum Starten des Projekts, zum Demonstration von Fragen und Antworten und dem Präsentieren von Beispielen.
Customized Knowledge Management : Bietet Personalisierungsmöglichkeiten, um die Wissensbasis auf Ihre Vorlieben zuzuschneiden. Benutzer können ihre eigenen Dukomente hochladen und vektorisieren, um ein einzigartiges "Bücherregal" zu erstellen, das sich mit bestimmten domänenspezifischen Informationen befasst.
Multi-Model-Kompatibilität : Unterstützt nahtloses Wechsel zwischen mehreren großen Sprachmodellen (LLMs) wie GPT-3,5, GPT4 und mehr. Mit dieser Flexibilität können Benutzer das beste Modell für bestimmte Aufgaben auswählen und die Genauigkeit, die Reaktionsgeschwindigkeit und die Kosten optimieren.
Klon und das Projekt einrichten:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtRichten Sie die API -Schlüssel ein
Holen Sie sich den API -Schlüssel von OpenAI und erstellen Sie eine .EnV -Datei unter Root -Verzeichnis. Kopieren Sie die API -Zeichenfolge mit dem folgenden Format.
OPENAI_API_KEY= " you openai api key string "Starten Sie den lokalen API -Server:
cd app
uvicorn api:app --reload
Oder Sie können einfach rennen
bash app/run_api.sh
Führen Sie das Projekt über Gradio aus:
python app/run_gradio.pyDieses Projekt nutzt einen Vollstack-Ansatz, der auf großsprachigen Modellen basiert und auf dem Langchain-Framework basiert. Die Kerntechnologie umfasst LLM -API -Aufrufe, Lappen, Vektor -Datenbanken und Retrieval -Q & A -Ketten. Die Gesamtarchitektur des Projekts lautet wie folgt:
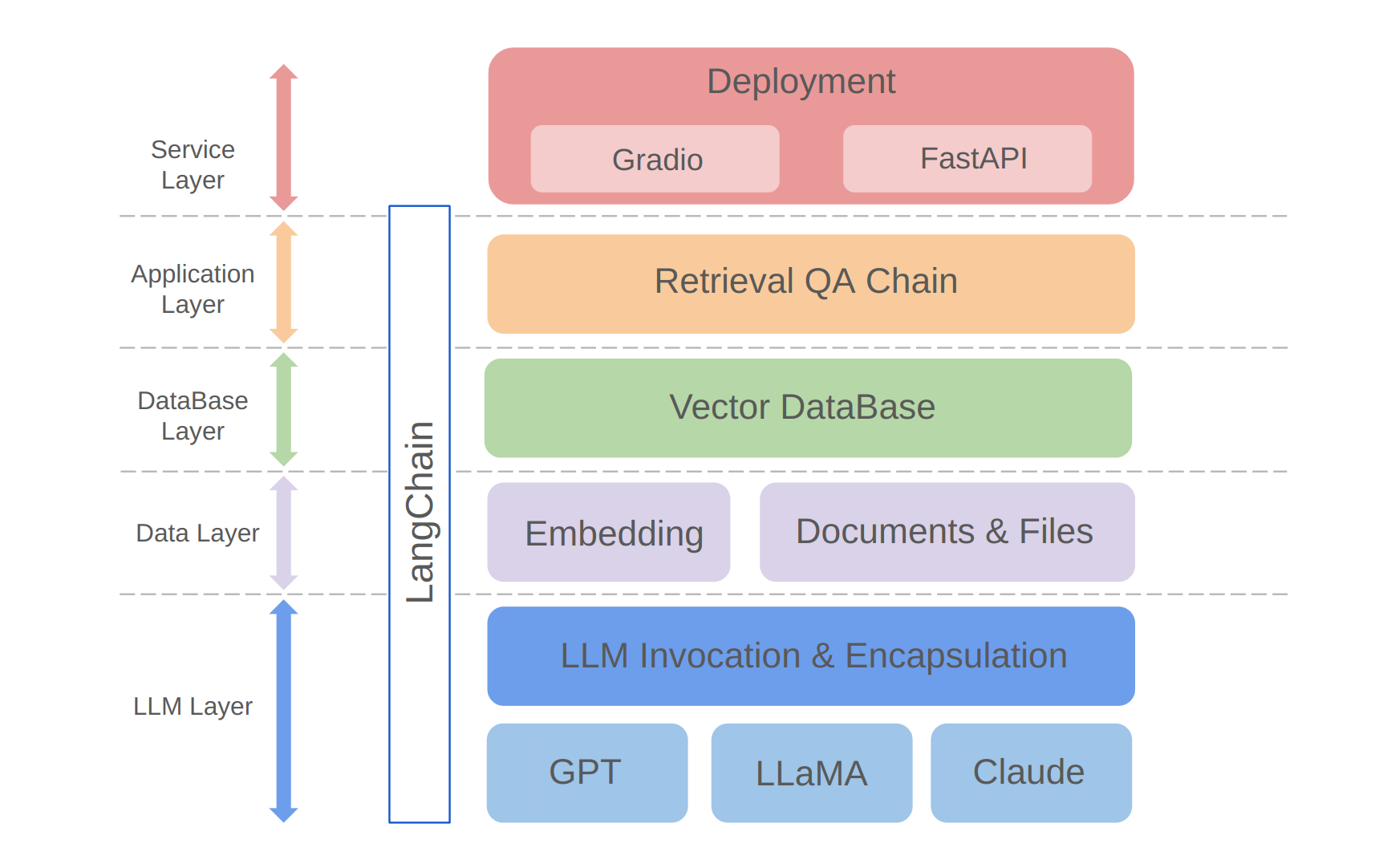
Wie oben gezeigt, ist das Projekt von unten nach oben in die LLM -Ebene, die Datenschicht, die Datenbankschicht, die Anwendungsschicht und die Serviceschicht strukturiert.
① Die LLM-Schicht umfasst hauptsächlich die Einkapselung von LLM-Forderungen für mehrere beliebte LLM-APIs und -modelle, mit der Benutzer einen einheitlichen Eingang und einen einheitlichen Weg ermöglichen, um auf verschiedene Modelle zuzugreifen und auf dem Fliegemodellschalter zu unterstützen.
② Die Datenschicht enthält hauptsächlich die Quelldaten der persönlichen Wissensbasis und der Einbettungs -API, wobei die Quelldaten nach der Einbettungsverarbeitung in der Vektordatenbank verwendet werden können.
③ Die Datenbankschicht basiert hauptsächlich auf der Vektor -Datenbank, die auf den persönlichen Wissensbasisquellendaten basiert, für die ich mich in diesem Projekt Chroma entschieden habe.
④ Die Anwendungsschicht ist die obere Schichtkapselung der Kernfunktionen, bei der wir basierend auf der von Langchain bereitgestellten Abruf-Q & A-Ketten-Basisklasse weiter eingekapselt sind, wodurch verschiedene Modellschalter unterstützt und die Implementierung von Datenbankbasis-Abruf-Q & A ermittelt werden.
⑤ Die oberste Ebene ist die Serviceschicht, in der ich Gradio implementiert habe, um Demos und Fastapi zu erstellen, um APIs zusammenzustellen, um den Servicezugriff des Projekts zu unterstützen.
Vielen Dank für Ihr Interesse an diesem Projekt. Ich freue mich auf Ihre Beiträge und sehe, wie Sie damit Ihre Informationsmanagement- und Abrufaufgaben verbessern oder sie für Geschäftsanwendungen wie den Kundendienst skalieren!


