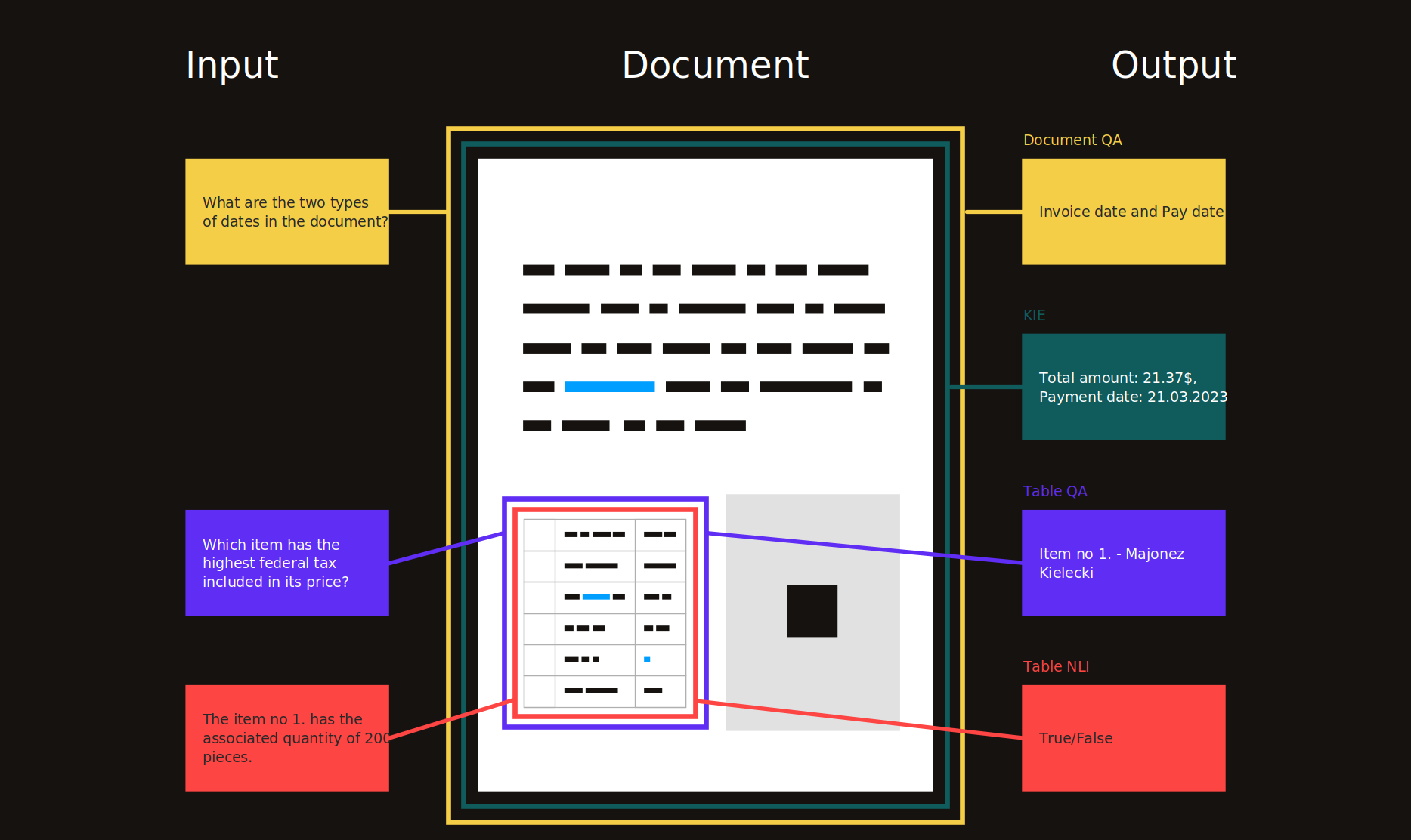
Entendimento impressionante de documentos
Uma lista com curadoria de recursos para entendimento de documentos (DU) tópico relacionado ao Processamento de Documentos Inteligentes (IDP), que é relativo à automação de processos robóticos (RPA) a partir de dados não estruturados, especialmente formando documentos visualmente ricos (VRDs).
Nota 1: As posições em negrito são mais importantes do que outras.
Nota 2: Devido à novidade do campo, esta lista está em construção - as contribuições são bem -vindas (obrigado antecipadamente!). Lembre -se de usar a seguinte convenção:
- Título de um título de publicação / DataSet / Recurso, [Code / Data / Site]
Lista de autores da conferência/nome do diário ano
Tamanho do conjunto de dados: trem (não de exemplos), dev (nenhum dos exemplos), teste (nenhum dos exemplos) [opcional para papéis/recursos do conjunto de dados]; Resumo/breve descrição ...
Índice
- Introdução
- Tópicos de pesquisa
- Principal de extração de informações (KIE)
- Análise de Layout de documentos (DLA)
- Documento de resposta a perguntas (DQA)
- Entendimento científico de documentos (SDU)
- Reconhecimento de caracteres ópticos (OCR)
- Relacionado
- Em geral
- Compreensão de dados tabulares (TDC)
- Automação de processo robótico (RPA)
- Outros
- Recursos
- Conjuntos de dados para modelos de idiomas pré-treinamento
- Ferramentas de processamento em PDF
- Conferências / workshops
- Blogs
- Soluções
- Exemplos
- Documentos visualmente ricos (VRDs)
- Principal de extração de informações (KIE)
- Análise de Layout de documentos (DLA)
- Documento de resposta a perguntas (DQA)
- Inspirações
Introdução
Os documentos são uma parte essencial de muitas empresas em muitos campos, como lei, finanças e tecnologia, entre outros. O entendimento automático de documentos como faturas, contratos e currículos é lucrativo, abrindo muitos novos caminhos de negócios. Os campos do processamento da linguagem natural e da visão computacional tiveram um tremendo progresso através do desenvolvimento de um aprendizado profundo, de modo que esses métodos começaram a ficar infundidos nos sistemas de compreensão contemporânea de documentos. fonte
Papéis
2023
- Referência dócil para localização e extração de informações do documento, [Site] [Benchmark] [Código]
Štěpán Šimsa, Milan Šulc, Michal Uentemente, Yash Patel, Ahmed Hamdi, Matěj Kocián, Matyáš Skalický, Jiří Matas, Antoine Doucet, Mickaël Coustaty, Diosthenis Karatzas Arxiv.
Este artigo apresenta a referência dócil com o maior conjunto de dados de documentos comerciais para as tarefas de localização e extração de informações e reconhecimento de itens de linha. Ele contém documentos comerciais anotados de 6,7 mil, documentos gerados sinteticamente 100K e quase ~ 1 milhão de documentos não marcados para pré-treinamento não supervisionado. O conjunto de dados foi construído com o conhecimento de aspectos específicos de domínio e tarefas, resultando nos seguintes recursos importantes: (i) anotações em 55 classes, o que ultrapassa a granularidade dos conjuntos de dados de extração de informações publicados anteriormente por uma grande margem; (ii) o reconhecimento do item de linha representa uma tarefa de extração de informações altamente práticas, onde as informações importantes devem ser atribuídas a itens em uma tabela; (iii) Os documentos vêm de vários layouts e o conjunto de testes inclui casos de zero e poucos anos, bem como layouts comumente vistos no conjunto de treinamento. O benchmark vem com várias linhas de base, incluindo Roberta, Layoutlmv3 e Transformador de tabela baseado em Detr. Esses modelos de linha de base foram aplicados às duas tarefas do benchmark dócil, com os resultados compartilhados neste artigo, oferecendo um rápido ponto de partida para trabalhos futuros. O conjunto de dados e linhas de base estão disponíveis neste URL HTTPS.
2022
Extração de informações de documentos comerciais: em direção a benchmarks práticos
Matyáš Skalický, Štěpán Šimsa, Michal Uřičář, Milan Šulc clef 2022
A extração de informações de documentos semiestruturados é crucial para a comunicação sem fricção e empresa para business (B2B). Embora os problemas de aprendizado de máquina relacionados à extração de informações do documento (IE) tenham sido estudados há décadas, muitas definições comuns de problemas e benchmarks não refletem aspectos específicos do domínio e necessidades práticas para automatizar a comunicação de documentos B2B. Analisamos o cenário dos problemas do documento, dados, conjuntos de dados e benchmarks. Destacamos os aspectos práticos ausentes nas definições comuns e definimos os principais problemas de localização e extração de informações (KILE) e reconhecimento de itens de linha (LIR). Faltam conjuntos de dados e benchmarks relevantes para o documento IE em documentos comerciais semiestruturados, pois seu conteúdo é tipicamente legalmente protegido ou sensível. Discutimos fontes em potencial de documentos disponíveis, incluindo dados sintéticos. DOC2GRAPH: uma tarefa AGNOSTIC DOCUMENTO ENCERTIDA COMPREENCIDO COM base em redes neurais gráficas, [código]
Andrea Gemelli, Sanket Biswas, Enrico Civitelli, Josep Lladós, Simone Marinai Tie Workshop @ ECCV 2022
A aprendizagem geométrica profunda atraiu recentemente um interesse significativo em uma ampla gama de campos de aprendizado de máquina, incluindo análise de documentos. A aplicação de redes neurais gráficas (GNNs) tornou-se crucial em várias tarefas relacionadas a documentos, pois podem desvendar importantes padrões estruturais, fundamentais nos principais processos de extração de informações. Trabalhos anteriores na literatura propõem modelos orientados por tarefas e não levam em consideração todo o poder dos gráficos. Propomos o Doc2Graph, uma estrutura de entendimento de documentos agnósticos de tarefas com base em um modelo GNN, para resolver tarefas diferentes, com diferentes tipos de documentos. Avaliamos nossa abordagem em dois conjuntos de dados desafiadores para extração de informações importantes no entendimento de formulários, análise de layout de faturas e detecção de tabela
2021
Documento AI: Benchmarks, Modelos e Aplicações
Lei Cui, Yiheng Xu, Tengchao LV, Furu Wei Arxiv 2021
O documento IA, ou a inteligência do documento, é um tópico de pesquisa relativamente novo que se refere às técnicas para ler, entender e analisar automaticamente documentos de negócios. É uma direção de pesquisa importante para o processamento de linguagem natural e a visão computacional. Nos últimos anos, a popularidade da tecnologia Deep Learning avançou bastante o desenvolvimento do documento IA, como análise de layout de documentos, extração de informações visuais, resposta a perguntas visuais para documentos, classificação de imagens de documentos, etc. Este artigo analisa brevemente alguns dos modelos representativos, tarefas e conjuntos de dados de referência. Além disso, também introduzimos análise de documentos baseados em regras heurísticas em estágio inicial, algoritmos estatísticos de aprendizado de máquina e abordagens de aprendizado profundo, especialmente métodos de pré-treinamento. Finalmente, analisamos as direções futuras para a pesquisa de IA do documento. Processamento automatizado eficiente dos documentos não estruturados usando inteligência artificial: uma revisão sistemática da literatura e direções futuras
Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, Ketan Kotecha IEEE Access 2021
Os dados não estruturados afetam 95% das organizações e custam milhões de dólares anualmente. Se gerenciado bem, pode melhorar significativamente a produtividade dos negócios. As técnicas tradicionais de extração de informações são limitadas em sua funcionalidade, mas as técnicas baseadas em IA podem fornecer uma solução melhor. Uma investigação completa das técnicas baseadas em IA para extração automática de informações de documentos não estruturados está ausente na literatura. O objetivo desta revisão sistemática da literatura (SLR) é reconhecer e analisar pesquisas sobre as técnicas usadas para extração automática de informações de documentos não estruturados e fornecer instruções para pesquisas futuras. As diretrizes da SLR propostas por Kitcheham e Charters foram respeitadas para realizar uma pesquisa de literatura em vários bancos de dados entre 2010 e 2020. Descobrimos que: 1. As técnicas de extração de informações existentes são baseadas em modelos ou baseadas em regras, 2. Os métodos existentes não possuem a capacidade de lidar com os layouts de documentos complexos em sítios em tempo real, como as especificações e os pedidos de compra e compra, que não são de compras, que não são de que os pedidos de compra e as especificações e os que não são de compra e os que não são de compra e pedidos de compra e pedidos de compra e compra e compra e os que não são específicos. Portanto, é necessário desenvolver um novo conjunto de dados que reflita problemas no mundo real. Nossa SLR descobriu que as abordagens baseadas em IA têm um forte potencial para extrair informações úteis de documentos não estruturados automaticamente. No entanto, eles enfrentam certos desafios no processamento de vários layouts dos documentos não estruturados. Nossa SLR traz à tona a conceituação de uma estrutura para a construção de um conjunto de dados de documentos não estruturados de alta qualidade com fortes técnicas de validação de dados para extração de informações automatizadas. Nossa SLR também revela a necessidade de uma estreita associação entre as empresas e os pesquisadores para lidar com vários desafios da análise de dados não estruturados.
2020
2018
- Paradigmas futuros do processamento automatizado de documentos de negócios
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
Neste artigo, resumimos os resultados obtidos até agora nas comunidades interessadas no desenvolvimento de técnicas de processamento automatizadas aplicadas aos documentos de negócios e elaboram algumas evoluções exigidas pelo estágio atual dessas técnicas por si mesmas ou pelos avanços do setor de garantias. Ele emerge uma imagem clara de um campo que fez um enorme esforço na solução de problemas que mudaram muito nos últimos 30 anos e agora está evoluindo rapidamente para incorporar o processamento de documentos nos sistemas de gerenciamento de fluxo de trabalho de um lado e incluir recursos derivados pela introdução de tecnologias de computação em nuvem do outro lado. Propomos um esquema arquitetônico para o processamento de documentos de negócios que vem das duas linhas de evolução acima.
Mais velho
Tópicos de pesquisa
- Principal de extração de informações (KIE)
- Análise de Layout de documentos (DLA)
- Documento de resposta a perguntas (DQA)
- Entendimento científico de documentos (SDU)
- Recogtion Optical Caracter (OCR)
- Relacionado
- Em geral
- Compreensão de dados tabulares (TDC)
- Automação de processo robótico (RPA)
Outros
Recursos
De volta ao topo
Conjuntos de dados para modelos de idiomas pré-treinamento
- O conjunto de dados RVL -CDIP - o conjunto de dados consiste em 400.000 imagens em escala de cinza em 16 classes, com 25.000 imagens por classe
- A Biblioteca de Documentos da Indústria - um portal para milhões de documentos criados por indústrias que influenciam a saúde pública, hospedada pela biblioteca UCSF
- DataSet de documentos coloridos - dos sistemas de informação sensorial inteligentes, Universidade de Amsterdã
- A coleção do CDIP do IIT - o conjunto de dados consiste em documentos do processo dos estados contra a indústria do tabaco na década de 1990, consiste em cerca de 7 milhões de documentos
Ferramentas de processamento em PDF
- Borb - é uma biblioteca Python pura para ler, escrever e manipular documentos em PDF. Representa um documento em PDF como umaestrutura de datacture do tipo JSON de listas, dicionários e primitivos aninhados (números, string, booleanos, etc.).
- PAWS - Anotações em PDF com rótulos e estrutura é um software que facilita a coleção de uma série de anotações associadas a um documento em PDF
- PDFPLUMBRUM - PLUMB Um PDF para obter informações detalhadas sobre cada caractere de texto, retângulo e linha. Além disso: extração de tabela e depuração visual
- Pdfminer.six - pdfminer.six é um garfo mantido da comunidade do PDFMiner original. É uma ferramenta para extrair informações dos documentos em PDF. Ele se concentra em obter e analisar dados de texto
- Analisador de layout - o analisador de layout é uma ferramenta profunda baseada em aprendizado para tarefas de análise de layout de imagem de documento
- Tabulo - Extração de tabela de imagens
- OCRMYPDF - OCRMYPDF adiciona uma camada de texto OCR aos arquivos PDF digitalizados, permitindo que eles sejam pesquisados ou copiados
- PDFBox - A biblioteca Apache PDFBox é uma ferramenta Java de código aberto para trabalhar com documentos PDF. Este projeto permite a criação de novos documentos em PDF, a manipulação dos documentos existentes e a capacidade de extrair conteúdo de documentos
- PDFPIG - Este projeto permite que os usuários leiam e extraem texto e outros conteúdos dos arquivos PDF. Além disso, a biblioteca pode ser usada para criar documentos PDF simples contendo texto e formas geométricas. Este projeto tem como objetivo portar pdfbox para C#
- Parsing-PRICKLY-PDFS-Recursos e planilhas para o workshop da NICAR 2016 com o mesmo nome
- PDF-Text-Extraction-Benchmark-Referência de ferramentas em PDF
- Scanner de PDF digital nascido - verificando se o PDF nasce
- OpenContrates Plataforma de anotação PDF de licenciamento Apache2 para documentos ricos em visualmente que preservam o layout original e exporta X, Y Dados posicionais para tokens, bem como o span inicia e as paradas. Com base em PAWS, mas com um back-end baseado em Python e prontamente implantável em sua máquina local, intranet da empresa ou a Web via Docker Compose.
- O DeepDitection Deep Doctection é uma biblioteca Python que orquestra a extração de documentos e as tarefas de análise de layout de documentos para imagens e documentos em PDF usando modelos de aprendizado profundo. Ele não implementa modelos, mas permite criar pipelines usando bibliotecas altamente reconhecidas para detecção de objetos, OCR e tarefas selecionadas de NLP e fornece uma estrutura integrada para ajustes finos, avaliação e execução de modelos.
- O Pydoxtools Pydoxtools é uma biblioteca de composição de AI para análise de dpocument. Possui um extenso conjunto de ferramentas para a criação de pipelines de análise de documentos complexos e reconhece a maioria dos formatos de documentos fora da caixa. Ele suporta tarefas típicas de PNL, como palavras -chave, resumo, question_answering para fora da caixa. e possui um algoritmo de extração de tabela de baixa CPU/memória de alta qualidade e facilita a operações de lote de PNL em um cluster.
Conferências, oficinas
De volta ao topo
Geral / Business / Finanças
- Conferência Internacional sobre Análise e Reconhecimento de Documentos (ICDAR) [2021, 2019, 2017]
- Workshop sobre inteligência de documentos (DI) [2021, 2019]
- Workshop de Processamento Narrativo Financeiro (FNP) [2021, 2020, 2019]
- Workshop sobre Economia e Processamento de Linguagem Natural (ECONLP) [2021, 2019, 2018]
- Workshop Internacional sobre Sistemas de Análise de Documentos (DAS) [2020, 2018, 2016]
- Conferência Internacional da ACM sobre IA em Finanças (ICAIF)
- O workshop AAAI-21 sobre descoberta de conhecimento a partir de dados não estruturados em serviços financeiros
- Workshop do CVPR 2020 sobre texto e documentos na era do Deep Learning
- Workshop KDD sobre aprendizado de máquina em finanças (KDD MLF 2020)
- Finir 2020: O primeiro workshop sobre recuperação de informações em finanças
- 2ª oficina de KDD sobre detecção de anomalia em finanças (KDD 2019)
- Conferência de Entendendo do Documento (DUC 2007)
Entendimento científico do documento
- O workshop AAAI-21 sobre entendimento do documento científico (SDU 2021)
- Primeiro workshop sobre processamento de documentos acadêmicos (SDPROC 2020)
- Workshop Internacional sobre Análise de Documentos Científicos (SCIDOCA) [2020, 2018, 2017]
Blogs
De volta ao topo
- Uma pesquisa com modelos de compreensão de documentos, 2021
- Extração de formulários de documentos, 2021
- Como automatizar processos com dados não estruturados, 2021
- Um guia abrangente para OCR com RPA e entendimento de documentos, 2021
- Extração de informações de recibos com redes convolucionais de gráfico, 2021
- Como extrair dados estruturados de faturas, 2021
- Extraindo dados estruturados de documentos templáticos, 2020
- Para aplicar a IA para sempre, pense em extração, 2020
- UiPath Document Underping Solution Architecture and Approach, 2020
- Como posso automatizar a extração de dados de documentos complexos?, 2020
- LegalTech: Extração de informações em documentos legais, 2020
Soluções
De volta ao topo
Grandes empresas:
- Abby
- Accenture
- Amazon
- Google
- Microsoft
- Uipath
Menor:
- Aplica.ai
- Base64.ai
- Docstack
- Elemento ai
- Indico
- Instabase
- Konfuzio
- Metamaze
- Nanonets
- Rossum
- Silo
Exemplos
Documentos visualmente ricos
De volta ao topo
Em VRDs, a importância das informações do layout é crucial para entender o documento inteiro corretamente (este é o caso de quase todos os documentos comerciais). Para os seres humanos, as informações espaciais melhora a legibilidade e as velocidades documentam a compreensão.
Fatura / currículo / anúncio de trabalho

NDA / relatórios anuais

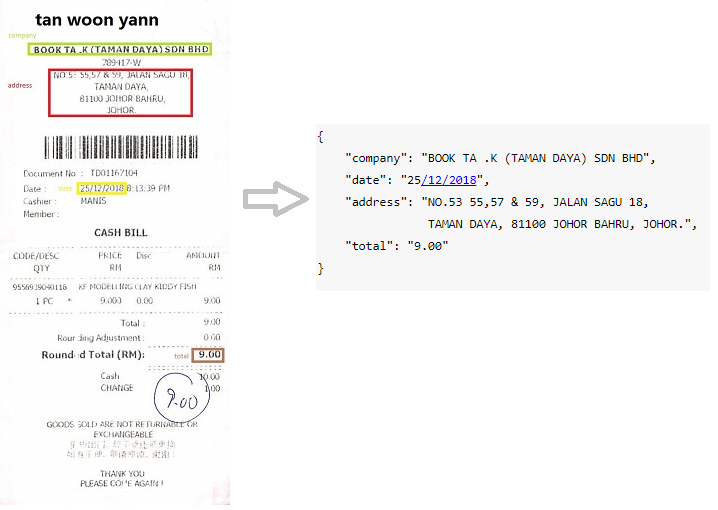
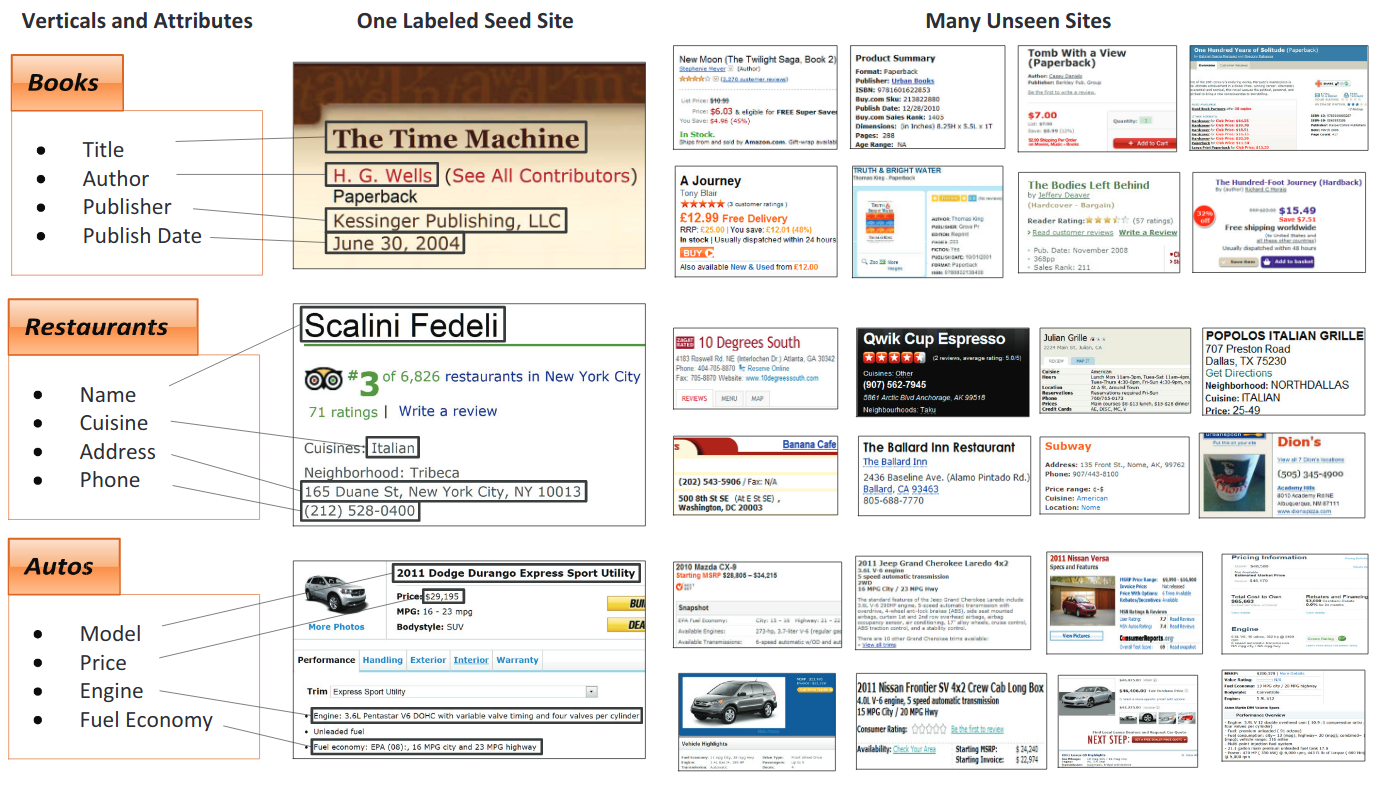
Extração de informações -chave
De volta ao topo
O objetivo desta tarefa é extrair textos de vários campos -chave de uma determinada coleção de documentos contendo entidades -chave semelhantes.
Recibos digitalizados
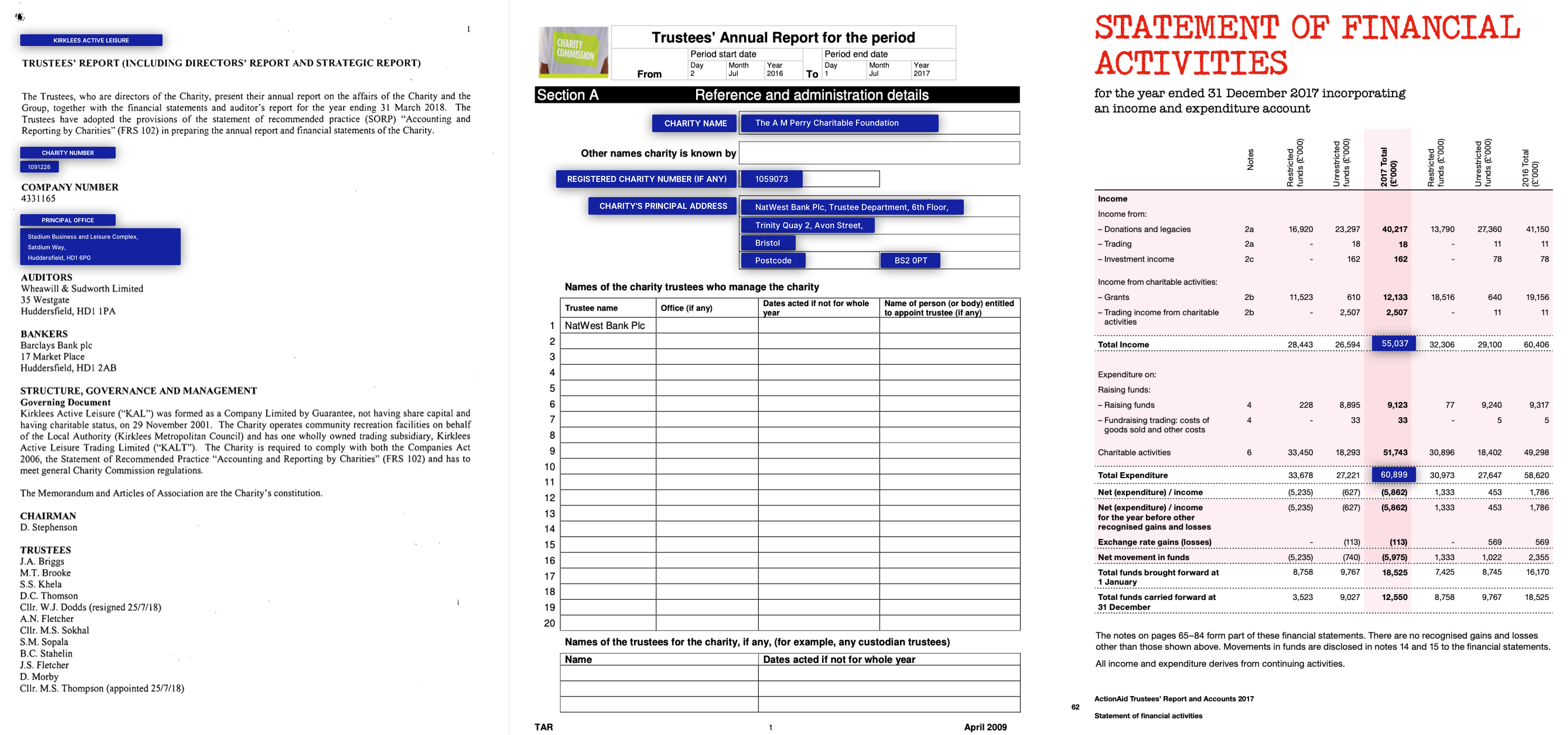
NDA / relatórios anuais
Exemplos de aplicativos e dados de negócios reais para conjuntos de dados Kleister (as entidades principais estão em azul)
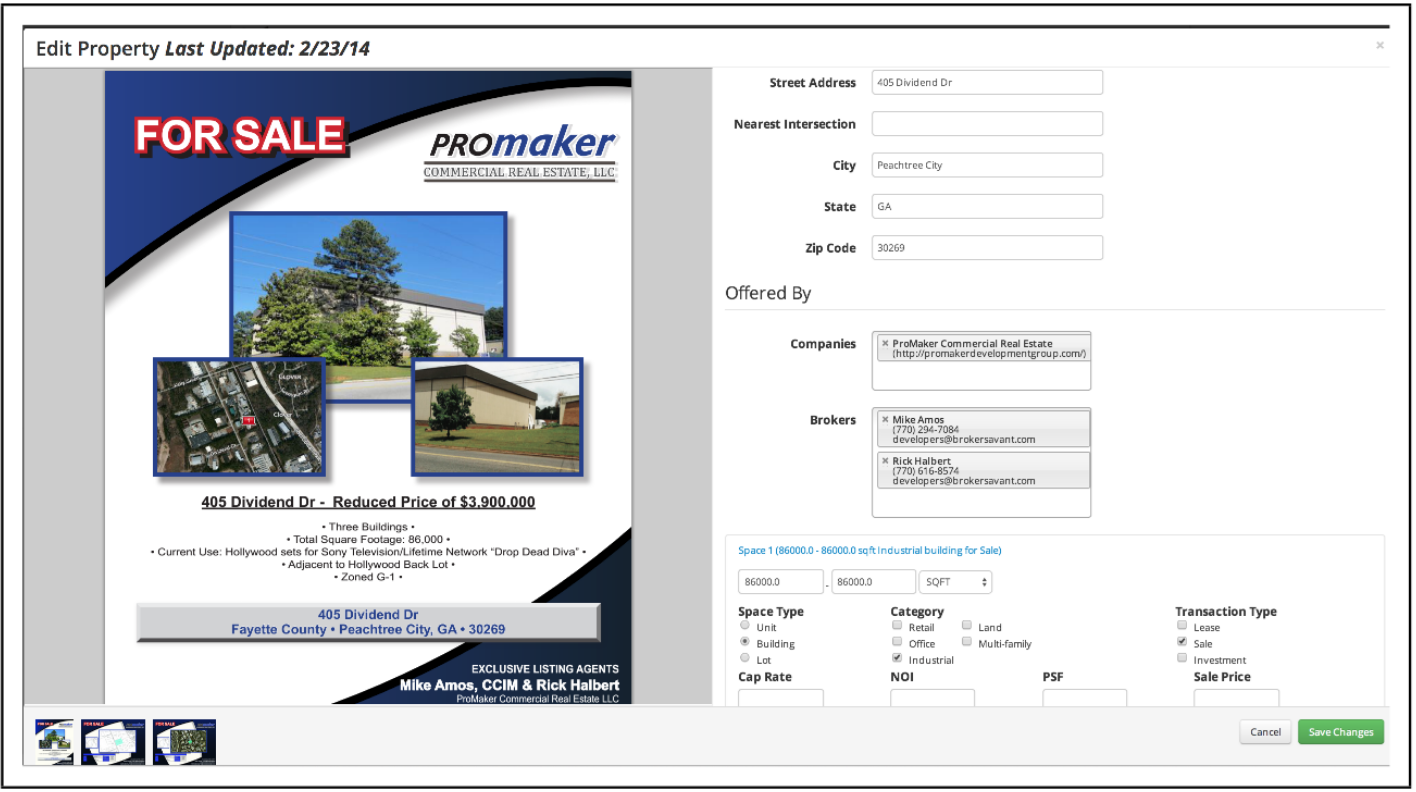
Folhetos online multimídia
Um exemplo de um panfleto de imóveis comerciais e inseriu manualmente informações de listagem © PROMAKER COMERCIAL REAL Estate LLC, © Brokersavant Inc.
Fatura fiscal de valor agregado

Páginas da web
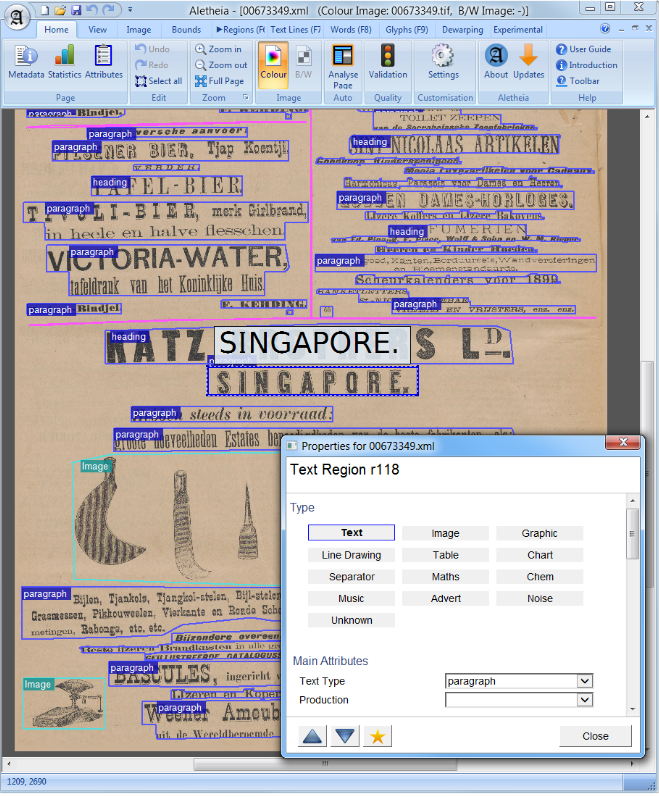
Análise de layout do documento
De volta ao topo
Na visão computacional ou no processamento de linguagem natural, a análise de layout de documentos é o processo de identificação e categorização das regiões de interesse na imagem digitalizada de um documento de texto. Um sistema de leitura requer a segmentação das zonas de texto dos não textuais e o arranjo em sua ordem de leitura correta. Detecção e rotulagem das diferentes zonas (ou blocos) como corpo de texto, ilustrações, símbolos de matemática e tabelas incorporadas em um documento é chamado de análise de layout geométrica. Mas as zonas de texto desempenham diferentes papéis lógicos dentro do documento (títulos, legendas, notas de rodapé etc.) e esse tipo de rotulagem semântica é o escopo da análise de layout lógica. (https://en.wikipedia.org/wiki/document_layout_analysis)
Publicação científica
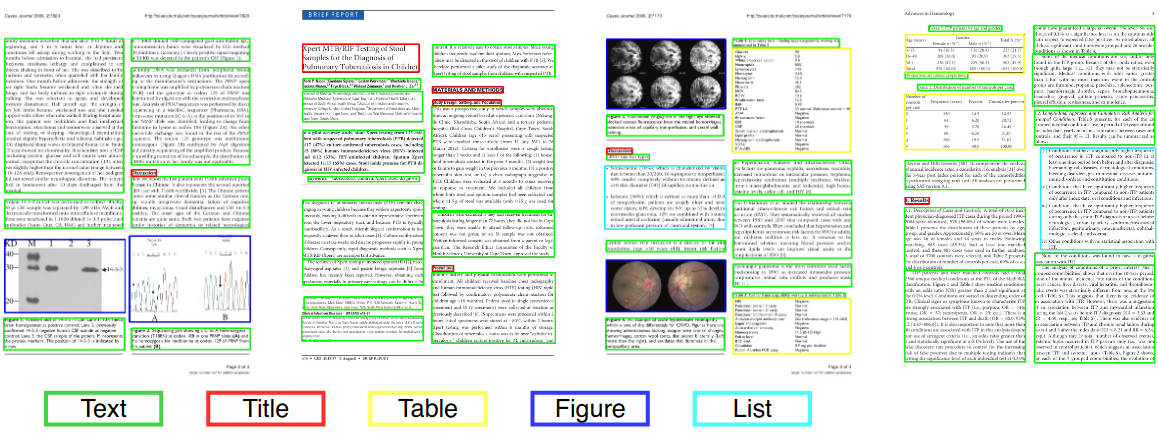

Jornais históricos
Documentos comerciais
Vermelho: bloco de texto, azul: figura.

Documento de resposta a perguntas
De volta ao topo
Exemplo de docvqa

Demonstração do modelo de inclinação
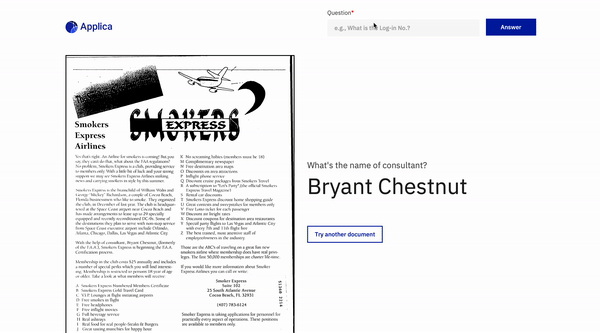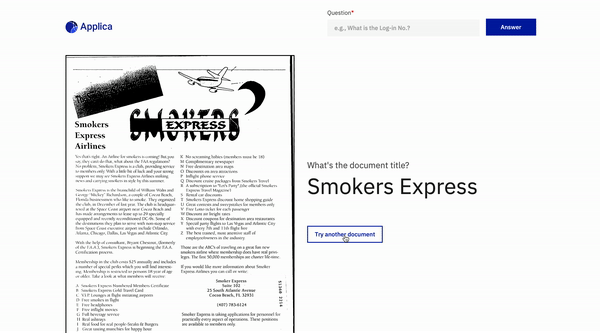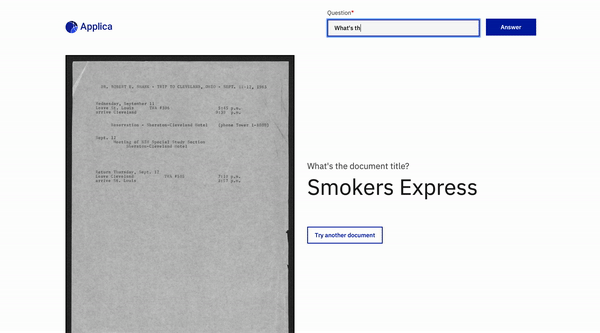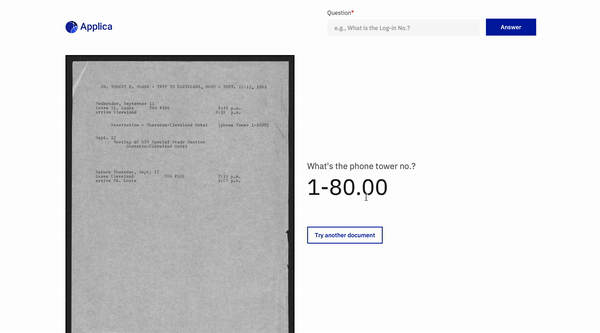
Inspirações
De volta ao topo
Domínio
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentlayoutanálise
- https://github.com/bikash/documentunderStanding
- https://github.com/harpribot/awesome-information-rerieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity-related-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
Geral AI/DL/ML
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugueneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-ove/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


