很棒的文檔理解
與智能文檔處理(IDP)相關的文檔理解資源(DU)主題的策劃資源列表,該主題與非組織數據相對於機器人過程自動化(RPA),尤其是形成視覺上豐富的文檔(VRD)。
注意1:粗體位置比其他職位更重要。
注2:由於該領域的新穎性,此列表正在建設中 - 歡迎捐款(謝謝您!)。請記住使用以下慣例:
- 出版物 /數據集 /資源標題的標題,[代碼 /數據 /網站]
作者列表會議/期刊名稱年份
數據集尺寸:訓練(沒有示例),開發人員(否示例),測試(否示例)[數據集論文/資源的可選率];摘要/簡短描述...
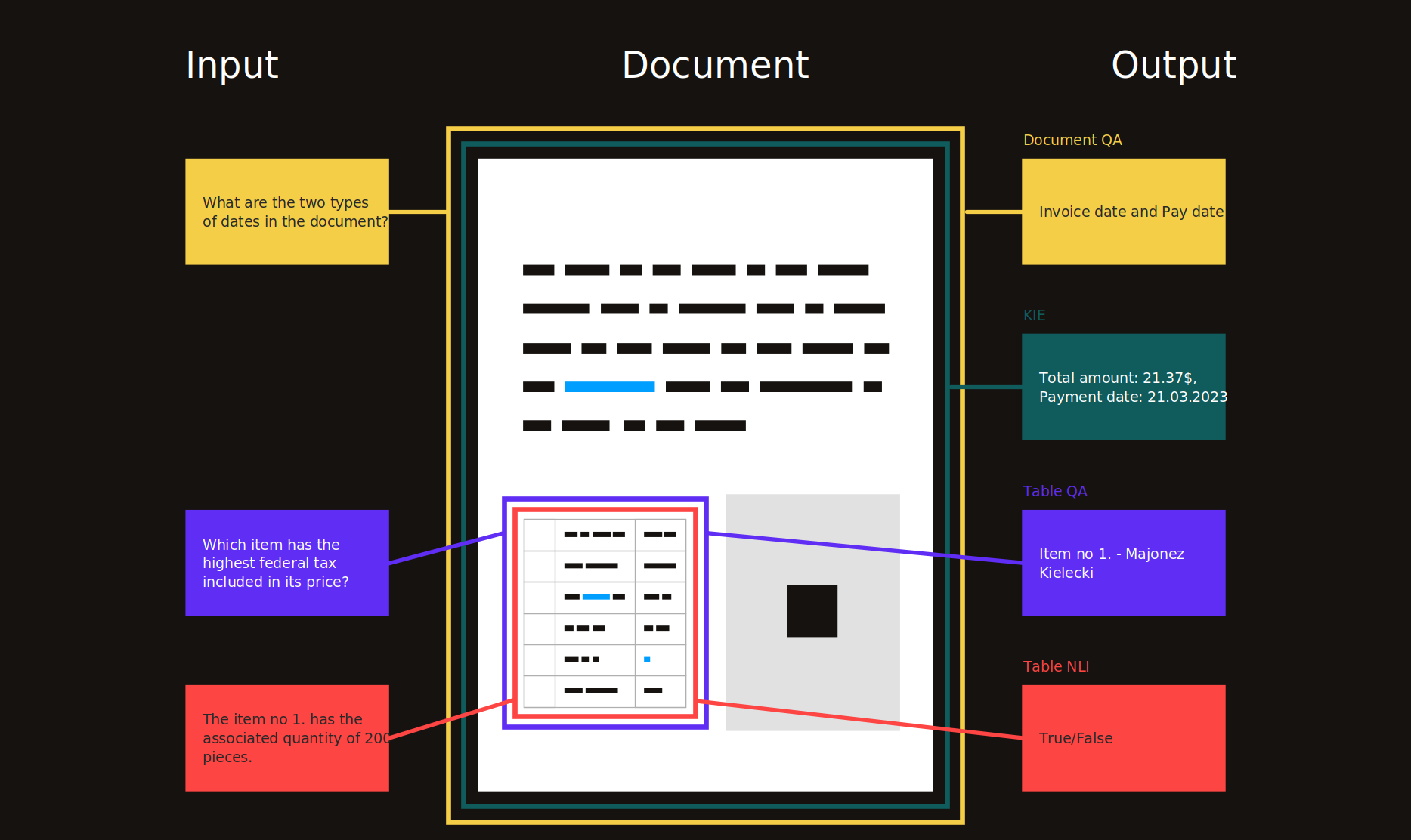
目錄
- 介紹
- 研究主題
- 關鍵信息提取(KIE)
- 文檔佈局分析(DLA)
- 文檔問答(DQA)
- 科學文檔理解(SDU)
- 光學特徵識別(OCR)
- 有關的
- 一般的
- 表格數據理解(TDC)
- 機器人過程自動化(RPA)
- 其他的
- 資源
- 用於培訓前語言模型的數據集
- PDF處理工具
- 會議 /講習班
- 部落格
- 解決方案
- 例子
- 視覺上豐富的文檔(VRD)
- 關鍵信息提取(KIE)
- 文檔佈局分析(DLA)
- 文檔問答(DQA)
- 靈感
介紹
文件是許多領域的許多業務的核心部分,例如法律,金融和技術。自動理解諸如發票,合同和簡歷之類的文件是有利可圖的,這開闢了許多新的業務途徑。自然語言處理和計算機視覺領域通過發展深度學習的發展取得了巨大的進步,使得這些方法開始在當代文檔理解系統中註入。來源
文件
2023
- 文檔信息本地化和提取的文檔基準測試,[網站] [基準] [代碼]
Štěpán Šimsa, Milan Šulc, Michal Uřičář, Yash Patel, Ahmed Hamdi, Matěj Kocián, Matyáš Skalický, Jiří Matas, Antoine Doucet, Mickaël Coustaty, Dimosthenis Karatzas arxiv pre-print 2023
本文使用最大的業務文檔數據集介紹了溫順的基準測試,以完成關鍵信息本地化和提取和行項目識別的任務。它包含6.7k註釋的商務文件,合成生成的文檔100K,無標記的文件近約1m,用於無監督的預培訓。該數據集的構建是對域和特定於任務特定方面的知識構建的,從而產生以下關鍵特徵:(i)55個類中的註釋,超過了先前發布的關鍵信息提取數據集的顆粒狀; (ii)行項目識別代表一項高度實用的信息提取任務,必須將關鍵信息分配給表中的項目; (iii)文檔來自眾多佈局,測試集包括零彈藥和幾個案例以及訓練集中常見的佈局。基準測試帶有多個基線,包括Roberta,Layoutlmv3和基於DETR的表變壓器。這些基線模型應用於溫順基準的兩個任務,並在本文中共享結果,為將來的工作提供了快速的起點。該數據集和基線可在此HTTPS URL上找到。
2022
2021
2020
對OCR和文檔理解的深度學習方法的調查
Nishant Subramani,Alexandre Matton,Malcolm Greaves,Adrian Lam ML-RSA工作室,Neurips 2020
文件是許多領域的許多業務的核心部分,例如法律,金融和技術。自動理解諸如發票,合同和簡歷之類的文件是有利可圖的,這開闢了許多新的業務途徑。自然語言處理和計算機視覺領域通過發展深度學習的發展取得了巨大的進步,使得這些方法開始在當代文檔理解系統中註入。在本調查文件中,我們回顧了用英語編寫的文檔的文檔理解的不同技術,並鞏固了文獻中存在的方法,以作為研究人員探索該領域的研究人員的起點。與文檔的對話。探索以文件為中心的援助
Maartje Ter Hoeve,Robert Sim,Elnaz Nouri,Adam Fourney,Maarten de Rijke,Ryen W. White Chiir 2020
會話助手的作用在幫助人們提高生產率方面變得更加普遍。例如,以文檔為中心的幫助,以幫助個人快速審查文檔,但進步較少,儘管它有可能大大提高用戶的生產率。這種以文檔為中心的援助是本文的重點。我們的貢獻是三個方面:(1)我們首先提出一項調查,以了解以文件為中心的援助和人們期望的能力的空間。 (2)我們調查用戶在尋求文檔幫助時會提出的查詢類型,並表明以文檔為中心的問題構成了這些查詢的大多數。 (3)我們提出了一組初始的機器學習模型,這些模型表明(a)我們可以準確地檢測到以文檔為中心的問題,並且(b)我們可以構建合理準確的模型來回答此類問題。這些積極的結果令人鼓舞,並表明,通過繼續研究這個有趣且新穎的問題空間,可以取得更大的結果。我們的發現對智能係統的設計具有影響,以通過與文檔的自然互動來支持任務完成。
2018
- 業務文件自動處理的未來範例
Matteo Cristania,Andrea Bertolasob,Simone Scannapiecoc,Claudio Tomazzolia國際信息管理雜誌2018
在本文中,我們總結了迄今為止在對開發自動處理技術開發的社區中獲得的結果,並將其應用於業務文件,並設計了一些通過本身或附加部門進步的這些技術的當前階段所要求的進化。它清楚地表明了一個領域,該領域在解決了過去30年中發生了很大變化的問題方面付出了巨大的努力,現在正在迅速發展,以將文檔處理納入一方面的文檔處理中,並包括通過在另一側引入雲計算技術而獲得的功能。我們為業務文檔處理提出了一個架構模式,該架構來自以上兩個演化線。
年齡較大
用於智能處理印刷文檔的機器學習
F. Esposito,D。 Malerba,F。 Lisi -2004
紙質文檔處理系統是一個信息系統組件,將印刷或手寫文檔上的信息轉換為可避免的計算機形式。在用於紙質文檔處理的智能係統中,處理此信息捕獲過程基於對文檔的特定佈局和邏輯結構的了解。本文提出了機器學習技術的應用來獲取名為Wisdom ++的智能文檔處理系統所需的特定知識,該系統將管理印刷文檔,例如信件和期刊。知識是通過決策樹和一階規則自動從一組培訓文檔生成的一階規則來表示的。特別是,應用了一個增量決策樹學習系統,用於獲取用於分段塊分類的決策樹,而一階學習系統則用於誘導用於基於佈局的分類和對文檔的理解的規則。討論了有關決策樹的增量誘導以及一階規則學習中數字和符號數據的處理的問題,並通過處理一組真實的印刷文檔來經驗評估所提出解決方案的有效性。文檔理解:研究方向
S. Srihari,S。 Lam,V。 Govindaraju,R。 Srihari,J。 Hull -1994
文檔圖像是印刷頁面的視覺表示形式,例如期刊文章頁面,傳真封面頁面,技術文檔,辦公室字母等。文檔的理解作為研究工作組成,包括研究通過各種表示文檔進行的所有過程:從掃描的物理文檔到文檔的高級語義描述。有用的某些表示類型是:可編輯描述,啟用精確複製的描述以及有關文檔內容的高級語義描述。該報告是對文檔理解中五個研究子域的定義,主要與印刷文檔有關。描述的主題是:用於文檔理解的模塊化體系結構;文檔的分解和結構分析;基於模型的OCR;表,圖和圖像理解;以及在失真和噪聲下的績效評估。
研究主題
- 關鍵信息提取(KIE)
- 文檔佈局分析(DLA)
- 文檔問答(DQA)
- 科學文檔理解(SDU)
- 光學特徵捲髮(OCR)
- 有關的
- 一般的
- 表格數據理解(TDC)
- 機器人過程自動化(RPA)
其他的
資源
回到頂部
用於培訓前語言模型的數據集
- RVL -CDIP數據集 - 數據集由16個類中的400,000張灰度圖像組成,每個類別有25,000張圖像
- 行業文件庫 - 由UCSF圖書館主持的影響公共衛生的行業創建的數百萬文件的門戶
- 彩色文檔數據集 - 來自阿姆斯特丹大學的智能感官信息系統
- IIT CDIP Collection-數據集由1990年代針對煙草行業的各州訴訟的文件組成,由大約700萬個文件組成
PDF處理工具
- BORB-是一個純python庫,可讀取,寫作和操縱PDF文檔。它代表PDF文檔作為嵌套列表,詞典和原語(數字,字符串,布爾值等)的類似JSON的數據結構。
- PAWLS-帶有標籤和結構的PDF註釋是軟件,它使收集與PDF文檔相關的一系列註釋變得容易
- pdfplumber- plumb a pdf,以獲取有關每個文本字符,矩形和線條的詳細信息。加上:表提取和視覺調試
- pdfminer.six -pdfminer.six是一個社區的原始pdfminer的叉子。它是從PDF文檔中提取信息的工具。它著重於獲取和分析文本數據
- 佈局解析器 - 佈局解析器是用於文檔圖像佈局分析任務的基於深度學習的工具
- Tabulo-從圖像提取表格
- OCRMYPDF -OCRMYPDF在掃描的PDF文件中添加了OCR文本層,允許它們被搜索或複制
- PDFBOX- APACHE PDFBOX庫是用於使用PDF文檔的開源Java工具。該項目允許創建新的PDF文檔,對現有文檔的操縱以及從文檔中提取內容的能力
- PDFPIG-此項目允許用戶從PDF文件中讀取和提取文本和其他內容。此外,該庫可用於創建包含文本和幾何形狀的簡單PDF文檔。該項目旨在將PDFBox端口到C#
- 解析 - pdfs-尼西亞2016年尼西亞的資源和工作表
- PDF-TEXT-ETTRACT-BENCHMARC- PDF工具基準測試
- 天生的數字PDF掃描儀 - 檢查PDF是否是出生數字的
- OpenContracts Apache2許可,PDF註釋平台,用於視覺上富的文檔,該平台保留原始佈局並導出令牌的X,y位置數據以及跨度啟動和停止。基於爪網,但具有基於Python的後端,並且可以通過Docker Compose在本地機器,公司Intranet或Web上容易部署。
- DeepDotection Deep Doctection是一個Python庫,它使用深度學習模型精心編寫文檔提取和文檔佈局分析任務,用於圖像和PDF文檔。它不能實現模型,而是使您能夠使用備受認可的對象檢測,OCR和選定的NLP任務構建管道,並為微調,評估和運行模型提供了集成的框架。
- Pydoxtools Pydoxtools是用於DPocument分析的AI組合庫。它具有廣泛的工具集,用於構建複雜的文檔分析管道,並識別開箱即用的大多數文檔格式。它支持典型的NLP任務,例如關鍵字,摘要,Question_answering開箱即用。並具有高質量的低CPU/內存表提取算法,並使集群上的NLP批處理操作變得容易。
會議,講習班
回到頂部
一般 /企業 /金融
- 國際文檔分析與認可會議(ICDAR) [2021,2019,2017]
- 文檔智能(DI)[2021,2019]的研討會
- 財務敘事處理研討會(FNP)[2021,2020,2019]
- 經濟學和自然語言處理研討會(ECONLP)[2021,2019,2018]
- 國際文檔分析系統(DAS)[2020,2018,2016]
- ACM金融AI國際會議(ICAIF)
- 金融服務中非結構化數據的AAAI-21知識發現研討會
- CVPR 2020關於深度學習時代文本和文檔的研討會
- KDD金融機器學習研討會(KDD MLF 2020)
- Finir 2020:關於金融信息檢索的第一個研討會
- 第二KDD關於金融異常檢測的研討會(KDD 2019)
- 文檔理解會議(DUC 2007)
科學文檔的理解
- AAAI-21科學文檔理解研討會(SDU 2021)
- 學術文檔處理的第一個研討會(SDProc 2020)
- 國際科學文檔分析研討會(SCIDOCA)[2020,2018,2017]
部落格
回到頂部
- 文檔理解模型的調查,2021
- 文檔表格提取,2021
- 如何使用非結構化數據自動化流程,2021
- 與RPA和文檔理解的OCR綜合指南,2021
- 從圖形卷積網絡的收據中提取信息,2021
- 如何從發票中提取結構化數據,2021
- 從2020
- 為了永久應用AI,請思考表格提取,2020年
- UIPATH文檔理解解決方案體系結構和方法,2020年
- 如何自動從復雜文檔中提取數據? ,2020
- Legaltech:2020年法律文件中的信息提取
解決方案
回到頂部
大公司:
- 艾比
- 埃森哲
- 亞馬遜
- Google
- 微軟
- UIPATH
較小:
- applica.ai
- base64.ai
- DOCSTACK
- 元素AI
- 指示
- Instabase
- Konfuzio
- metamaze
- 奈米
- 羅森
- 筒倉
例子
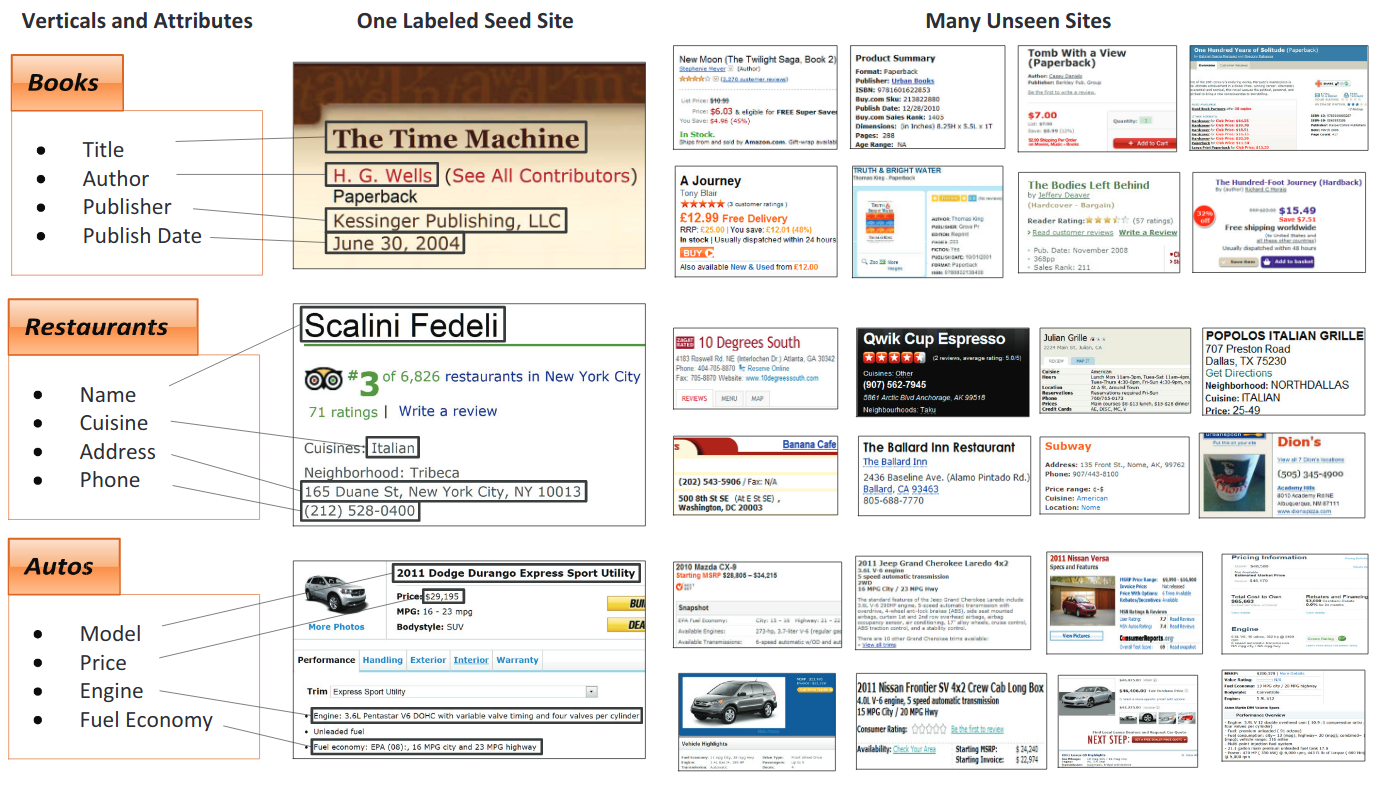
視覺上豐富的文件
回到頂部
在VRD中,佈局信息的重要性對於正確理解整個文檔至關重要(幾乎所有業務文件都是這種情況)。對於人類,空間信息可提高可讀性和速度文檔的理解。
發票 /簡歷 /職位廣告

NDA /年度報告

關鍵信息提取
回到頂部
該任務的目的是從包含相似關鍵實體的文檔集合中提取許多關鍵字段的文本。
掃描收據
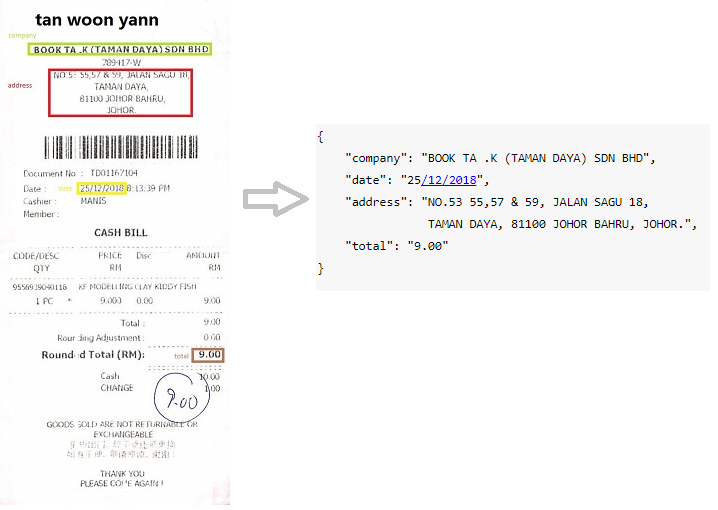
NDA /年度報告
Kleister數據集的真實業務應用程序和數據的示例(關鍵實體為藍色)
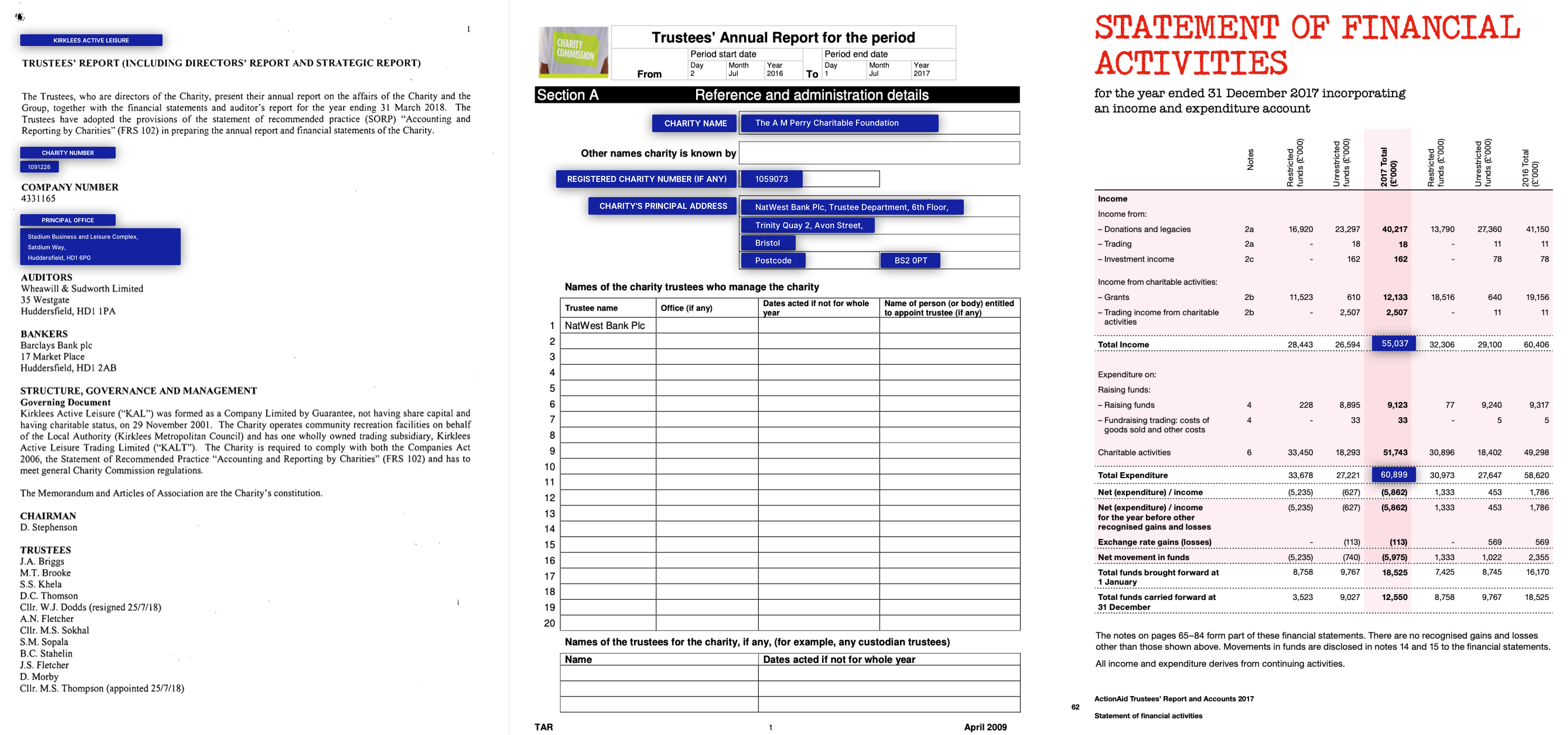
多媒體在線傳單
商業房地產傳單和手動輸入列表信息的一個示例©Promaker Commercial Real Estate LLC,©Brokersavant Inc.
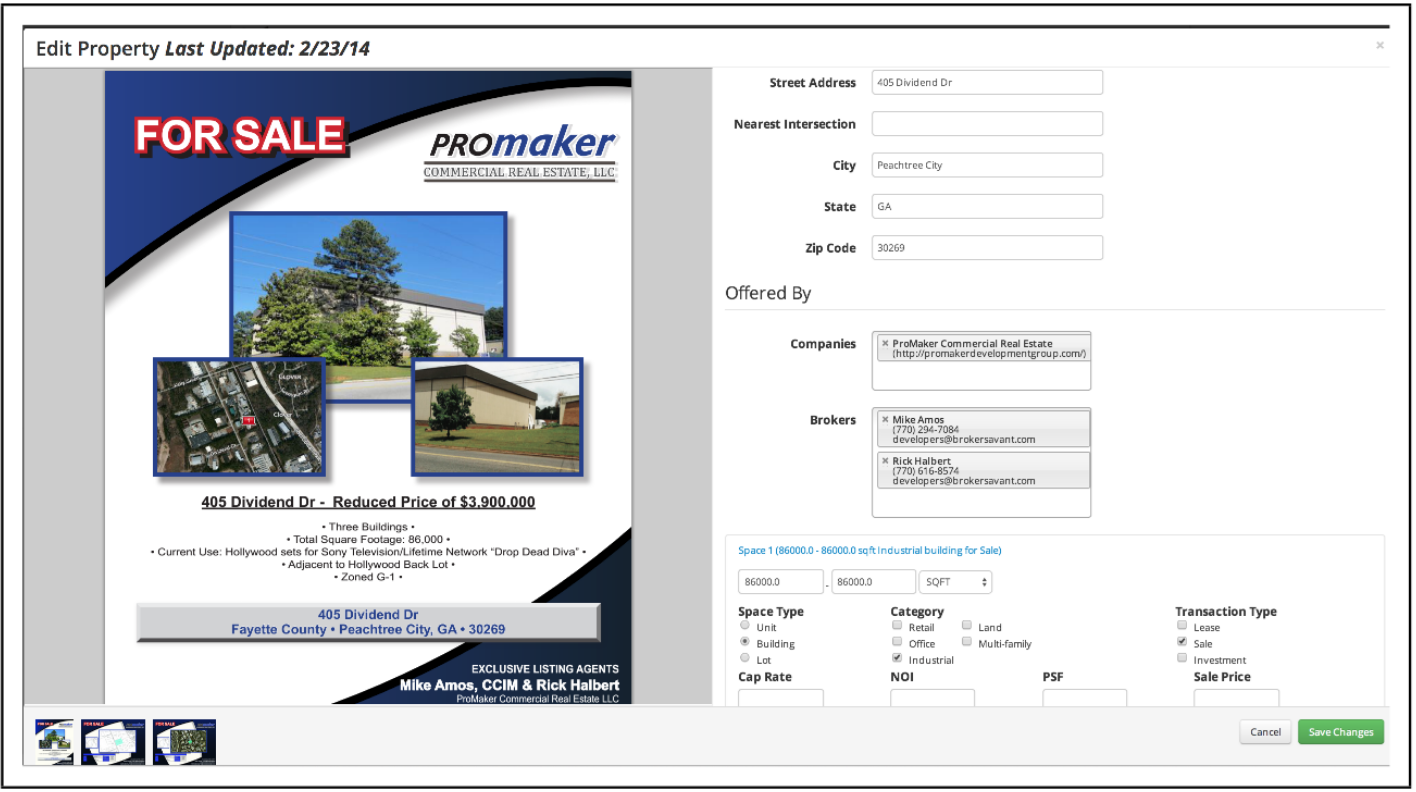
增值稅發票

網頁
文檔佈局分析
回到頂部
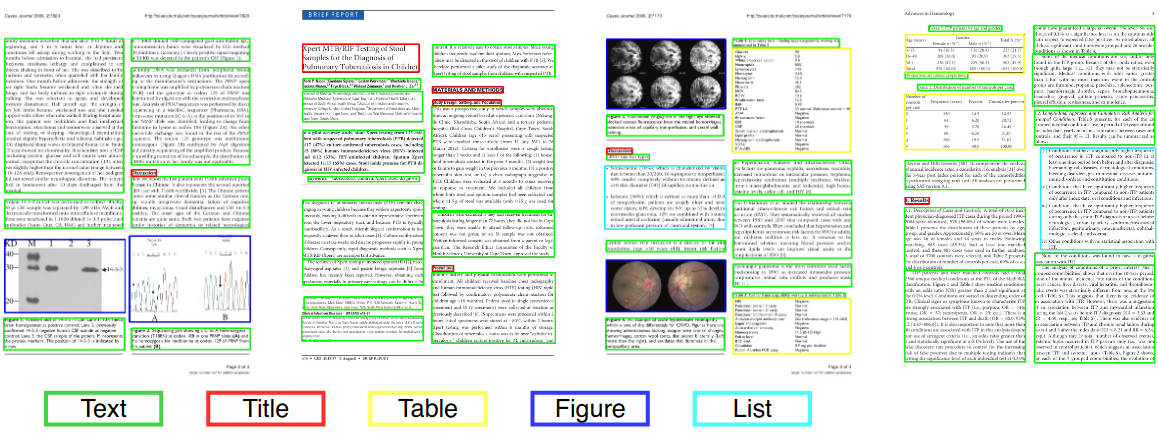
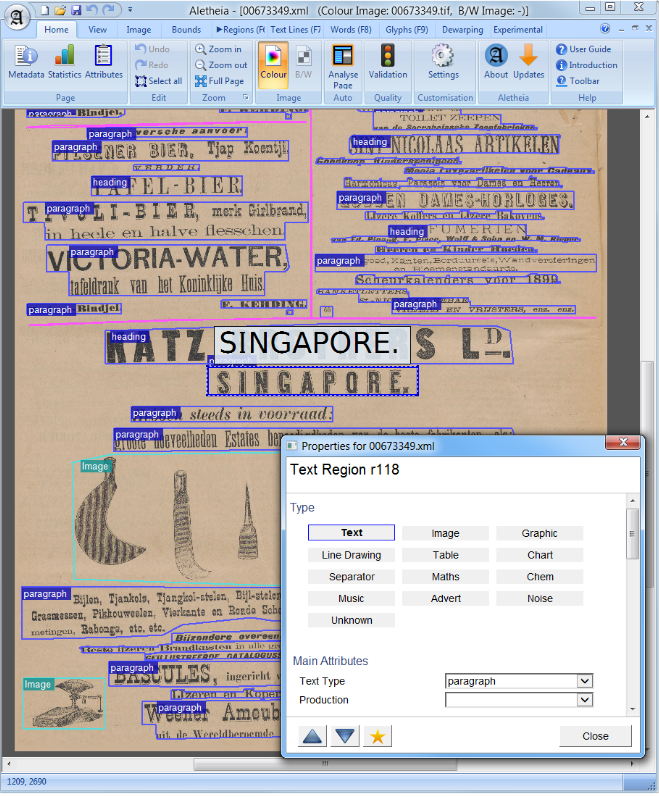
在計算機視覺或自然語言處理中,文檔佈局分析是在文本文檔的掃描圖像中識別和分類感興趣區域的過程。閱讀系統需要從非文本的文本區域進行分割,並按照其正確的閱讀順序進行排列。將不同區域(或塊)作為文本主體,插圖,數學符號和嵌入文檔中嵌入的表格的檢測和標記稱為幾何佈局分析。但是文本區域內在文檔(標題,字幕,腳註等)中扮演著不同的邏輯角色,這種語義標記是邏輯佈局分析的範圍。 (https://en.wikipedia.org/wiki/document_layout_analysis)
科學出版物

歷史報紙
業務文件
紅色:文本塊,藍色:圖。

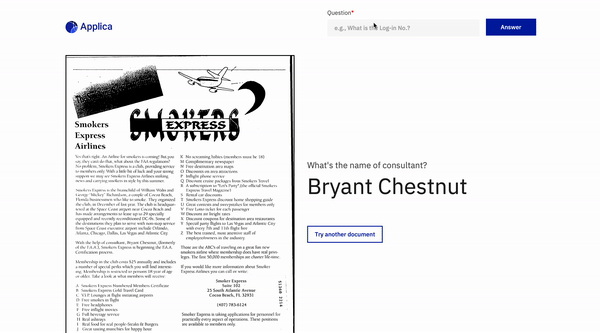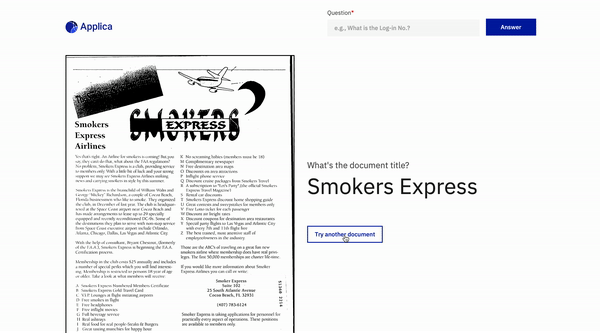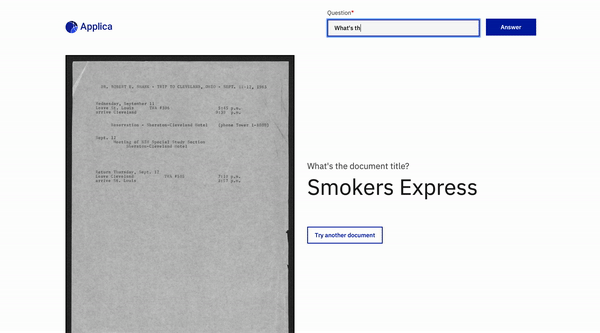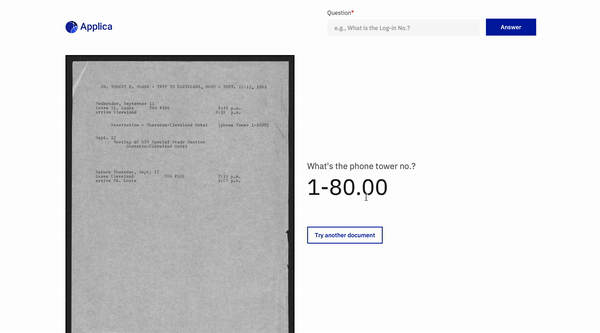
文件問題回答
回到頂部
DOCVQA示例

傾斜模型演示
靈感
回到頂部
領域
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentlayoutanalysis
- https://github.com/bikash/documentunderstanding
- https://github.com/harpribot/awesome-information-retrival
- https://github.com/roomylee/awesome-relation-traction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity與與papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
一般AI/DL/ml
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


