Entendimiento de documentos impresionante
Una lista curada de recursos para la comprensión de documentos (DU) tema relacionado con el procesamiento inteligente de documentos (IDP), que es relativo a la automatización de procesos robóticos (RPA) de los datos no estructurados, especialmente forman documentos visualmente ricos (VRD).
Nota 1: Las posiciones en negrita son más importantes que otras.
Nota 2: Debido a la novedad del campo, esta lista está en construcción: las contribuciones son bienvenidas (¡gracias de antemano!). Recuerde usar la siguiente convención:
- Título de un título de publicación / conjunto de datos / recursos, [código / datos / sitio web]
Lista de autores Conferencia/Nombre de la revista Año
Tamaño del conjunto de datos: trenes (no de ejemplos), dev (no de ejemplos), prueba (no de ejemplos) [opcional para documentos/recursos del conjunto de datos]; Resumen/Descripción corta ...
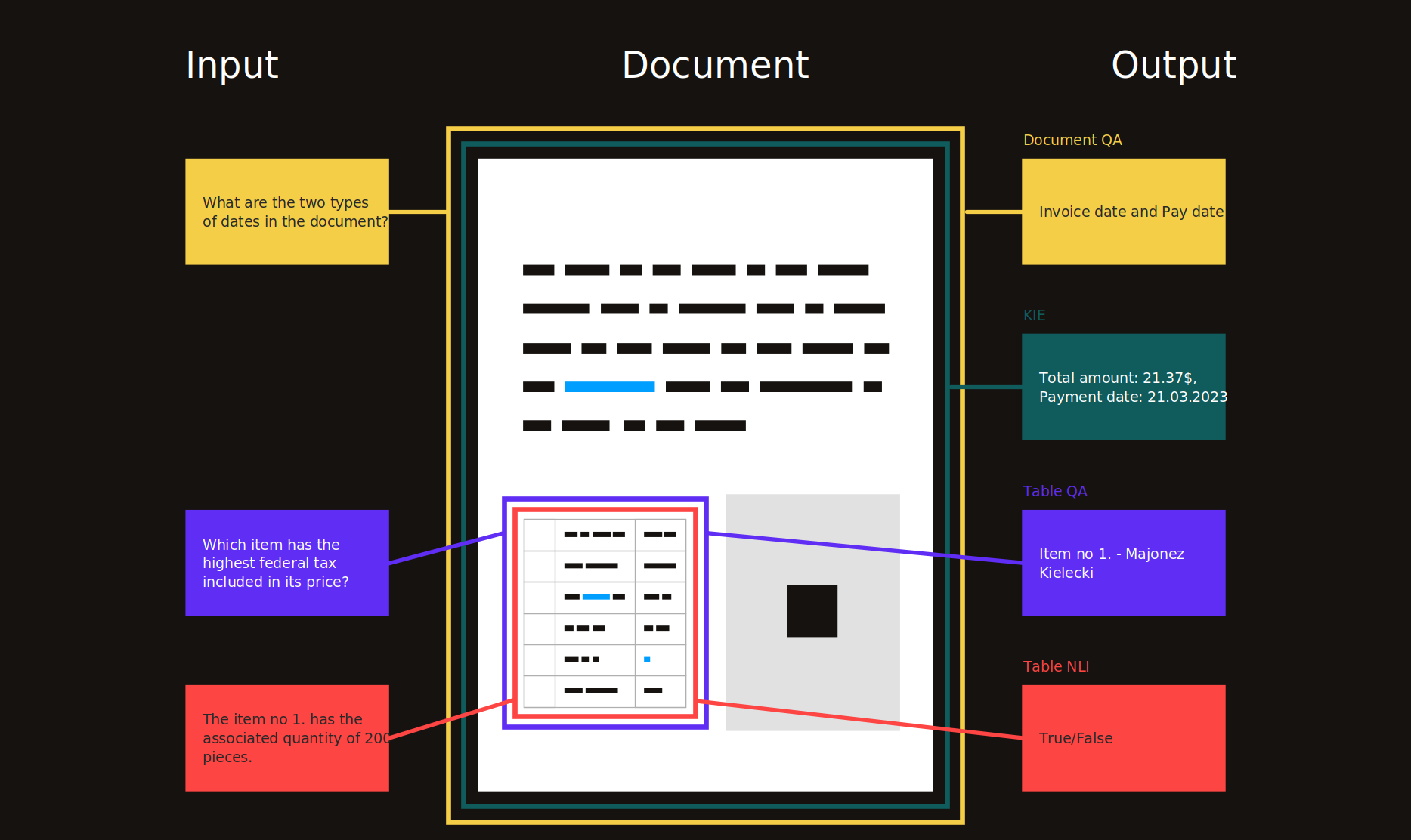
Tabla de contenido
- Introducción
- Temas de investigación
- Extracción de información clave (Kie)
- Análisis de diseño de documentos (DLA)
- Respuesta de preguntas de documento (DQA)
- Comprensión de documentos científicos (SDU)
- Reconocimiento de caracteres ópticos (OCR)
- Relacionado
- General
- Comprensión de datos tabulares (TDC)
- Automatización de procesos robóticos (RPA)
- Otros
- Recursos
- Conjuntos de datos para modelos de lenguaje previo a la capacitación
- Herramientas de procesamiento de PDF
- Conferencias / talleres
- Blogs
- Soluciones
- Ejemplos
- Documentos visualmente ricos (VRD)
- Extracción de información clave (Kie)
- Análisis de diseño de documentos (DLA)
- Respuesta de preguntas de documento (DQA)
- Inspiración
Introducción
Los documentos son una parte central de muchas empresas en muchos campos, como derecho, finanzas y tecnología, entre otros. La comprensión automática de documentos como facturas, contratos y currículums es lucrativa, abriendo muchas vías comerciales nuevas. Los campos del procesamiento del lenguaje natural y la visión por computadora han visto un gran progreso a través del desarrollo del aprendizaje profundo de tal manera que estos métodos han comenzado a infundirse en los sistemas contemporáneos de comprensión de documentos. fuente
Papeles
2023
- Docile Benchmark para la localización y extracción de información de documentos, [sitio web] [punto de referencia] [código]
Štěpán Šimsa, Milán Šulc, Michal Uřičář, Yash Patel, Ahmed Hamdi, Matěj Kocián, Matyáš Skalický, Jiří Matas, Antoine Doucet, Mickaël Coustaty, Dimosthenis Karatzas arxiv pre-Presint 2023
Este documento introduce el punto de referencia dócil con el mayor conjunto de datos de documentos comerciales para las tareas de localización clave de la información y el reconocimiento de la línea de extracción y línea. Contiene 6.7k documentos comerciales anotados, 100k documentos generados sintéticamente y casi ~ 1 millones de documentos no etiquetados para pre-entrenamiento no supervisado. El conjunto de datos se ha construido con conocimiento de aspectos específicos de dominio y tareas, lo que resulta en las siguientes características clave: (i) anotaciones en 55 clases, lo que supera la granularidad de los conjuntos de datos de extracción de información clave publicados previamente por un margen grande; (ii) el reconocimiento de la línea de pedido representa una tarea de extracción de información altamente práctica, donde la información clave debe asignarse a los elementos en una tabla; (iii) Los documentos provienen de numerosos diseños y el conjunto de pruebas incluye casos de cero y pocos disparos, así como diseños comúnmente vistos en el conjunto de entrenamiento. El punto de referencia viene con varias líneas de base, incluidas Roberta, LayoutLMV3 y el transformador de mesa basado en DETR. Estos modelos de referencia se aplicaron a ambas tareas del punto de referencia Dollat, con resultados compartidos en este documento, ofreciendo un punto de partida rápido para el trabajo futuro. El conjunto de datos y las líneas de base están disponibles en esta URL HTTPS.
2022
Extracción de información de documentos de negocios: hacia puntos de referencia prácticos
Matyáš Skalický, Štěpán Šimsa, Michal Uřičář, Milán Šulc Clef 2022
La extracción de información de documentos semiestructurados es crucial para la comunicación de empresa a empresa sin fricción (B2B). Si bien los problemas de aprendizaje automático relacionados con la extracción de información del documento (es decir,) se han estudiado durante décadas, muchas definiciones de problemas comunes y puntos de referencia no reflejan aspectos específicos del dominio y necesidades prácticas para automatizar la comunicación de documentos B2B. Revisamos el panorama de los problemas de documentos, es decir, conjuntos de datos y puntos de referencia. Destacamos los aspectos prácticos que faltan en las definiciones comunes y definimos los problemas clave de localización y extracción de información (KILE) y reconocimiento de pedidos de línea (LIR). Hay una falta de conjuntos de datos y puntos de referencia relevantes para el documento, es decir, en documentos comerciales semiestructurados, ya que su contenido generalmente está legalmente protegido o sensible. Discutimos posibles fuentes de documentos disponibles, incluidos datos sintéticos. DOC2Graph: una tarea del marco de comprensión del documento agnóstico basado en redes neuronales gráficas, [código]
Andrea Gemelli, Sanket Biswas, Enrico Civitelli, Josep Lladós, Simone Marinai Tie Workshop @ ECCV 2022
El aprendizaje profundo geométrico ha atraído recientemente un interés significativo en una amplia gama de campos de aprendizaje automático, incluido el análisis de documentos. La aplicación de redes neuronales Graph (GNN) se ha vuelto crucial en varias tareas relacionadas con los documentos, ya que pueden desentrañar patrones estructurales importantes, fundamentales en los procesos clave de extracción de información. Los trabajos anteriores en la literatura proponen modelos basados en tareas y no tienen en cuenta la plena potencia de los gráficos. Proponemos DOC2Graph, un marco de comprensión de documentos de tarea-agnóstico basado en un modelo GNN, para resolver diferentes tareas dados diferentes tipos de documentos. Evaluamos nuestro enfoque en dos conjuntos de datos desafiantes para la extracción de información clave en la comprensión de la forma, el análisis de diseño de facturas y la detección de la tabla
2021
Documento AI: puntos de referencia, modelos y aplicaciones
Lei Cui, Yiheng Xu, Tengchao LV, Furu Wei Arxiv 2021
El documento de IA, o la inteligencia de documentos, es un tema de investigación relativamente nuevo que se refiere a las técnicas para leer, comprender y analizar automáticamente documentos comerciales. Es una dirección de investigación importante para el procesamiento del lenguaje natural y la visión por computadora. En los últimos años, la popularidad de la tecnología de aprendizaje profundo ha avanzado en gran medida el desarrollo de la IA de los documentos, como el análisis de diseño de documentos, la extracción de información visual, la respuesta de preguntas visuales de documentos, la clasificación de imágenes de documentos, etc. Este documento revisa brevemente algunos de los modelos representativos, tareas y conjuntos de datos de referencia. Además, también presentamos un análisis de documentos basado en reglas heurístico en la etapa temprana, los algoritmos de aprendizaje automático estadístico y los enfoques de aprendizaje profundo, especialmente los métodos de capacitación previa. Finalmente, buscamos direcciones futuras para la investigación de documentos de IA. Procesamiento automatizado eficiente de los documentos no estructurados utilizando inteligencia artificial: una revisión sistemática de la literatura y futuras direcciones
Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, Ketan Kotecha IEEE Access 2021
Los datos no estructurados afectan el 95% de las organizaciones y les cuesta millones de dólares anualmente. Si se administra bien, puede mejorar significativamente la productividad empresarial. Las técnicas tradicionales de extracción de información son limitadas en su funcionalidad, pero las técnicas basadas en IA pueden proporcionar una mejor solución. Falta una investigación exhaustiva de las técnicas basadas en IA para la extracción automática de información de documentos no estructurados en la literatura. El propósito de esta revisión sistemática de la literatura (SLR) es reconocer y analizar la investigación sobre las técnicas utilizadas para la extracción de información automática de documentos no estructurados y proporcionar instrucciones para futuras investigaciones. Las directrices de SLR propuestas por Kitchenham y Charters se adhirieron para realizar una búsqueda de literatura en varias bases de datos entre 2010 y 2020. Encontramos que: 1. Las técnicas de extracción de información existentes están basadas en plantillas o basadas en reglas, 2. Los métodos existentes carecen de la capacidad de abordar los diseños de documentos complejos en situaciones de tiempo real como los invitados y los órdenes de compra, 3. Los datos disponibles públicamente son de la tarea y de los documentos complejos de baja calidad. Por lo tanto, existe la necesidad de desarrollar un nuevo conjunto de datos que refleje problemas del mundo real. Nuestra SLR descubrió que los enfoques basados en IA tienen un fuerte potencial para extraer información útil de documentos no estructurados automáticamente. Sin embargo, enfrentan ciertos desafíos en el procesamiento de múltiples diseños de los documentos no estructurados. Nuestra SLR presenta la conceptualización de un marco para la construcción de documentos no estructurados de alta calidad. Nuestra SLR también revela la necesidad de una estrecha asociación entre las empresas e investigadores para manejar diversos desafíos del análisis de datos no estructurado.
2020
2018
- Future Paradigms of Automated Processing de documentos comerciales
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
En este documento, resumimos los resultados obtenidos hasta ahora en las comunidades interesadas en el desarrollo de técnicas de procesamiento automatizadas aplicadas a documentos comerciales, e diseñamos algunas evoluciones que exigen la etapa actual de esas técnicas por sí mismas o por avances en el sector colateral. Emerge una imagen clara de un campo que ha puesto un enorme esfuerzo en resolver problemas que cambiaron mucho durante los últimos 30 años, y ahora está evolucionando rápidamente para incorporar el procesamiento de documentos en los sistemas de gestión del flujo de trabajo en un lado e incluir características derivadas de la introducción de tecnologías de computación en la nube en el otro lado. Proponemos un esquema arquitectónico para el procesamiento de documentos comerciales que proviene de las dos líneas de evolución anteriores.
Más viejo
Temas de investigación
- Extracción de información clave (Kie)
- Análisis de diseño de documentos (DLA)
- Respuesta de preguntas de documento (DQA)
- Comprensión de documentos científicos (SDU)
- Recogción de carácter óptico (OCR)
- Relacionado
- General
- Comprensión de datos tabulares (TDC)
- Automatización de procesos robóticos (RPA)
Otros
Recursos
Volver arriba
Conjuntos de datos para modelos de lenguaje previo a la capacitación
- El conjunto de datos RVL -CDIP - DataSet consta de 400,000 imágenes de escala de grises en 16 clases, con 25,000 imágenes por clase
- La Biblioteca de Documentos de la Industria: un portal de millones de documentos creados por industrias que influyen en la salud pública, alojados por la Biblioteca UCSF
- Conjunto de datos de documentos de color: de los sistemas de información sensorial inteligente, Universidad de Amsterdam
- La colección IIT CDIP - DataSet consta de documentos de la demanda de los estados contra la industria del tabaco en la década de 1990, consta de alrededor de 7 millones de documentos
Herramientas de procesamiento de PDF
- Borb: es una biblioteca de Python pura para leer, escribir y manipular documentos PDF. Representa un documento PDF como una datos de datos similares a JSON de listas anidadas, diccionarios y primitivos (números, cadenas, booleanos, etc.).
- Pawls: las anotaciones PDF con etiquetas y estructura es un software que facilita la recopilación de una serie de anotaciones asociadas con un documento PDF
- PDFPlumber: Plumb A PDF para obtener información detallada sobre cada carácter de texto, rectángulo y línea. Además: extracción de mesa y depuración visual
- PDFMiner.six - PDFMiner.six es una bifurcación de la comunidad del PDFMiner original. Es una herramienta para extraer información de los documentos PDF. Se centra en obtener y analizar datos de texto
- Parser de diseño: el analizador de diseño es una herramienta basada en el aprendizaje profundo para las tareas de análisis de diseño de imágenes de documentos
- Tabulo - Extracción de tabla de imágenes
- OCRMYPDF - OCRMYPDF agrega una capa de texto de OCR a los archivos PDF escaneados, lo que permite que se registren o se copian
- PDFBox: la biblioteca Apache PDFBox es una herramienta Java de código abierto para trabajar con documentos PDF. Este proyecto permite la creación de nuevos documentos PDF, la manipulación de documentos existentes y la capacidad de extraer contenido de los documentos
- PDFPIG: este proyecto permite a los usuarios leer y extraer texto y otro contenido de los archivos PDF. Además, la biblioteca se puede utilizar para crear documentos PDF simples que contienen texto y formas geométricas. Este proyecto tiene como objetivo puerto PDFBox a C#
- PARSING-Prickly-PDFS-Recursos y hojas de trabajo para el taller de Nicar 2016 del mismo nombre
- PDF-TEXT-EXTRACTION-Benchmark-PDF Tools Benchmark
- Escáner PDF digital nacido: verifica si PDF nace -digital
- OpenContracta la plataforma de anotación de PDF con licencia de APACHE2 para documentos visualmente ricos que preservan el diseño original y exporta datos posicionales X, y para tokens, así como inicio y detención del tramo. Basado en Pawls, pero con un backend basado en Python y fácilmente desplegable en su máquina local, intranet de la empresa o la web a través de Docker Compose.
- Deepdoctection Deep Pettection es una biblioteca de Python que orquesta la extracción de documentos y las tareas de análisis de diseño de documentos para imágenes y documentos PDF utilizando modelos de aprendizaje profundo. No implementa modelos, pero le permite construir tuberías utilizando bibliotecas altamente reconocidas para la detección de objetos, OCR y tareas de PNL seleccionadas y proporciona un marco integrado para ajustar, evaluar y ejecutar modelos.
- Pydoxtools Pydoxtools es una biblioteca de composición de IA para el análisis DPOcument. Cuenta con un extenso conjunto de herramientas para construir tuberías de análisis de documentos complejos y reconoce la mayoría de los formatos de documentos fuera de la caja. Admite tareas de PNL típicas, como palabras clave, resumen, cuestionamiento de la caja. y presenta un algoritmo de extracción de tabla de memoria de baja calidad de alta calidad y facilita las operaciones de lotes de NLP en un clúster.
Conferencias, talleres
Volver arriba
General / Negocios / Finanzas
- Conferencia Internacional sobre Análisis y Reconocimiento de Documentos (ICDAR) [2021, 2019, 2017]
- Taller sobre inteligencia de documentos (DI) [2021, 2019]
- Taller de procesamiento narrativo financiero (FNP) [2021, 2020, 2019]
- Taller sobre economía y procesamiento del lenguaje natural (ECONLP) [2021, 2019, 2018]
- Taller Internacional sobre Sistemas de Análisis de Documentos (DAS) [2020, 2018, 2016]
- Conferencia Internacional de ACM sobre IA en Finanzas (ICAIF)
- El taller AAAI-21 sobre el descubrimiento de conocimiento de los datos no estructurados en servicios financieros
- Taller de CVPR 2020 sobre texto y documentos en la era del aprendizaje profundo
- Taller KDD sobre aprendizaje automático en finanzas (KDD MLF 2020)
- Finir 2020: El primer taller sobre recuperación de información en finanzas
- Segundo taller de KDD sobre detección de anomalías en finanzas (KDD 2019)
- Conferencia de comprensión de documentos (DUC 2007)
Comprensión de documentos científicos
- El taller AAAI-21 sobre comprensión de documentos científicos (SDU 2021)
- Primer taller sobre procesamiento de documentos académicos (SDProc 2020)
- Taller internacional sobre análisis de documentos científicos (ScidoCA) [2020, 2018, 2017]
Blogs
Volver arriba
- Una encuesta de modelos de comprensión de documentos, 2021
- Extracción de formulario de documento, 2021
- Cómo automatizar procesos con datos no estructurados, 2021
- Una guía completa de OCR con RPA y comprensión de documentos, 2021
- Extracción de información de los recibos con redes convolucionales gráficas, 2021
- Cómo extraer datos estructurados de facturas, 2021
- Extracción de datos estructurados de documentos templáticos, 2020
- Para aplicar la IA para bien, piense en la extracción de forma, 2020
- UIPath Documenting Comprensión de la arquitectura y enfoque de la solución, 2020
- ¿Cómo puedo automatizar la extracción de datos de documentos complejos?, 2020
- LegalTech: Extracción de información en documentos legales, 2020
Soluciones
Volver arriba
Grandes empresas:
- Abby
- Acentuar
- Amazonas
- Google
- Microsoft
- Uipath
Menor:
- Aplicación.ai
- Base64.ai
- Colocar
- Elemento ai
- Indicador
- Impedirse
- Konfuzio
- Metamaze
- Nanonetas
- Rossum
- Silo
Ejemplos
Documentos visualmente ricos
Volver arriba
En VRD, la importancia de la información de diseño es crucial para comprender el documento completo correctamente (este es el caso con casi todos los documentos comerciales). Para los humanos, la información espacial mejora la legibilidad y las velocidades de la comprensión del documento.
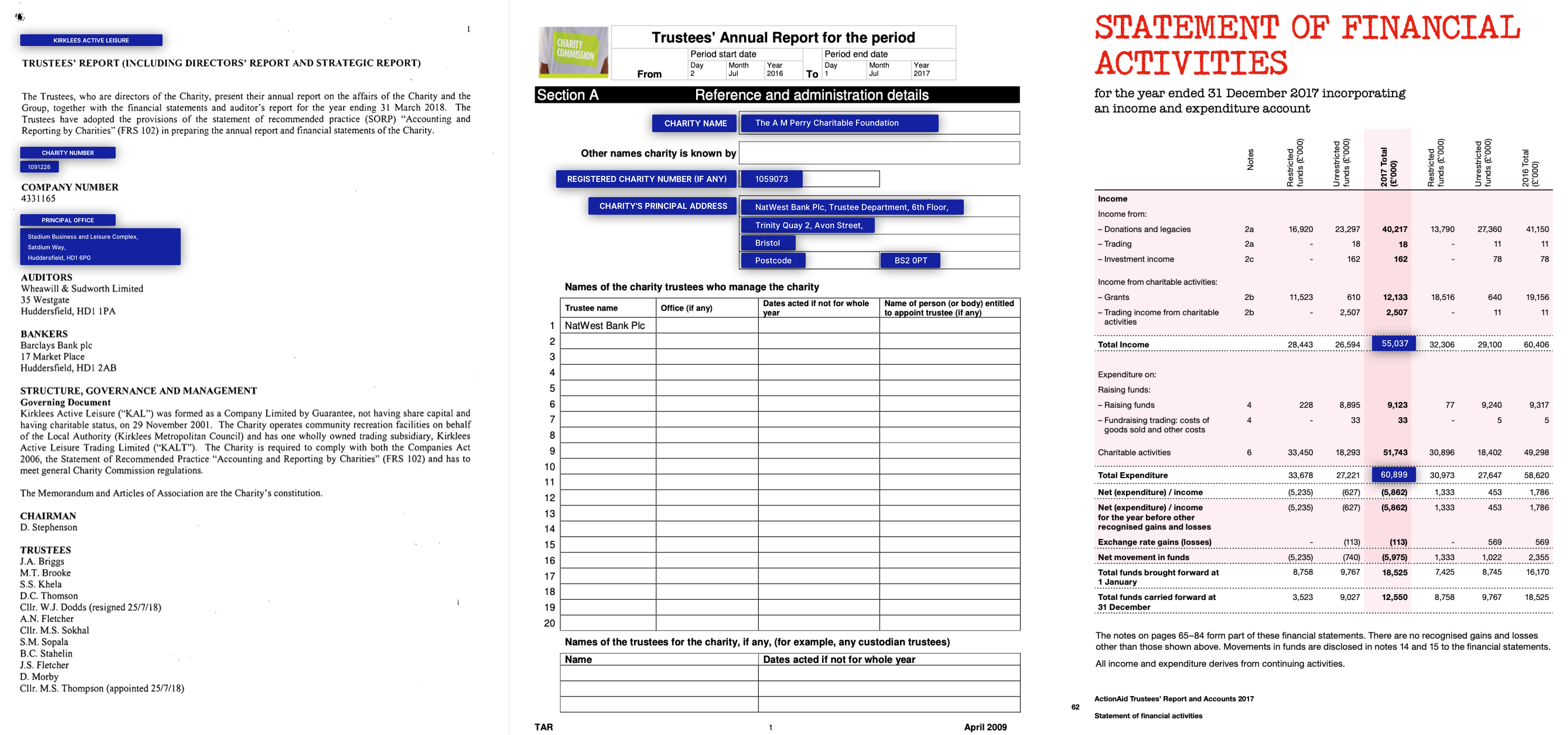
Factura / currículum / anuncio de trabajo

NDA / Informes anuales

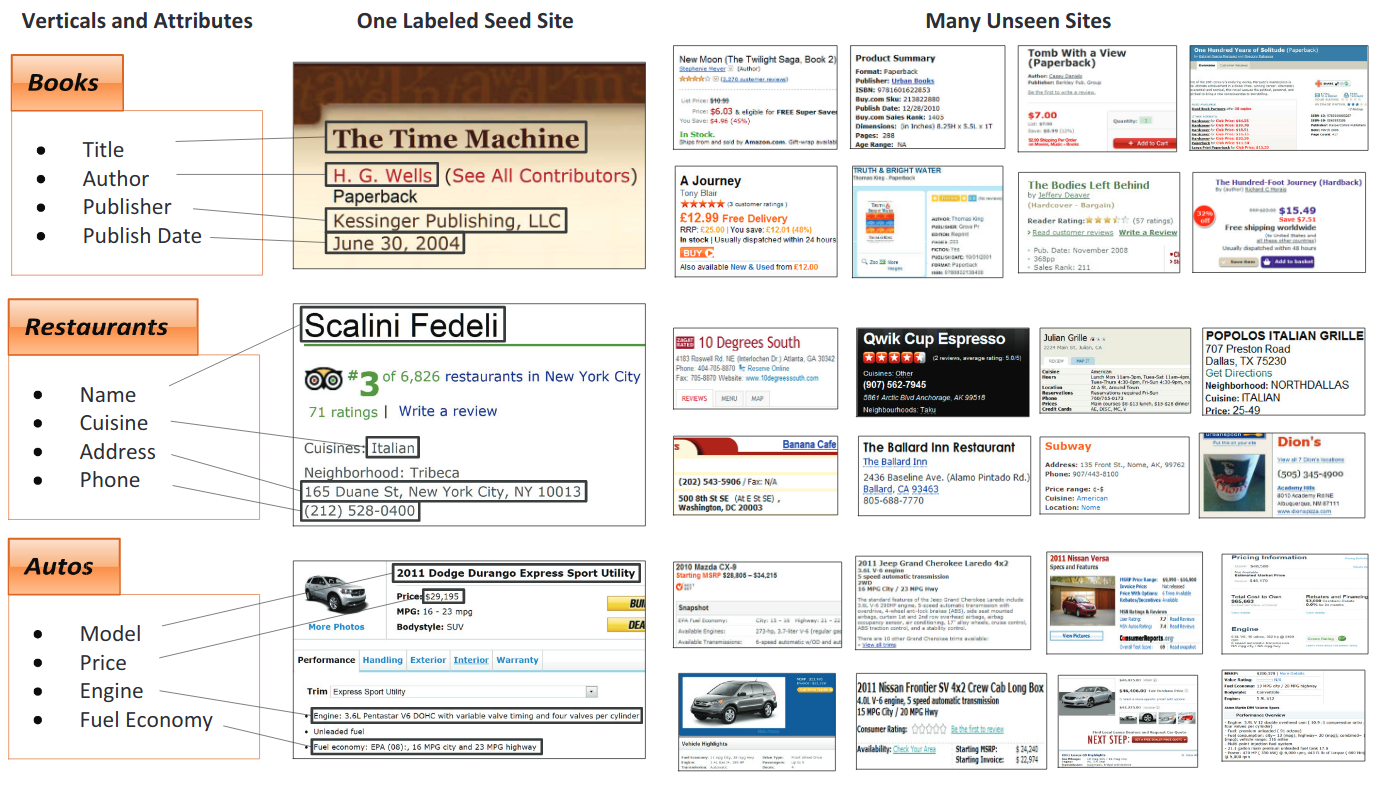
Extracción de información clave
Volver arriba
El objetivo de esta tarea es extraer textos de varios campos clave de una colección dada de documentos que contienen entidades clave similares.
Recibos escaneados
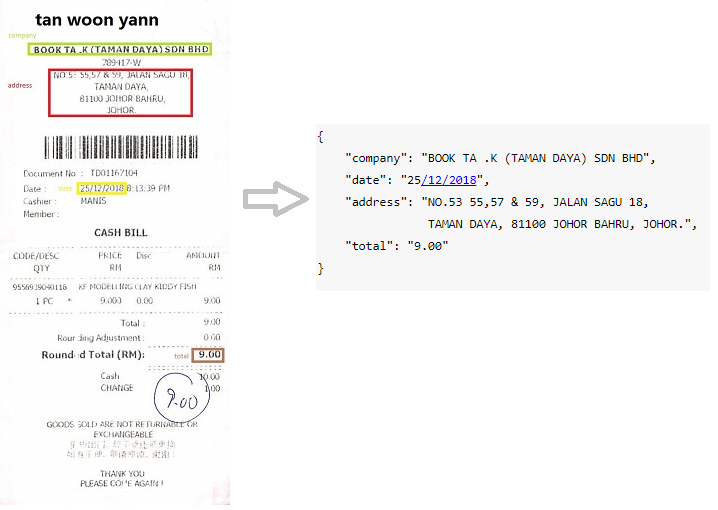
NDA / Informes anuales
Ejemplos de aplicaciones comerciales reales y datos para conjuntos de datos Kleister (las entidades clave están en azul)
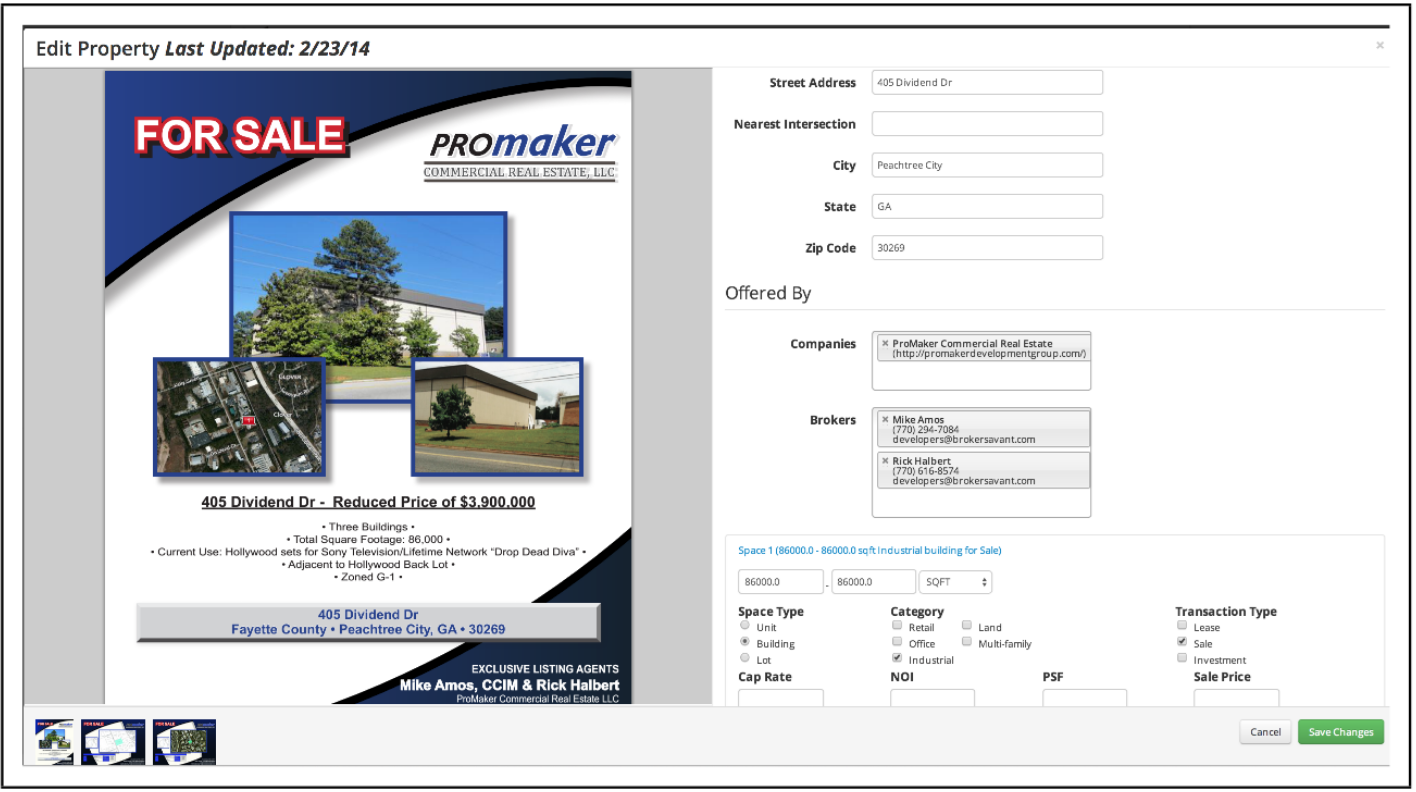
Flyers en línea multimedia
Un ejemplo de un volante de bienes raíces comerciales e ingresó manualmente información de listado © Empaker Commercial Real Estate LLC, © Brokersavant Inc.
Factura de impuestos de valor agregado

Página web
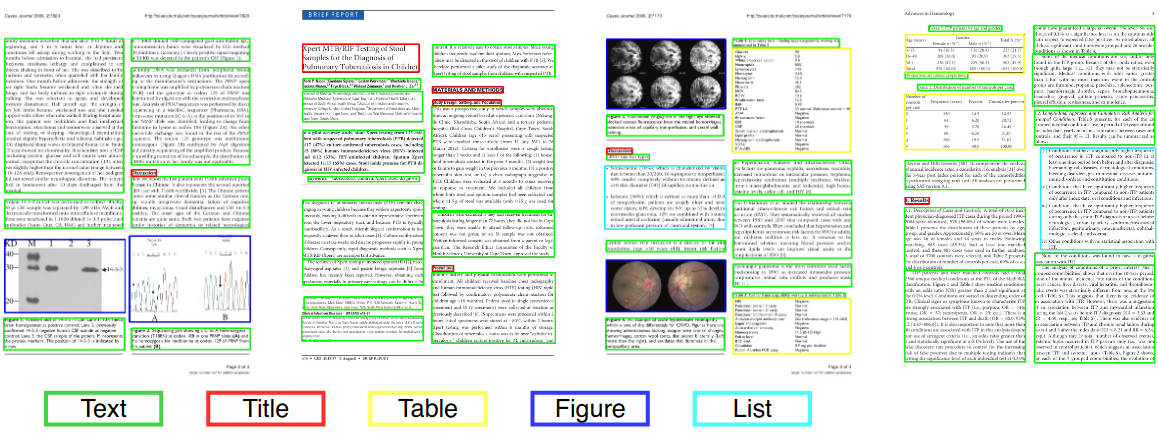
Análisis de diseño de documentos
Volver arriba
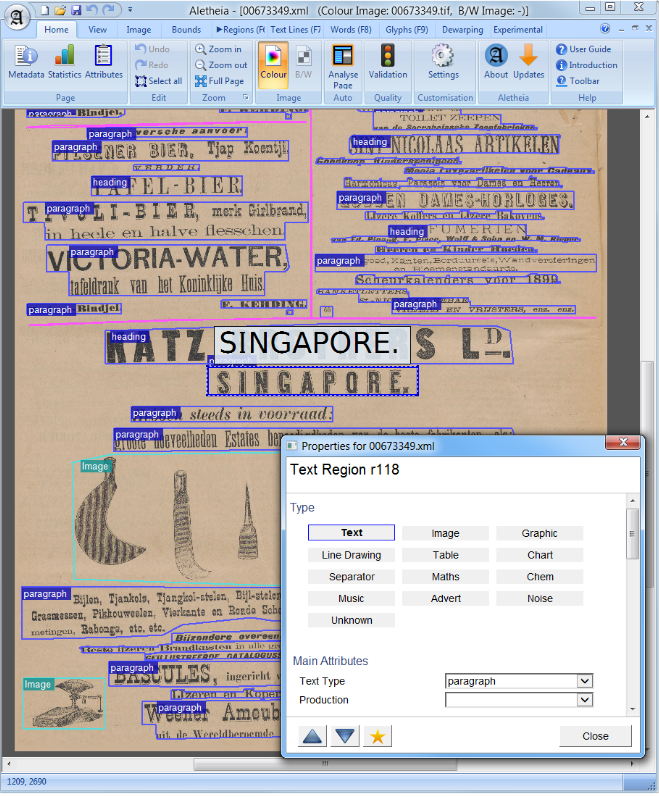
En la visión por computadora o el procesamiento del lenguaje natural, el análisis de diseño de documentos es el proceso de identificación y categorización de las regiones de interés en la imagen escaneada de un documento de texto. Un sistema de lectura requiere la segmentación de zonas de texto de las no textuales y la disposición en su orden de lectura correcto. La detección y el etiquetado de las diferentes zonas (o bloques) como cuerpo de texto, ilustraciones, símbolos matemáticos y tablas integradas en un documento se llama análisis de diseño geométrico. Pero las zonas de texto juegan diferentes roles lógicos dentro del documento (títulos, subtítulos, notas al pie, etc.) y este tipo de etiquetado semántico es el alcance del análisis de diseño lógico. (https://en.wikipedia.org/wiki/Document_Layout_analysis)
Publicación científica

Periódicos históricos
Documentos comerciales
Rojo: Bloque de texto, Azul: Figura.

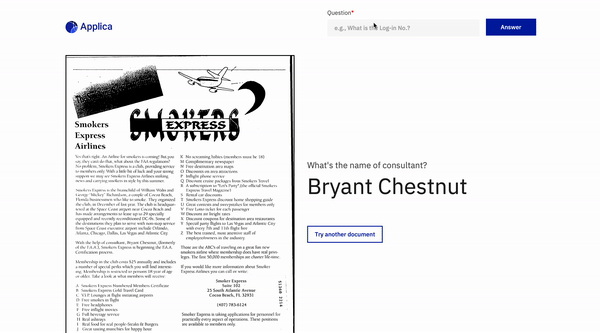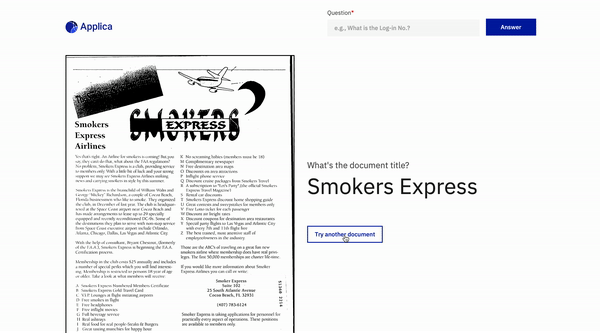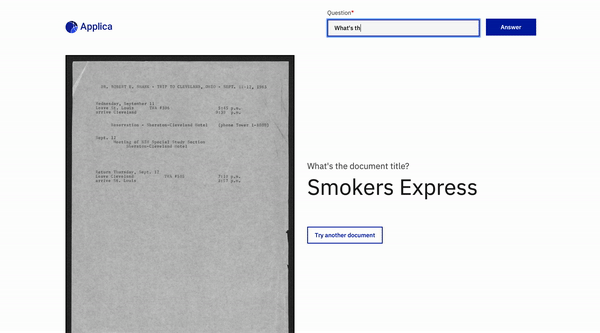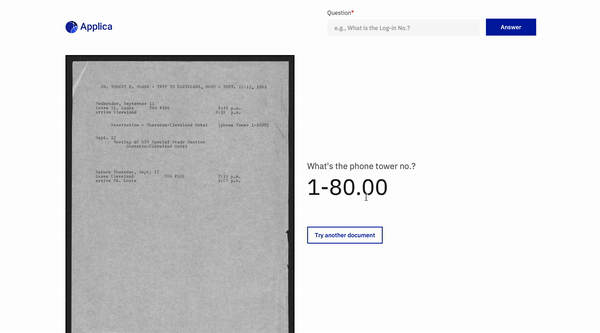
Contestación de preguntas de documento
Volver arriba
Ejemplo de docvqa

Demo del modelo de inclinación
Inspiración
Volver arriba
Dominio
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/DocumentLayoutanalysis
- https://github.com/bikash/documenterstanding
- https://github.com/harpribot/awesome-information-retrieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity--papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
General ai/dl/ml
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


