ความเข้าใจเอกสารที่ยอดเยี่ยม
รายการทรัพยากรที่ได้รับการดูแลเพื่อการทำความเข้าใจเอกสาร (DU) ที่เกี่ยวข้องกับการประมวลผลเอกสารอัจฉริยะ (IDP) ซึ่งสัมพันธ์กับกระบวนการอัตโนมัติของกระบวนการหุ่นยนต์ (RPA) จากข้อมูลที่ไม่มีโครงสร้างโดยเฉพาะอย่างยิ่งรูปแบบเอกสารที่หลากหลาย (VRDs)
หมายเหตุ 1: ตำแหน่งที่เป็นตัวหนามีความสำคัญมากกว่าคนอื่น ๆ
หมายเหตุ 2: เนื่องจากความแปลกใหม่ของสนามรายการนี้อยู่ระหว่างการก่อสร้าง - ยินดีต้อนรับการมีส่วนร่วม (ขอบคุณล่วงหน้า!) โปรดอย่าลืมใช้การประชุมต่อไปนี้:
- ชื่อเรื่องของสิ่งพิมพ์ / ชุดข้อมูล / ทรัพยากรชื่อ [รหัส / ข้อมูล / เว็บไซต์]
รายชื่อผู้เขียน การประชุม/ชื่อวารสาร ปี
ชุดข้อมูลขนาด: รถไฟ (ไม่มีตัวอย่าง), dev (ไม่มีตัวอย่าง), การทดสอบ (ไม่มีตัวอย่าง) [ไม่บังคับสำหรับเอกสาร/ทรัพยากรชุดข้อมูล]; บทคัดย่อ/คำอธิบายสั้น ๆ ...
สารบัญ
- การแนะนำ
- หัวข้อการวิจัย
- การสกัดข้อมูลสำคัญ (KIE)
- การวิเคราะห์เค้าโครงเอกสาร (DLA)
- การตอบคำถามเอกสาร (DQA)
- ความเข้าใจในเอกสารทางวิทยาศาสตร์ (SDU)
- การจดจำอักขระออพติคอล (OCR)
- ที่เกี่ยวข้อง
- ทั่วไป
- ความเข้าใจข้อมูลแบบตาราง (TDC)
- กระบวนการอัตโนมัติของหุ่นยนต์ (RPA)
- คนอื่น
- ทรัพยากร
- ชุดข้อมูลสำหรับแบบจำลองภาษาก่อนการฝึกอบรม
- เครื่องมือประมวลผล PDF
- การประชุม / การประชุมเชิงปฏิบัติการ
- บล็อก
- การแก้ปัญหา
- ตัวอย่าง
- เอกสารที่หลากหลายทางสายตา (VRDs)
- การสกัดข้อมูลสำคัญ (KIE)
- การวิเคราะห์เค้าโครงเอกสาร (DLA)
- การตอบคำถามเอกสาร (DQA)
- แรงบันดาลใจ
การแนะนำ
เอกสารเป็นส่วนสำคัญของธุรกิจจำนวนมากในหลายสาขาเช่นกฎหมายการเงินและเทคโนโลยีอื่น ๆ ความเข้าใจอัตโนมัติของเอกสารเช่นใบแจ้งหนี้สัญญาและการดำเนินการต่อเป็นสิ่งที่มีกำไรเปิดช่องทางธุรกิจใหม่ ๆ มากมาย สาขาการประมวลผลภาษาธรรมชาติและการมองเห็นคอมพิวเตอร์ได้เห็นความก้าวหน้าอย่างมากผ่านการพัฒนาของการเรียนรู้อย่างลึกซึ้งเช่นวิธีการเหล่านี้เริ่มกลายเป็น infused ในระบบทำความเข้าใจเอกสารร่วมสมัย แหล่งที่มา
เอกสาร
2023
- มาตรฐานที่น่าเชื่อถือสำหรับการแปลข้อมูลและการแยกข้อมูลเอกสาร [เว็บไซต์] [มาตรฐาน] [รหัส]
Štěpánšimsa, Milan Šulc, Michal Uřičář, Yash Patel, Ahmed Hamdi, MatějKocián, MatyášSkalický, Jiří Matas, Antoine Doucet, Mickaël Coustaty, DiMosthenis karatzas
บทความนี้แนะนำเกณฑ์มาตรฐานที่เชื่องด้วยชุดข้อมูลที่ใหญ่ที่สุดของเอกสารทางธุรกิจสำหรับงานของการแปลข้อมูลที่สำคัญและการสกัดและการจดจำรายการโฆษณา มันมีเอกสารทางธุรกิจที่มีคำอธิบายประกอบ 6.7k, เอกสารที่สร้างขึ้น 100k ซึ่งเป็นเอกสารที่ถูกสังเคราะห์ 100k และเอกสารที่ไม่มีป้ายกำกับเกือบ 1m สำหรับการฝึกอบรมล่วงหน้าที่ไม่ได้รับการดูแล ชุดข้อมูลถูกสร้างขึ้นด้วยความรู้เกี่ยวกับแง่มุมของโดเมนและงานเฉพาะส่งผลให้คุณลักษณะสำคัญดังต่อไปนี้: (i) คำอธิบายประกอบใน 55 คลาสซึ่งเกินความละเอียดของชุดข้อมูลการดึงข้อมูลสำคัญที่เผยแพร่ก่อนหน้านี้ (ii) การจดจำรายการโฆษณาแสดงถึงงานการสกัดข้อมูลที่มีประโยชน์สูงซึ่งจะต้องกำหนดข้อมูลสำคัญให้กับรายการในตาราง (iii) เอกสารมาจากเลย์เอาต์จำนวนมากและชุดทดสอบรวมถึงกรณีศูนย์และไม่กี่กรณีรวมถึงเลย์เอาต์ที่เห็นได้ทั่วไปในชุดการฝึกอบรม เกณฑ์มาตรฐานมาพร้อมกับเส้นเขตแดนหลายแห่งรวมถึง Roberta, Layoutlmv3 และ Twall Table Table Table ที่ใช้ DETR โมเดลพื้นฐานเหล่านี้ถูกนำไปใช้กับงานทั้งสองของเกณฑ์มาตรฐานที่เชื่องโดยมีผลลัพธ์ที่ใช้ร่วมกันในบทความนี้ซึ่งเป็นจุดเริ่มต้นที่รวดเร็วสำหรับการทำงานในอนาคต ชุดข้อมูลและ baselines มีอยู่ที่ URL HTTPS นี้
2022
2021
2020
2018
- กระบวนทัศน์ในอนาคตของการประมวลผลเอกสารทางธุรกิจอัตโนมัติ
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
ในบทความนี้เราสรุปผลลัพธ์ที่ได้รับในชุมชนที่สนใจในการพัฒนาเทคนิคการประมวลผลอัตโนมัติที่ใช้กับเอกสารทางธุรกิจและกำหนดการวิวัฒนาการบางอย่างที่เรียกร้องโดยขั้นตอนปัจจุบันของเทคนิคเหล่านั้นด้วยตนเองหรือโดยภาคความก้าวหน้าของหลักประกัน มันปรากฏภาพที่ชัดเจนของสนามที่ใช้ความพยายามอย่างมากในการแก้ปัญหาที่เปลี่ยนแปลงไปมากในช่วง 30 ปีที่ผ่านมาและตอนนี้มีการพัฒนาอย่างรวดเร็วเพื่อรวมการประมวลผลเอกสารเข้ากับระบบการจัดการเวิร์กโฟลว์ในด้านหนึ่งและรวมถึงคุณสมบัติที่ได้จากการแนะนำเทคโนโลยีคลาวด์คอมพิว เราเสนอสคีมาสถาปัตยกรรมสำหรับการประมวลผลเอกสารทางธุรกิจที่มาจากสองสายวิวัฒนาการข้างต้น
เก่าแก่กว่า
หัวข้อการวิจัย
- การสกัดข้อมูลสำคัญ (KIE)
- การวิเคราะห์เค้าโครงเอกสาร (DLA)
- การตอบคำถามเอกสาร (DQA)
- ความเข้าใจในเอกสารทางวิทยาศาสตร์ (SDU)
- การ recogtion อักขระออพติคอล (OCR)
- ที่เกี่ยวข้อง
- ทั่วไป
- ความเข้าใจข้อมูลแบบตาราง (TDC)
- กระบวนการอัตโนมัติของหุ่นยนต์ (RPA)
คนอื่น
ทรัพยากร
กลับไปด้านบน
ชุดข้อมูลสำหรับแบบจำลองภาษาก่อนการฝึกอบรม
- ชุดข้อมูล RVL -CDIP - ชุดข้อมูลประกอบด้วยภาพสีเทา 400,000 ภาพใน 16 คลาสโดยมี 25,000 ภาพต่อชั้นเรียน
- ห้องสมุดเอกสารอุตสาหกรรม - พอร์ทัลไปยังเอกสารนับล้านที่สร้างขึ้นโดยอุตสาหกรรมที่มีอิทธิพลต่อสุขภาพของประชาชนซึ่งจัดทำโดยห้องสมุด UCSF
- ชุดข้อมูลเอกสารสี - จากระบบข้อมูลทางประสาทสัมผัสอัจฉริยะมหาวิทยาลัยอัมสเตอร์ดัม
- คอลเลกชัน IIT CDIP - ชุดข้อมูลประกอบด้วยเอกสารจากคดีของรัฐต่ออุตสาหกรรมยาสูบในปี 1990 ประกอบด้วยเอกสารประมาณ 7 ล้านเอกสาร
เครื่องมือประมวลผล PDF
- BORB - เป็นไลบรารี Python บริสุทธิ์ที่จะอ่านเขียนและจัดการเอกสาร PDF มันแสดงถึงเอกสาร PDF เป็นโครงสร้างที่คล้ายกับ JSON ของรายการซ้อนพจนานุกรมและดั้งเดิม (ตัวเลข, สตริง, บูลีน, ฯลฯ )
- Pawls - คำอธิบายประกอบ PDF พร้อมป้ายกำกับและโครงสร้างเป็นซอฟต์แวร์ที่ทำให้ง่ายต่อการรวบรวมชุดคำอธิบายประกอบที่เกี่ยวข้องกับเอกสาร PDF
- PDFPlumber - PLUMB A PDF สำหรับข้อมูลโดยละเอียดเกี่ยวกับตัวละครข้อความแต่ละรูปสี่เหลี่ยมและเส้น บวก: การสกัดตารางและการดีบักภาพ
- pdfminer.six - pdfminer.six เป็นชุมชนที่ได้รับการดูแลเป็นส้อมของ pdfminer ดั้งเดิม มันเป็นเครื่องมือสำหรับการแยกข้อมูลจากเอกสาร PDF มุ่งเน้นไปที่การรับและวิเคราะห์ข้อมูลข้อความ
- ตัวแยกวิเคราะห์เค้าโครง - ตัวแยกวิเคราะห์เค้า
- Tabulo - การสกัดตารางจากภาพ
- OCRMYPDF - OCRMYPDF เพิ่มเลเยอร์ข้อความ OCR ลงในไฟล์ PDF ที่สแกนทำให้สามารถค้นหาหรือคัดลอกได้
- PDFBox - Apache PDFBox Library เป็นเครื่องมือ Java โอเพนซอร์ซสำหรับการทำงานกับเอกสาร PDF โครงการนี้อนุญาตให้สร้างเอกสาร PDF ใหม่การจัดการเอกสารที่มีอยู่และความสามารถในการแยกเนื้อหาจากเอกสาร
- PDFPIG - โครงการนี้อนุญาตให้ผู้ใช้อ่านและแยกข้อความและเนื้อหาอื่น ๆ จากไฟล์ PDF นอกจากนี้ห้องสมุดสามารถใช้ในการสร้างเอกสาร PDF ง่าย ๆ ที่มีข้อความและรูปทรงเรขาคณิต โครงการนี้มีจุดมุ่งหมายไปยังพอร์ต pdfbox ถึง C#
- Parsing-Prickly-PDFS-ทรัพยากรและแผ่นงานสำหรับการประชุมเชิงปฏิบัติการ NICAR 2016 ที่มีชื่อเดียวกัน
- PDF-text-extraction-benchmark-Benchmark เครื่องมือ PDF
- สแกนเนอร์ PDF ดิจิตอลเกิด - ตรวจสอบว่า PDF เป็นดิจิตอลเกิดหรือไม่
- OpenContracts แพลตฟอร์ม PDF ที่ได้รับอนุญาต APACHE2 ที่ได้รับการรับรองจาก PDF สำหรับเอกสารที่มีความหลากหลายทางสายตาซึ่งเก็บรักษาเค้าโครงดั้งเดิมและส่งออกข้อมูลตำแหน่ง X, Y สำหรับโทเค็นรวมถึงช่วงเริ่มต้นและหยุด ขึ้นอยู่กับ pawls แต่มีแบ็กเอนด์ที่ใช้งูเหลือมและสามารถปรับใช้ได้อย่างง่ายดายบนเครื่องในท้องถิ่นของคุณอินทราเน็ต บริษัท หรือเว็บผ่านการเขียน Docker
- DeepDoctection Deep Doctection เป็นไลบรารี Python ที่จัดทำเอกสารการสกัดเอกสารและการวิเคราะห์เค้าโครงเอกสารสำหรับรูปภาพและเอกสาร PDF โดยใช้แบบจำลองการเรียนรู้ลึก มันไม่ได้ใช้โมเดล แต่ช่วยให้คุณสามารถสร้างท่อโดยใช้ไลบรารีที่ได้รับการยอมรับอย่างสูงสำหรับการตรวจจับวัตถุ OCR และงาน NLP ที่เลือกและให้เฟรมเวิร์กแบบบูรณาการสำหรับการปรับแต่งการประเมินและการวิ่ง
- Pydoxtools Pydoxtools เป็นไลบรารี AI-composition สำหรับการวิเคราะห์ dpocument มันมีชุดเครื่องมือที่กว้างขวางสำหรับการสร้างท่อการวิเคราะห์เอกสารที่ซับซ้อนและรับรู้รูปแบบเอกสารส่วนใหญ่ออกจากกล่อง รองรับงาน NLP ทั่วไปเช่นคำหลักการสรุปคำถาม question_answering ออกจากกล่อง และคุณสมบัติอัลกอริทึมการสกัดตาราง CPU/หน่วยความจำที่มีคุณภาพสูงและทำให้การทำงานของชุด NLP บนคลัสเตอร์ง่าย
การประชุมการประชุมเชิงปฏิบัติการ
กลับไปด้านบน
ทั่วไป / ธุรกิจ / การเงิน
- การประชุมนานาชาติเกี่ยวกับการวิเคราะห์เอกสารและการรับรู้ (ICDAR) [2021, 2019, 2017]
- การประชุมเชิงปฏิบัติการเรื่อง Document Intelligence (DI) [2021, 2019]
- การประชุมเชิงปฏิบัติการการประมวลผลทางการเงิน (FNP) [2021, 2020, 2019]
- การประชุมเชิงปฏิบัติการเรื่องเศรษฐศาสตร์และการประมวลผลภาษาธรรมชาติ (ECONLP) [2021, 2019, 2018]
- การประชุมเชิงปฏิบัติการระหว่างประเทศเกี่ยวกับระบบการวิเคราะห์เอกสาร (DAS) [2020, 2018, 2016]
- การประชุมนานาชาติ ACM เกี่ยวกับ AI ในด้านการเงิน (ICAIF)
- การประชุมเชิงปฏิบัติการ AAAI-21 เกี่ยวกับการค้นพบความรู้จากข้อมูลที่ไม่มีโครงสร้างในบริการทางการเงิน
- การประชุมเชิงปฏิบัติการ CVPR 2020 เกี่ยวกับข้อความและเอกสารในยุคการเรียนรู้ลึก
- KDD Workshop เกี่ยวกับการเรียนรู้ของเครื่องจักรในด้านการเงิน (KDD MLF 2020)
- Finir 2020: การประชุมเชิงปฏิบัติการครั้งแรกเกี่ยวกับการดึงข้อมูลในการเงิน
- การประชุมเชิงปฏิบัติการ KDD ครั้งที่ 2 เกี่ยวกับการตรวจจับความผิดปกติในการเงิน (KDD 2019)
- การประชุมการทำความเข้าใจเอกสาร (DUC 2007)
ความเข้าใจในเอกสารทางวิทยาศาสตร์
- การประชุมเชิงปฏิบัติการ AAAI-21 เกี่ยวกับการทำความเข้าใจเอกสารทางวิทยาศาสตร์ (SDU 2021)
- การประชุมเชิงปฏิบัติการครั้งแรกเกี่ยวกับการประมวลผลเอกสารทางวิชาการ (SDPROC 2020)
- การประชุมเชิงปฏิบัติการระหว่างประเทศเกี่ยวกับการวิเคราะห์เอกสารทางวิทยาศาสตร์ (SCIDOCA) [2020, 2018, 2017]
บล็อก
กลับไปด้านบน
- การสำรวจรูปแบบการทำความเข้าใจเอกสาร, 2021
- การสกัดแบบฟอร์มเอกสาร, 2021
- วิธีการทำให้กระบวนการโดยอัตโนมัติด้วยข้อมูลที่ไม่มีโครงสร้าง 2021
- คู่มือที่ครอบคลุมสำหรับ OCR ด้วย RPA และความเข้าใจในเอกสาร, 2021
- การสกัดข้อมูลจากใบเสร็จรับเงินด้วยกราฟ Convolutional Networks, 2021
- วิธีแยกข้อมูลที่มีโครงสร้างจากใบแจ้งหนี้ 2021
- การแยกข้อมูลที่มีโครงสร้างจากเอกสารแบบ templatic, 2020
- ในการใช้ AI เพื่อความดีลองคิดแบบฟอร์มการสกัด, 2020
- UIPATH Document ทำความเข้าใจสถาปัตยกรรมและแนวทางการแก้ปัญหาปี 2020
- ฉันจะทำการสกัดข้อมูลโดยอัตโนมัติจากเอกสารที่ซับซ้อนได้อย่างไร, 2020
- LegalTech: การสกัดข้อมูลในเอกสารทางกฎหมายปี 2020
การแก้ปัญหา
กลับไปด้านบน
บริษัท ใหญ่:
- แอมบี้
- แอคเซนเจอร์
- อเมซอน
- Google
- Microsoft
- uipath
เล็กกว่า:
- applica.ai
- base64.ai
- เอกสาร
- องค์ประกอบ AI
- ไฟ
- อินสตาเบส
- Konfuzio
- เมตาเมีย
- นาโน
- โรสซัม
- ไซโล
ตัวอย่าง
เอกสารที่หลากหลายทางสายตา
กลับไปด้านบน
ใน VRDS ความสำคัญของข้อมูลเลย์เอาต์เป็นสิ่งสำคัญที่จะต้องเข้าใจเอกสารทั้งหมดอย่างถูกต้อง (นี่เป็นกรณีที่มีเอกสารทางธุรกิจเกือบทั้งหมด) สำหรับข้อมูลเชิงพื้นที่ของมนุษย์ช่วยเพิ่มความสามารถในการอ่านและความเร็วในการทำความเข้าใจเอกสาร
ใบแจ้งหนี้ / ประวัติย่อ / โฆษณางาน

NDA / รายงานประจำปี

การแยกข้อมูลสำคัญ
กลับไปด้านบน
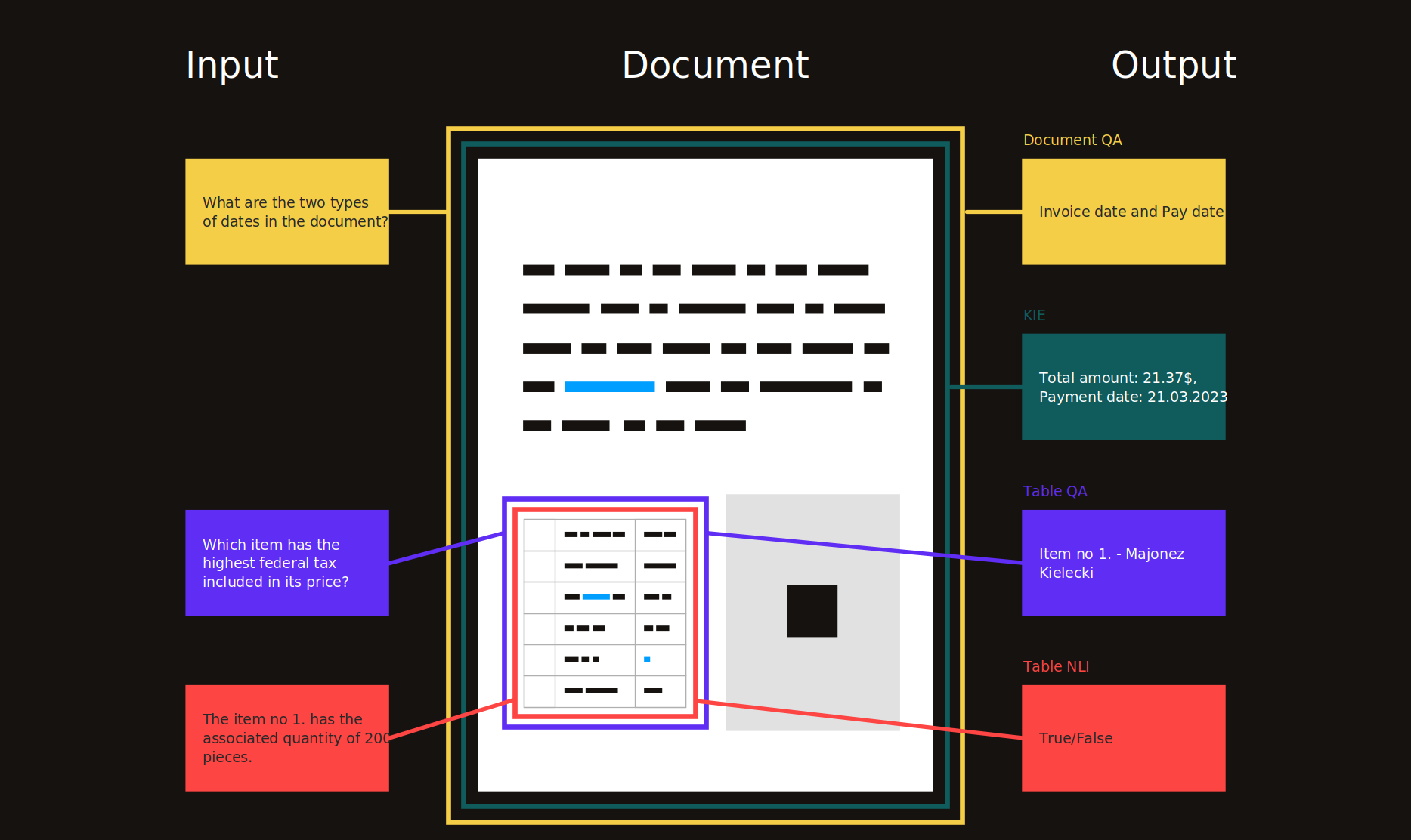
จุดมุ่งหมายของงานนี้คือการแยกข้อความของฟิลด์คีย์จำนวนหนึ่งจากการรวบรวมเอกสารที่กำหนดซึ่งมีเอนทิตีหลักที่คล้ายกัน
ใบเสร็จรับเงินที่สแกน
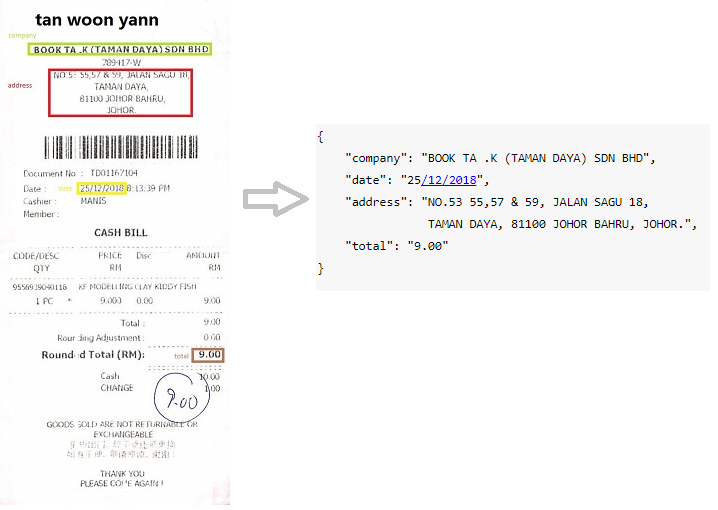
NDA / รายงานประจำปี
ตัวอย่างของแอปพลิเคชันธุรกิจจริงและข้อมูลสำหรับชุดข้อมูล Kleister (หน่วยงานหลักอยู่ในสีน้ำเงิน)
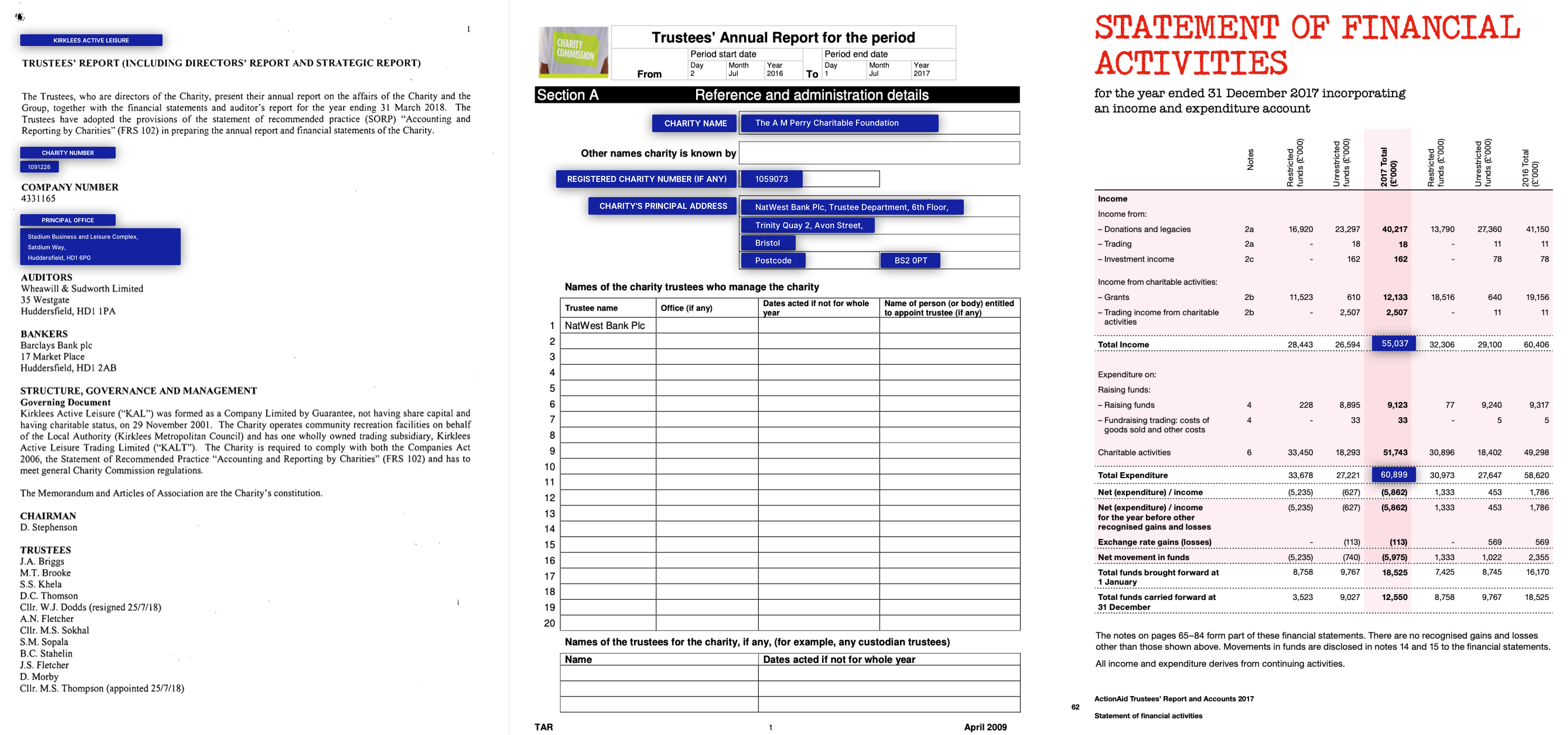
ใบปลิวออนไลน์มัลติมีเดีย
ตัวอย่างของใบปลิวอสังหาริมทรัพย์เชิงพาณิชย์และข้อมูลรายการด้วยตนเอง© Promaker Commercial Real Estate LLC, © Brokersavant Inc.
ใบแจ้งหนี้ภาษีมูลค่าเพิ่ม

หน้าเว็บ
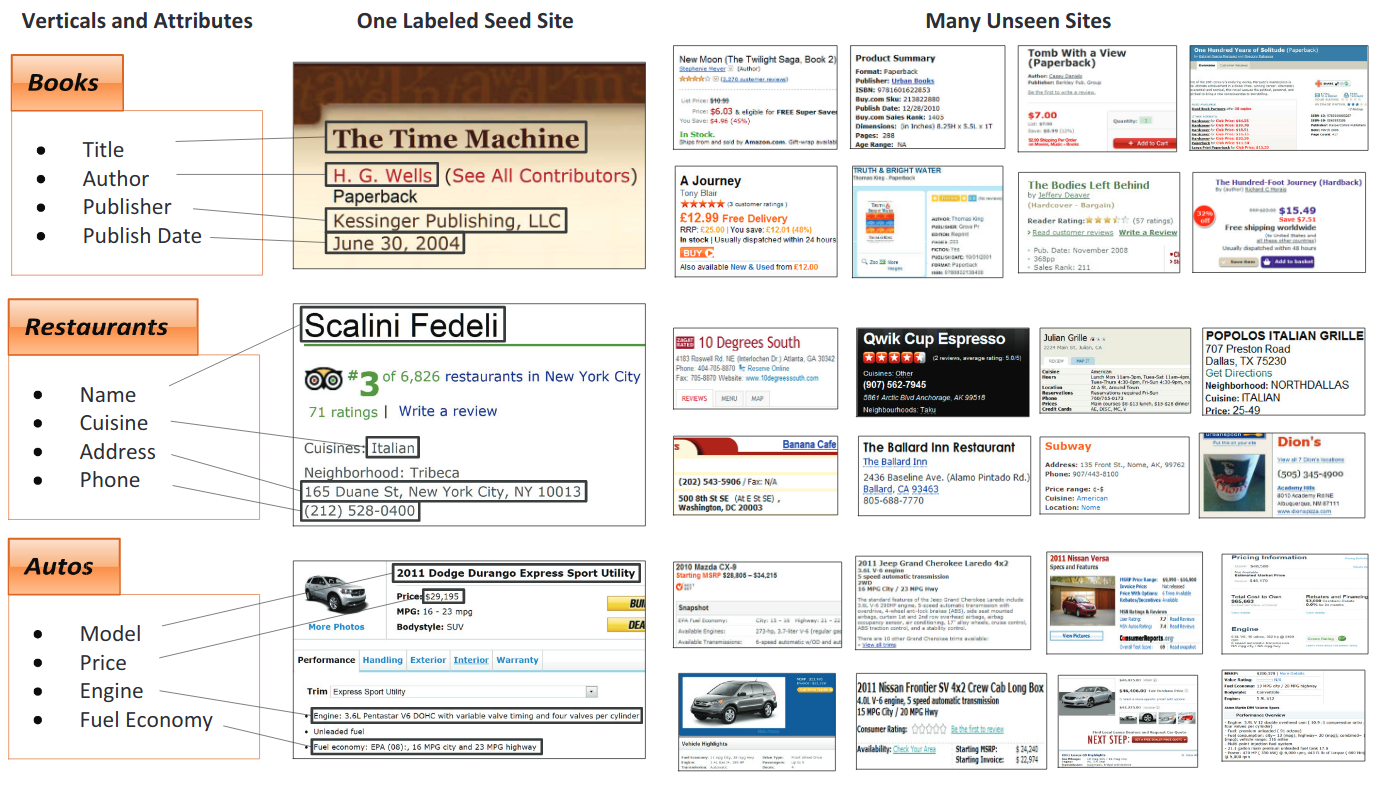
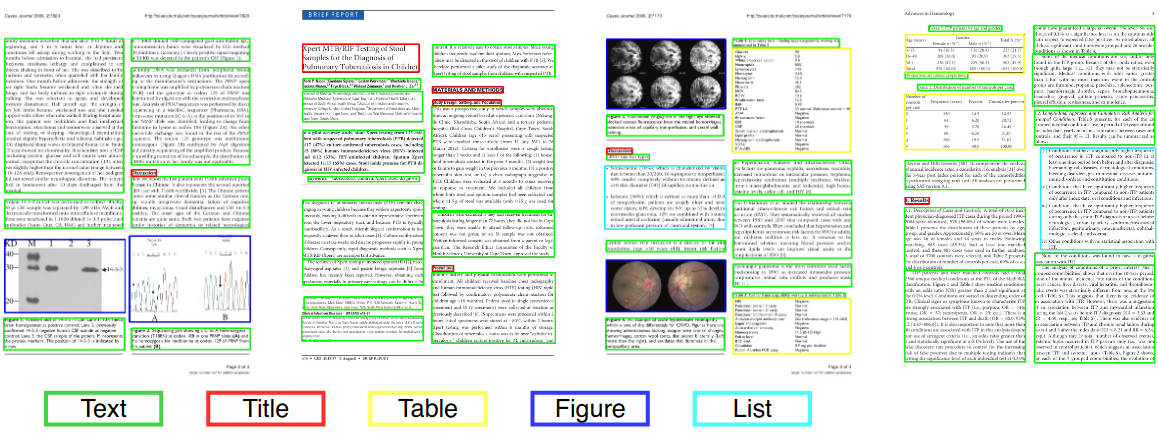
การวิเคราะห์เค้าโครงเอกสาร
กลับไปด้านบน
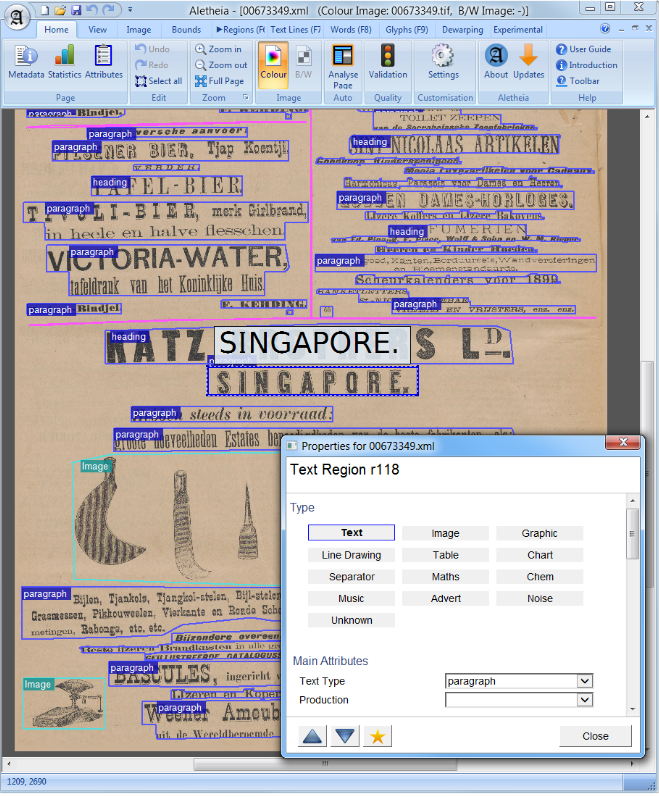
ในการมองเห็นคอมพิวเตอร์หรือการประมวลผลภาษาธรรมชาติการวิเคราะห์เค้าโครงเอกสารเป็นกระบวนการระบุและจัดหมวดหมู่ภูมิภาคที่น่าสนใจในภาพสแกนของเอกสารข้อความ ระบบการอ่านต้องการการแบ่งส่วนของโซนข้อความจากที่ไม่ใช่ข้อความและการจัดเรียงในลำดับการอ่านที่ถูกต้อง การตรวจจับและการติดฉลากของโซนที่แตกต่างกัน (หรือบล็อก) เป็นตัวข้อความภาพประกอบสัญลักษณ์คณิตศาสตร์และตารางที่ฝังอยู่ในเอกสารเรียกว่าการวิเคราะห์เค้าโครงเรขาคณิต แต่โซนข้อความมีบทบาทเชิงตรรกะที่แตกต่างกันภายในเอกสาร (ชื่อคำอธิบายภาพเชิงอรรถ ฯลฯ ) และการติดฉลากความหมายประเภทนี้คือขอบเขตของการวิเคราะห์เค้าโครงเชิงตรรกะ (https://en.wikipedia.org/wiki/document_layout_analysis)
สิ่งพิมพ์ทางวิทยาศาสตร์

หนังสือพิมพ์ประวัติศาสตร์
เอกสารทางธุรกิจ
สีแดง: บล็อกข้อความ, สีน้ำเงิน: รูป

การตอบคำถามเอกสาร
กลับไปด้านบน
ตัวอย่าง docvqa

การสาธิตแบบจำลองแบบเอียง
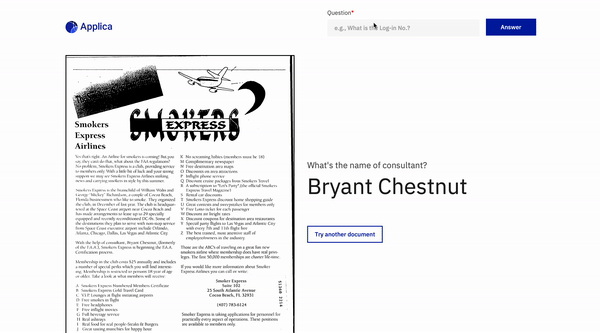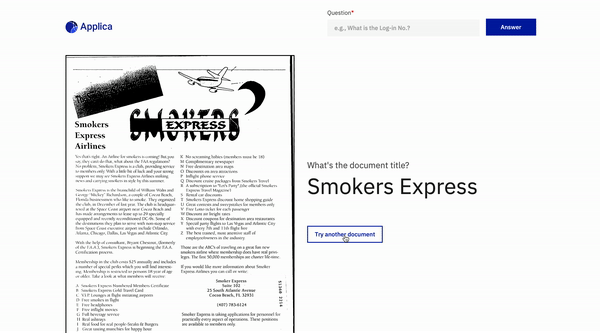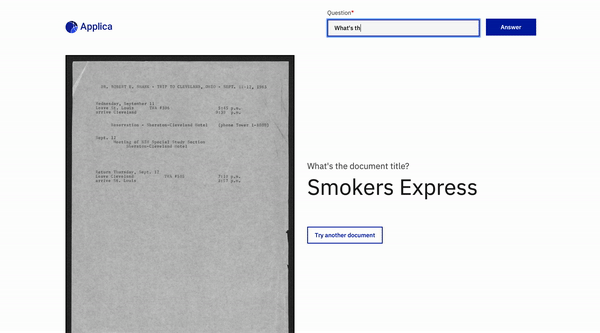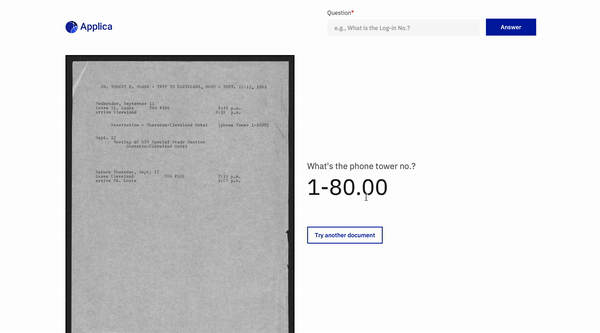
แรงบันดาลใจ
กลับไปด้านบน
โดเมน
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentlayoutanalysis
- https://github.com/bikash/documentunderstanding
- https://github.com/harpribot/awesome-information-retrieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity-rorated-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
AI/DL/ML ทั่วไป
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


