فهم وثيقة رهيبة
موضوع منسق للموارد لفهم المستندات (DU) المتعلق بمعالجة المستندات الذكية (IDP) ، والذي يعتبر بالنسبة لأتمتة العمليات الآلية (RPA) من البيانات غير المنظمة ، وخاصة المستندات الغنية بصريًا (VRDs).
الملاحظة 1: المواقف الجريئة أكثر أهمية ثم الآخرين.
الملاحظة 2: بسبب حداثة الحقل ، هذه القائمة قيد الإنشاء - المساهمات مرحب بها (شكرًا لك مقدمًا!). يرجى تذكر استخدام الاتفاقية التالية:
- عنوان المنشور / مجموعة البيانات / عنوان المورد ، [رمز / بيانات / موقع]]
قائمة المؤلفين مؤتمر/مجلة اسم سنة
حجم مجموعة البيانات: القطار (لا من الأمثلة) ، ديف (لا من الأمثلة) ، اختبار (لا من الأمثلة) [اختياري لأوراق/موارد مجموعة البيانات] ؛ مجردة/وصف قصير ...
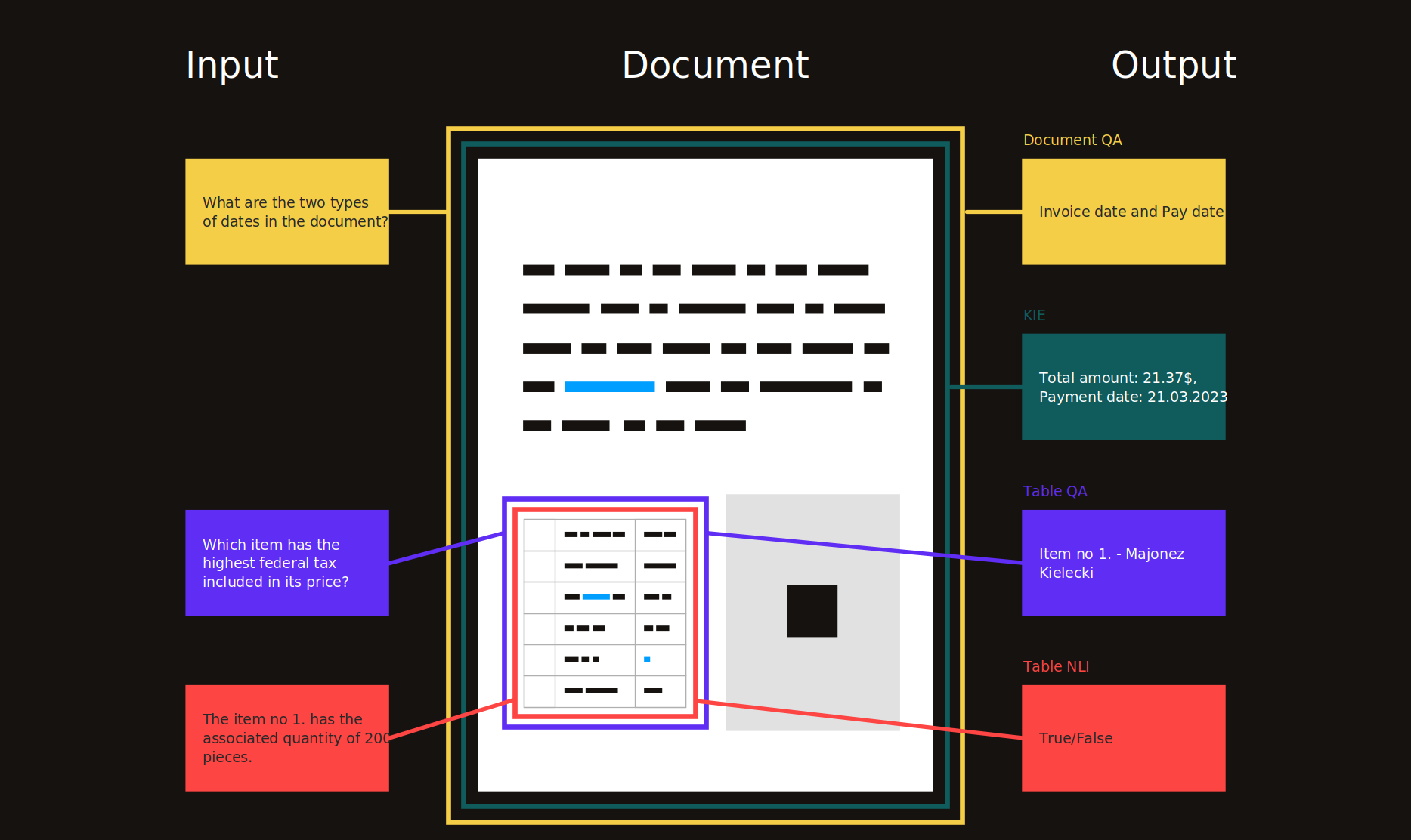
جدول المحتويات
- مقدمة
- موضوعات البحث
- استخراج المعلومات الرئيسية (KIE)
- تحليل تخطيط المستند (DLA)
- إجابة سؤال المستند (DQA)
- فهم الوثائق العلمية (SDU)
- التعرف على الأحرف البصرية (OCR)
- متعلق ب
- عام
- فهم البيانات الجدولية (TDC)
- أتمتة العمليات الآلية (RPA)
- آحرون
- موارد
- مجموعات البيانات لنماذج لغة ما قبل التدريب
- أدوات معالجة PDF
- المؤتمرات / ورش العمل
- المدونات
- الحلول
- أمثلة
- مستندات غنية بصريًا (VRDS)
- استخراج المعلومات الرئيسية (KIE)
- تحليل تخطيط المستند (DLA)
- إجابة سؤال المستند (DQA)
- إلهام
مقدمة
تعد الوثائق جزءًا أساسيًا من العديد من الشركات في العديد من المجالات مثل القانون والتمويل والتكنولوجيا وغيرها. يعد الفهم التلقائي للمستندات مثل الفواتير والعقود والاستئناف مربحًا ، حيث يفتح العديد من الطرق الجديدة للأعمال. شهدت مجالات معالجة اللغة الطبيعية ورؤية الكمبيوتر تقدماً هائلاً من خلال تطوير التعلم العميق بحيث بدأت هذه الأساليب في أن تنطلق في أنظمة فهم الوثائق المعاصرة. مصدر
أوراق
2023
- معيار الانقياد لتوطين معلومات المستند واستخلاصه ، [موقع ويب] [المعيار] [رمز]
štěpán šimsa ، Milan šulc ، Michal Uřičář ، Yash Patel ، أحمد حمدي ، Matěj Kocián ، Matyáš Skalický ، Jiří Matas ، Antoine Doucet ، Mickaël Coustaty ، Dimoshenis Karatzas Arxiv Preprint 2023
تقدم هذه الورقة معيارًا سهل الانقياد مع أكبر مجموعة بيانات من مستندات العمل لمهام توطين المعلومات الرئيسية والتعرف على العناصر. أنه يحتوي على مستندات أعمال مكونة من 6.7 ألف مستندات ، و 10 آلاف مستندات تم إنشاؤها صناعياً ، وحوالي 1 مليون مستندات غير مخصصة للتدريب غير الخاضع للإشراف. تم تصميم مجموعة البيانات بمعرفة الجوانب الخاصة بالمجال والمهمة ، مما أدى إلى الميزات الرئيسية التالية: (1) التعليقات التوضيحية في 55 فئة ، والتي تتجاوز تفاصيل مجموعات بيانات استخراج المعلومات الرئيسية المنشورة مسبقًا بواسطة هامش كبير ؛ (2) يمثل التعرف على العناصر مهمة استخراج معلومات عملية للغاية ، حيث يجب تعيين المعلومات الرئيسية للعناصر في جدول ؛ (3) تأتي المستندات من العديد من التخطيطات ، وتتضمن مجموعة الاختبار حالات صفرية وبعض الطلقات بالإضافة إلى تخطيطات شائعة في مجموعة التدريب. يأتي المعيار مع العديد من خطوط الأساس ، بما في ذلك Roberta و LayoutLMV3 ومحول الجدول المستند إلى DETR. تم تطبيق هذه النماذج الأساسية على كلتا المهمتين من المعيار السهل ، مع مشاركة النتائج في هذه الورقة ، مما يوفر نقطة انطلاق سريعة للعمل في المستقبل. تتوفر مجموعة البيانات وخطوط الأساس في عنوان URL HTTPS هذا.
2022
2021
2020
2018
- النماذج المستقبلية للمعالجة الآلية لمستندات العمل
Matteo Cristania ، Andrea Bertolasob ، Simone Scannapiecoc ، Claudio Tomazzolia International Journal لإدارة المعلومات 2018
في هذه الورقة ، نلخص النتائج التي تم الحصول عليها حتى الآن في المجتمعات المهتمة بتطوير تقنيات المعالجة الآلية كما هو مطبق على وثائق العمل ، ونضع بعض التطورات التي تطلبها المرحلة الحالية من تلك التقنيات بمفردها أو من خلال تطورات القطاع الجانبي. إنه يبرز صورة واضحة للحقل الذي بذل جهدًا هائلاً في حل المشكلات التي تغيرت كثيرًا خلال الثلاثين عامًا الماضية ، وتتطور الآن بسرعة لدمج معالجة المستندات في أنظمة إدارة سير العمل على جانب واحد وتضمين الميزات المستمدة من إدخال تقنيات الحوسبة السحابية على الجانب الآخر. نقترح مخططًا معماريًا لمعالجة وثيقة الأعمال التي تأتي من خطين التطور أعلاه.
أقدم
موضوعات البحث
- استخراج المعلومات الرئيسية (KIE)
- تحليل تخطيط المستند (DLA)
- إجابة سؤال المستند (DQA)
- فهم الوثائق العلمية (SDU)
- استراحة الأحرف البصرية (OCR)
- متعلق ب
- عام
- فهم البيانات الجدولية (TDC)
- أتمتة العمليات الآلية (RPA)
آحرون
موارد
العودة إلى الأعلى
مجموعات البيانات لنماذج لغة ما قبل التدريب
- مجموعة بيانات RVL -CDIP - تتكون مجموعة البيانات من 400000 صورة رمادية في 16 فئة ، مع 25000 صورة لكل فصل
- مكتبة وثائق الصناعة - بوابة لملايين الوثائق التي أنشأتها الصناعات التي تؤثر على الصحة العامة ، التي تستضيفها مكتبة UCSF
- مجموعة بيانات مستندات الألوان - من أنظمة المعلومات الحسية الذكية ، جامعة أمستردام
- تتكون مجموعة بيانات IIT CDIP - من مستندات من دعوى قضائية ضد صناعة التبغ في التسعينيات ، وتتألف من حوالي 7 ملايين وثيقة
أدوات معالجة PDF
- BORB - هي مكتبة Python نقية لقراءة وثائق PDF والتعامل معها. إنه يمثل وثيقة PDF باعتبارها بنية بيانات تشبه JSON من القوائم المتداخلة ، والقواميس والكرات الأولية (الأرقام ، والسلسلة ، والملاءات ، إلخ).
- Pawls - تعليقات التعليقات المتعددة PDF مع الملصقات والبنية هي البرامج التي تجعل من السهل جمع سلسلة من التعليقات التوضيحية المرتبطة بوثيقة PDF
- pdfplumber - plumb a pdf للحصول على معلومات مفصلة حول كل حرف نص ، مستطيل ، وخط. بالإضافة إلى: استخراج الجدول وتصحيح الأخطاء البصرية
- pdfminer.six - pdfminer.six هو شوكة مجتمعية محفوظة من pdfminer الأصلي. إنها أداة لاستخراج المعلومات من مستندات PDF. إنه يركز على الحصول على بيانات النص وتحليله
- تخطيط محلل - محلل التخطيط هو أداة تعليمية عميقة لمهام تحليل تخطيط صورة المستند
- Tabulo - استخراج الجدول من الصور
- OCRMYPDF - يضيف OCRMYPDF طبقة نص OCR إلى ملفات PDF ممسوحة ضوئيًا ، مما يسمح للبحث عنها أو نسخها
- PDFBox - مكتبة Apache PDFBox هي أداة Java مفتوحة المصدر للعمل مع مستندات PDF. يسمح هذا المشروع بإنشاء مستندات PDF جديدة ، ومعالجة المستندات الحالية والقدرة على استخراج المحتوى من المستندات
- PDFPIG - يتيح هذا المشروع للمستخدمين قراءة واستخراج النص والمحتوى الآخر من ملفات PDF. بالإضافة إلى ذلك ، يمكن استخدام المكتبة لإنشاء مستندات PDF بسيطة تحتوي على نص وأشكال هندسية. يهدف هذا المشروع إلى منفذ PDFBox إلى C#
- تحليل PDFS-الموارد وورشة العمل لورشة عمل Nicar 2016 التي تحمل نفس الاسم
- pdf-text-extraction-bickmark-مؤشر أدوات PDF
- المولود الرقمي PDF الماسح الضوئي - التحقق مما إذا كان PDF من مواليد الرقمية
- منصة OpenContracts APACH2 المرخصة ، PDF للشرح للوثائق الغنية بصريًا والتي تحافظ على التصميم الأصلي وتصدير البيانات الموضعية X ، Y للرموز المميزة وكذلك بدء الممتدة وتتوقف. استنادًا إلى Pawls ، ولكن مع وجود خلفية قائم على Python ونشرها بسهولة على جهازك المحلي ، أو الشركة الداخلية أو الويب عبر Docker Compose.
- DeepDoctection Deep Doctection هي مكتبة Python تقوم بتنظيم مهام استخراج المستندات وتخطيط المستندات للصور ومستندات PDF باستخدام نماذج التعلم العميقة. إنه لا ينفذ النماذج ولكنه يمكّنك من إنشاء خطوط أنابيب باستخدام مكتبات معترف بها للغاية للكشف عن الكائنات ، و OCR ومهام NLP المحددة وتوفر إطارًا متكاملًا للضبط وتقييم وتقييم النماذج.
- PyDoxtools PyDoxtools هي مكتبة تكوين AI لتحليل DPOCUMITY. إنه يتميز بمجموعة أدوات واسعة لبناء خطوط أنابيب تحليل المستندات المعقدة ويتعرف على معظم تنسيقات المستندات خارج الصندوق. وهو يدعم مهام NLP النموذجية مثل الكلمات الرئيسية ، والتلخيص ، Question_answering خارج الصندوق. ويتميز بخوارزمية استخراج جدول ذاكرة عالية الجودة CPU/الذاكرة وتجعل عمليات دفع NLP سهلة.
المؤتمرات ، ورش العمل
العودة إلى الأعلى
عام / عمل / مالي
- المؤتمر الدولي حول تحليل الوثائق والاعتراف (ICDAR) [2021 ، 2019 ، 2017]
- ورشة عمل حول استخبارات الوثيقة (DI) [2021 ، 2019]
- ورشة معالجة السرد المالي (FNP) [2021 ، 2020 ، 2019]
- ورشة عمل حول الاقتصاد ومعالجة اللغة الطبيعية (ECONLP) [2021 ، 2019 ، 2018]
- ورشة عمل دولية حول أنظمة تحليل المستندات (DAS) [2020 ، 2018 ، 2016]
- مؤتمر ACM الدولي عن الذكاء الاصطناعى في المالية (ICAIF)
- ورشة عمل AAAI-21 حول اكتشاف المعرفة من البيانات غير المهيكلة في الخدمات المالية
- ورشة عمل CVPR 2020 حول النص والوثائق في عصر التعلم العميق
- ورشة عمل KDD حول التعلم الآلي في التمويل (KDD MLF 2020)
- Finir 2020: ورشة العمل الأولى حول استرجاع المعلومات في التمويل
- ورشة KDD الثانية حول اكتشاف الشذوذ في التمويل (KDD 2019)
- مؤتمر فهم الوثيقة (DUC 2007)
فهم الوثائق العلمية
- ورشة عمل AAAI-21 حول فهم الوثائق العلمية (SDU 2021)
- ورشة العمل الأولى حول معالجة الوثائق العلمية (SDPROC 2020)
- ورشة عمل دولية حول تحليل الوثائق العلمية (SCIDOCA) [2020 ، 2018 ، 2017]
المدونات
العودة إلى الأعلى
- مسح لنماذج فهم الوثائق ، 2021
- استخراج نموذج المستند ، 2021
- كيفية أتمتة العمليات مع البيانات غير المهيكلة ، 2021
- دليل شامل لـ OCR مع RPA وفهم الوثيقة ، 2021
- استخراج المعلومات من الإيصالات مع الشبكات التلافيفية الرسم البياني ، 2021
- كيفية استخراج البيانات المنظمة من الفواتير ، 2021
- استخراج البيانات المنظمة من المستندات المعمارية ، 2020
- لتطبيق الذكاء الاصطناعى للخير ، فكر في استخراج النموذج ، 2020
- UIPATH DOVINE DOTUDATION Artans Architecture Solution Architecture ، 2020
- كيف يمكنني أتمتة استخراج البيانات من المستندات المعقدة؟ ، 2020
- LegalTech: استخراج المعلومات في الوثائق القانونية ، 2020
الحلول
العودة إلى الأعلى
الشركات الكبرى:
- آبي
- لهجة
- أمازون
- جوجل
- Microsoft
- Uipath
الأصغر:
- applica.ai
- BASE64.AI
- Docstack
- العنصر الذكاء الاصطناعي
- indico
- Instabase
- Konfuzio
- metamaze
- nanonets
- روسوم
- صومعة
أمثلة
وثائق غنية بصري
العودة إلى الأعلى
في VRDs ، تعد أهمية معلومات التخطيط أمرًا بالغ الأهمية لفهم الوثيقة بأكملها بشكل صحيح (هذا هو الحال مع جميع مستندات العمل تقريبًا). للبشر المعلومات المكانية يحسن قابلية القراءة والسرعة فهم الوثائق.
فاتورة / استئناف / إعلان وظيفة

NDA / التقارير السنوية

استخراج المعلومات الرئيسية
العودة إلى الأعلى
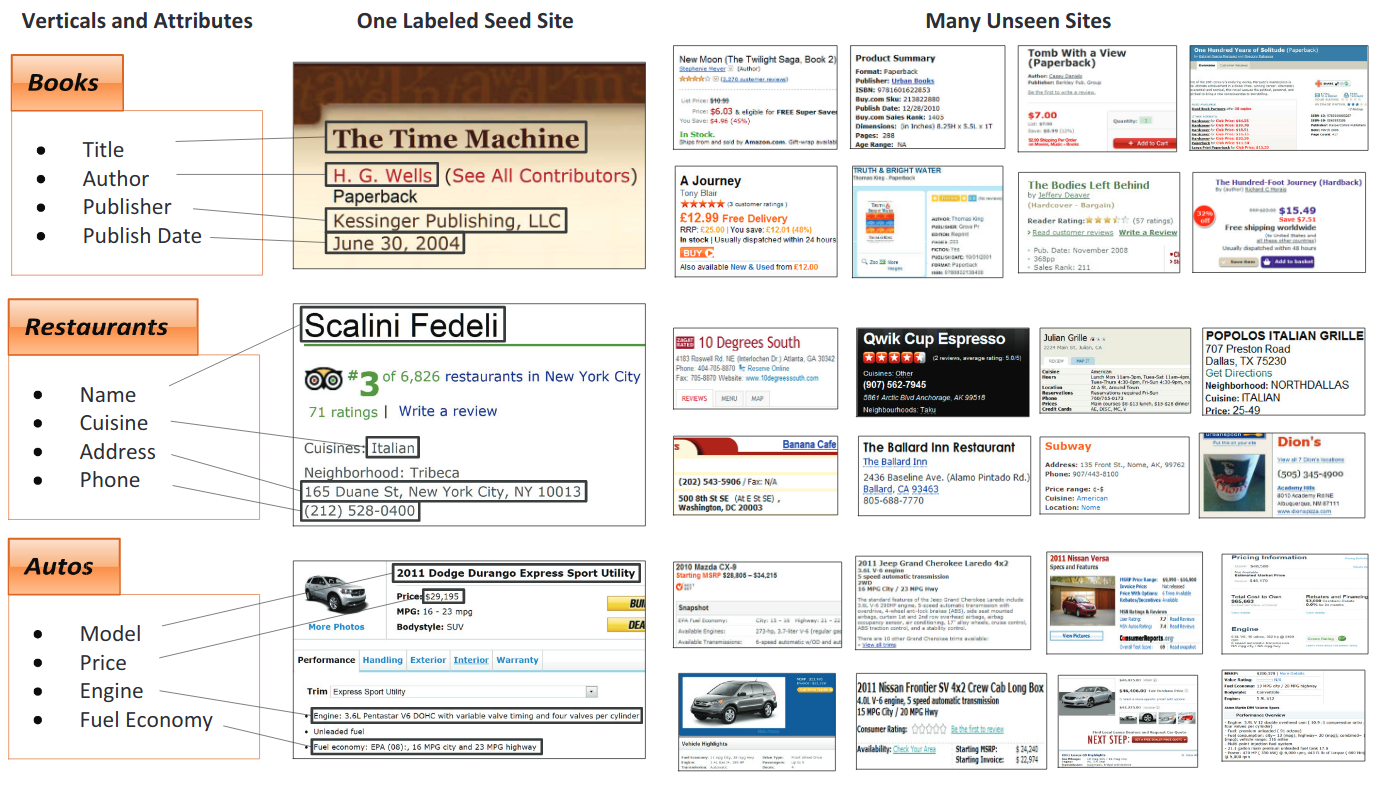
الهدف من هذه المهمة هو استخراج النصوص لعدد من الحقول الرئيسية من مجموعة معينة من المستندات التي تحتوي على كيانات رئيسية مماثلة.
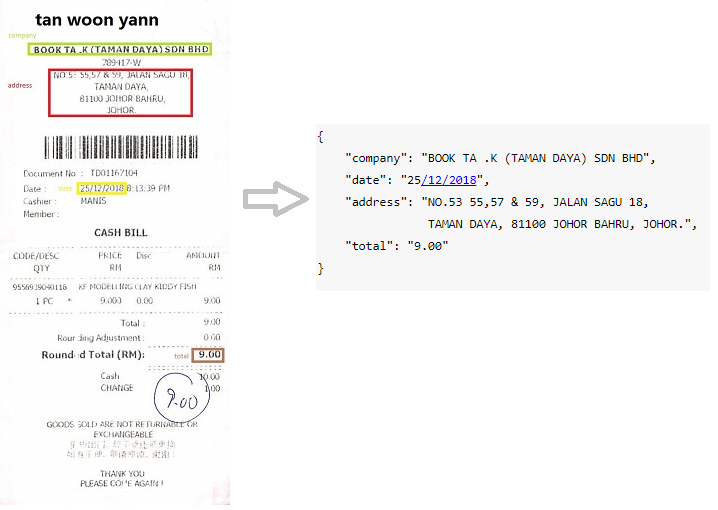
إيصالات ممسوحة ضوئيا
NDA / التقارير السنوية
أمثلة على تطبيقات الأعمال الحقيقية وبيانات مجموعات بيانات Kleister (الكيانات الرئيسية باللون الأزرق)
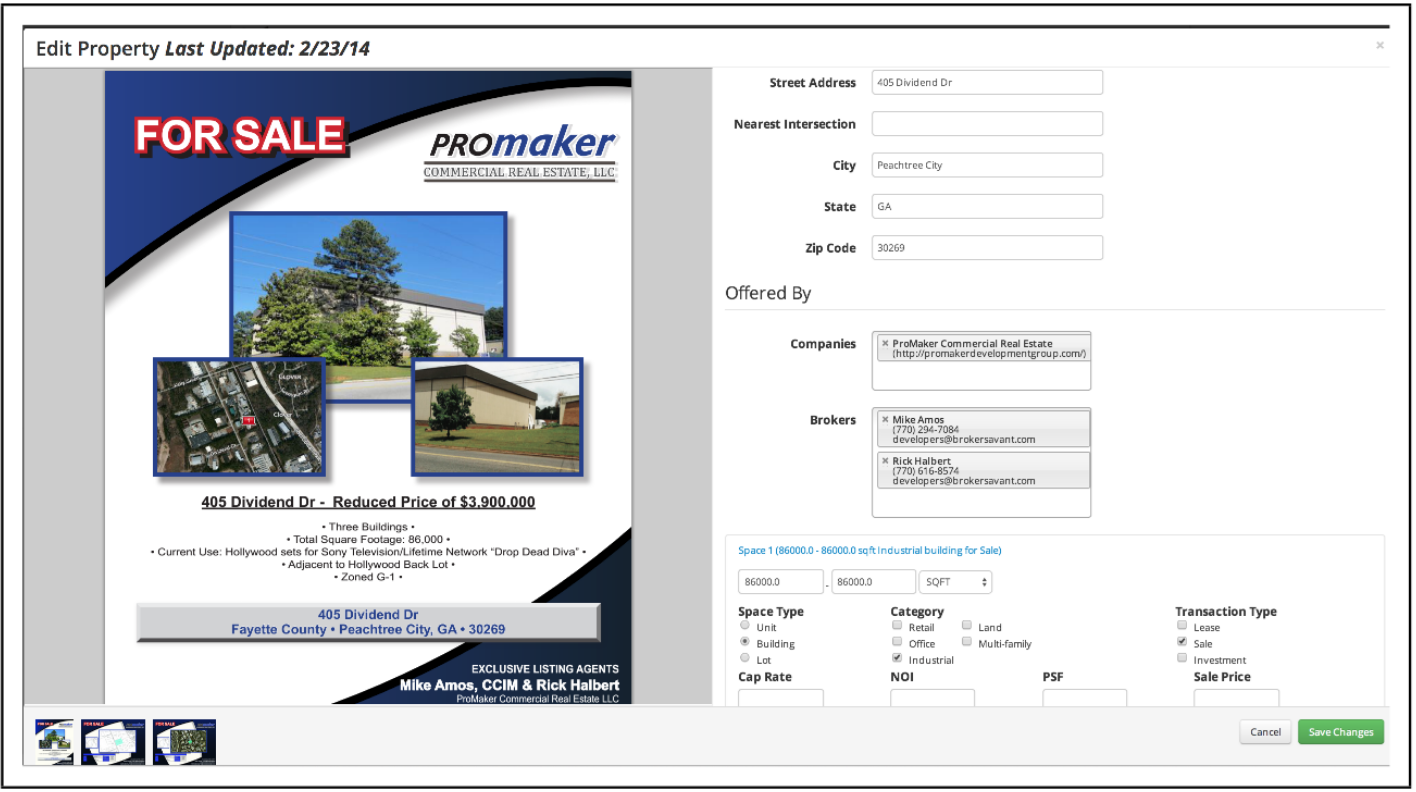
الوسائط المتعددة على الانترنت النشرات
مثال على نشرة عقارية تجارية وإدخال معلومات قائمة يدويًا © Promaker Commercial Real Estate LLC ، © Brokersavant Inc.
فاتورة ضريبية ذات قيمة مضافة

صفحات الويب
تحليل تخطيط المستند
العودة إلى الأعلى
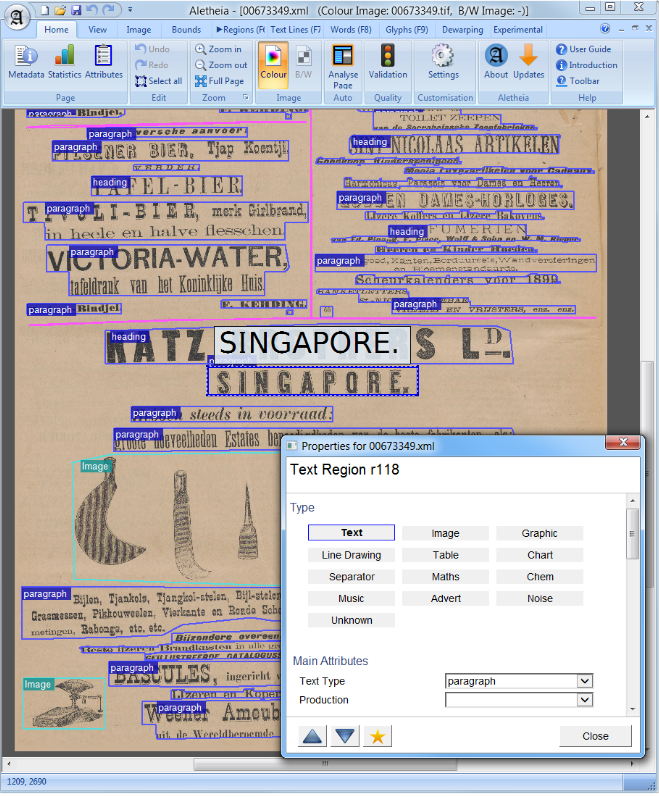
في رؤية الكمبيوتر أو معالجة اللغة الطبيعية ، يعد تحليل تخطيط المستندات عملية تحديد وتصنيف مناطق الاهتمام في الصورة الممسوحة ضوئيًا لمستند نصي. يتطلب نظام القراءة تجزئة المناطق النصية من تلك غير النصية والترتيب في ترتيب القراءة الصحيح. يسمى الكشف عن المناطق المختلفة (أو الكتل) كجسم نص ، والرسوم التوضيحية ، ورموز الرياضيات ، والجداول المضمنة في مستند تحليل التصميم الهندسي. لكن المناطق النصية تلعب أدوارًا منطقية مختلفة داخل المستند (العناوين ، التسميات التوضيحية ، الحواشي ، إلخ) وهذا النوع من العلامات الدلالية هو نطاق تحليل التصميم المنطقي. (https://en.wikipedia.org/wiki/document_layout_analysis)
النشر العلمي
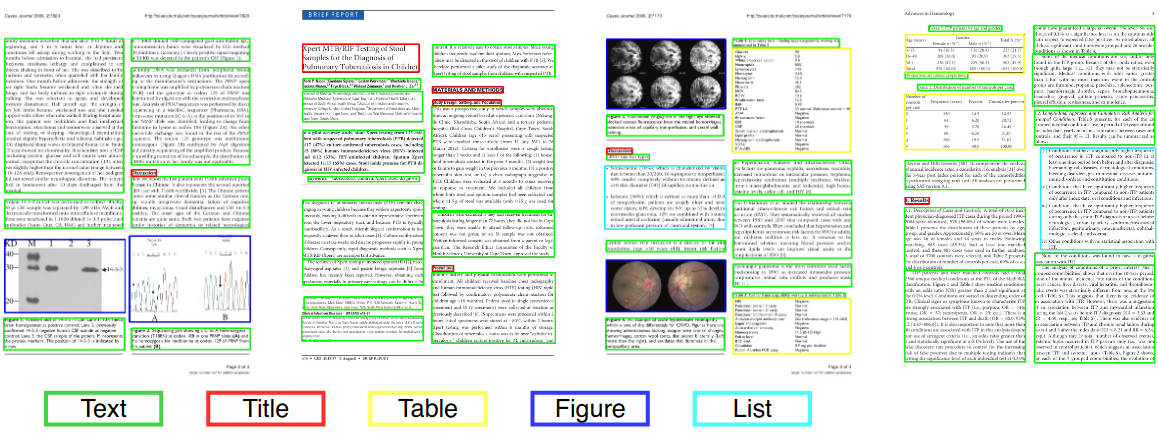

الصحف التاريخية
وثائق العمل
الأحمر: كتلة النص ، الأزرق: الشكل.

إجابة سؤال المستند
العودة إلى الأعلى
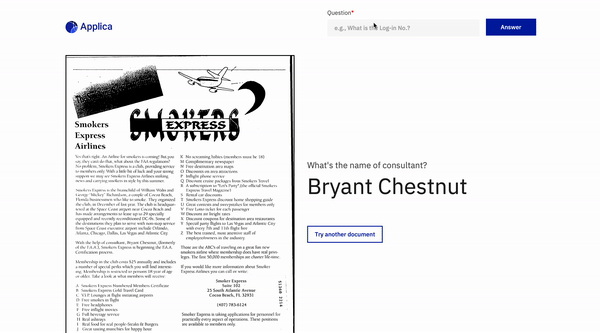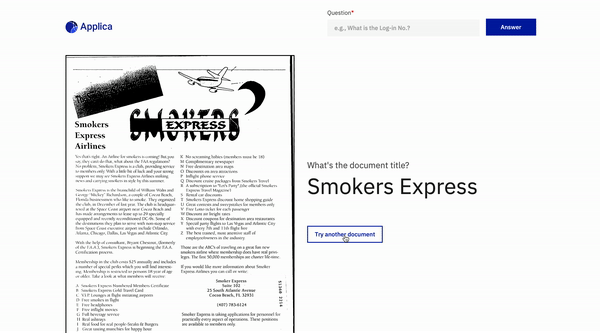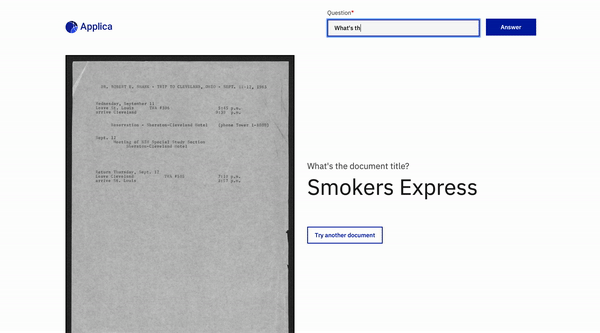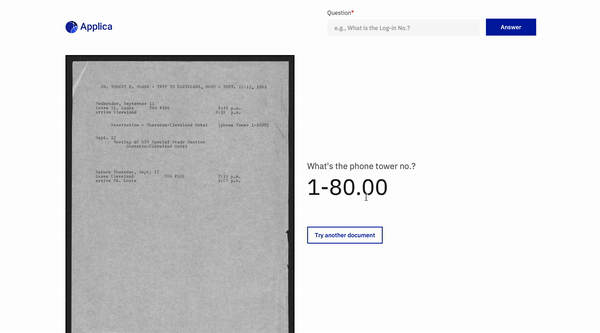
مثال DOCVQA

إمالة نموذج العرض التوضيحي
إلهام
العودة إلى الأعلى
اِختِصاص
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentlayoutanalysis
- https://github.com/bikash/documentUndSting
- https://github.com/harpribot/awesome-information-retrival
- https://github.com/roomylee/awesome-reelation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity-relelling-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
عام الذكاء الاصطناعي/دل/مل
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


