Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
Добро пожаловать в книжную полку-Кабот, это помощник по личной базе знаний, тряпичное решение, предназначенное для оптимизации вашего доступа к огромным объемам информации быстро и точно с использованием мощности крупных языковых моделей. Этот универсальный инструмент идеально подходит для исследователей, владельцев бизнеса и любого, кто нуждается в эффективном управлении информацией. Его масштабируемость делает его идеальным для предприятий, стремящихся расширить свои возможности обслуживания клиентов, обеспечивая быстрые и точные ответы на запросы клиентов. Независимо от того, оптимизируете ли вы индивидуальную производительность или повышаете бизнес, этот проект адаптирован для вас.
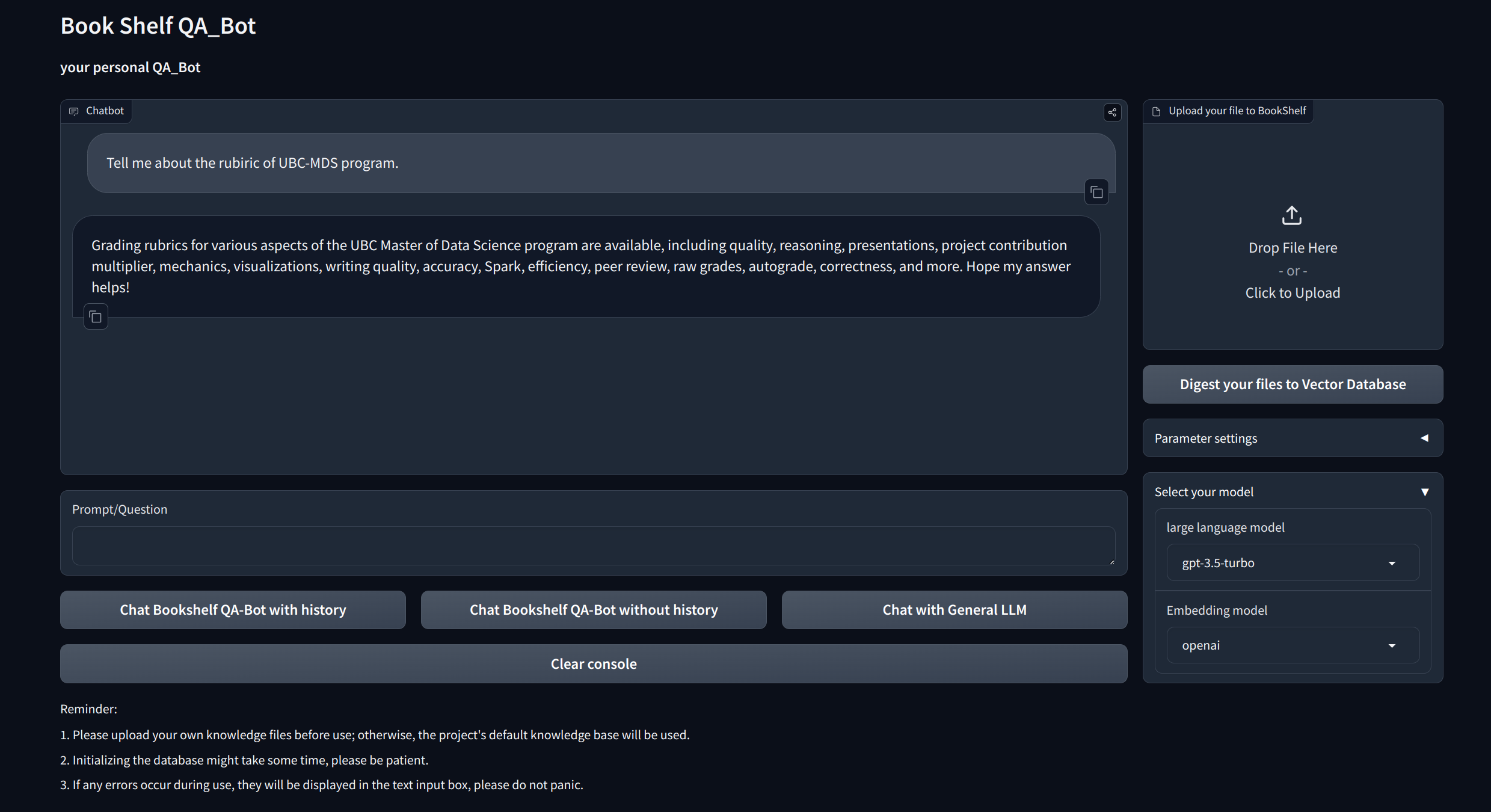
Интерактивные вопросы и ответы с тряпкой : Используйте архитектуру получения поколения (RAG), чтобы облегчить динамический и точный ответ на вопрос.
Интерфейсы визуализации : обеспечивает простые в навигации интерфейсы через Gradio и API через Fastapi для запуска проекта, демонстрации вопросов и ответов и демонстрации примеров.
Индивидуальное управление знаниями : предлагает варианты персонализации для адаптации базы знаний к вашим предпочтениям. Пользователи могут загружать и векторизировать свои собственные германты, чтобы создать уникальную «книжную полку», которая занимается определенной информацией, специфичной для домена.
Совместимость с несколькими моделями : поддерживает бесшовное переключение между несколькими крупными языковыми моделями (LLM), такими как GPT-3.5, GPT4 и многое другое. Эта гибкость позволяет пользователям выбирать лучшую модель для конкретных задач, оптимизировать точность, скорость отклика и стоимость.
Клонировать и настроить проект:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtУстановите ключ API
Получите ключ API от OpenAI и создайте файл .env в корневом каталоге. Скопируйте и вставьте строку API со следующим форматом.
OPENAI_API_KEY= " you openai api key string "Запустите локальный сервер API:
cd app
uvicorn api:app --reload
Или вы можете просто бежать
bash app/run_api.sh
Запустите проект через Gradio:
python app/run_gradio.pyЭтот проект использует подход с полным стеком, основанный на крупных языковых моделях, основанных на рамках Langchain. Основная технология включает в себя вызовы API LLM, тряпку, векторные базы данных и цепочки Q & A. Общая архитектура проекта заключается в следующем:
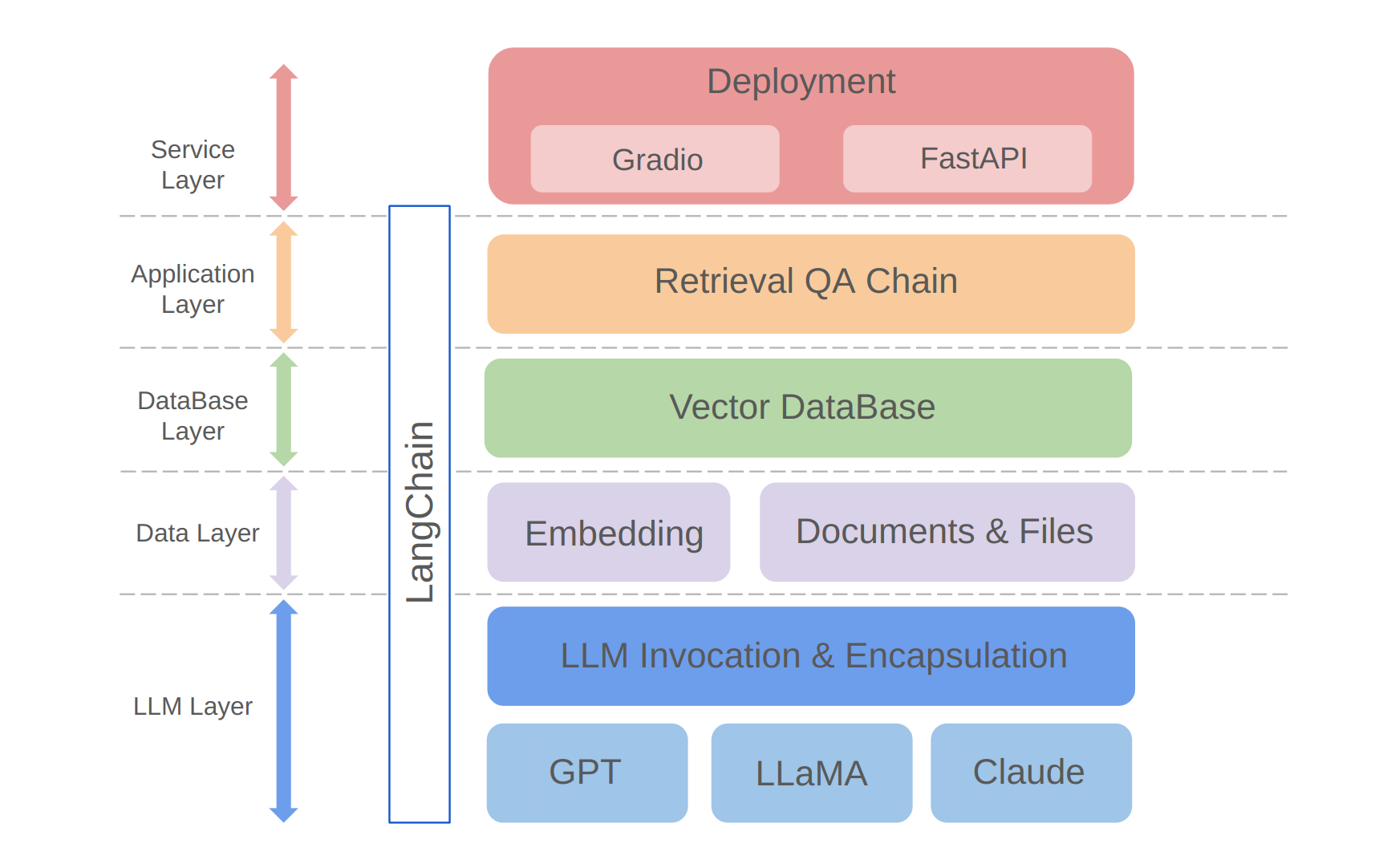
Как показано выше, проект структурирован снизу вверх в уровень LLM, уровень данных, уровень базы данных, уровень приложения и сервисный уровень.
① Слой LLM в основном включает в себя инкапсуляцию вызовов LLM для нескольких популярных API и моделей LLM, позволяя пользователям унифицированный вход и способ получить доступ к различным моделям, поддерживая переключение модели на лете;
② Уровень данных в основном включает в себя исходные данные базы персональных знаний и API встраивания, где исходные данные после обработки встраивания могут использоваться векторной базой данных;
③ Уровень базы данных в основном основан на векторной базе данных, основанной на исходных данных базы личных знаний, для которых я выбрал Chroma в этом проекте;
④ Приложенный слой представляет собой инкапсуляцию основных функций основных функций, где мы дополнительно инкапсулировали на основе поискового базового класса Q & A.
⑤ Верхний слой - это сервисный уровень, где я внедрил Gradio для создания демонстраций и Fastapi для сборки API для поддержки доступа к сервису проекта.
Спасибо за ваш интерес к этому проекту. Я с нетерпением жду вашего вклада и посмотрю, как вы используете его для улучшения ваших задач управления информацией и поиска или масштабировать его для бизнес -приложений, таких как обслуживание клиентов!


