멋진 문서 이해
구조화되지 않은 데이터의 RPA (Robotic Process Automation)와 관련된 지능형 문서 처리 (IDP)와 관련된 문서 이해 (DU) 주제를위한 선별 된 리소스 목록, 특히 시각적으로 풍부한 문서 (VRD)를 형성합니다.
참고 1 : 대담한 위치는 다른 것보다 더 중요합니다.
참고 2 : 필드의 참신함으로 인해이 목록은 건설 중입니다. 기부금을 환영합니다 (미리 감사드립니다!). 다음 컨벤션을 사용해야합니다.
- 게시 / 데이터 세트 / 리소스 제목 제목, [코드 / 데이터 / 웹 사이트]
저자 컨퍼런스/저널 이름 연도 목록
데이터 세트 크기 : Train (예제 없음), DEV (예제 없음), 테스트 (예 없음) [데이터 세트 용지/리소스의 선택 사항]; 초록/간단한 설명 ...
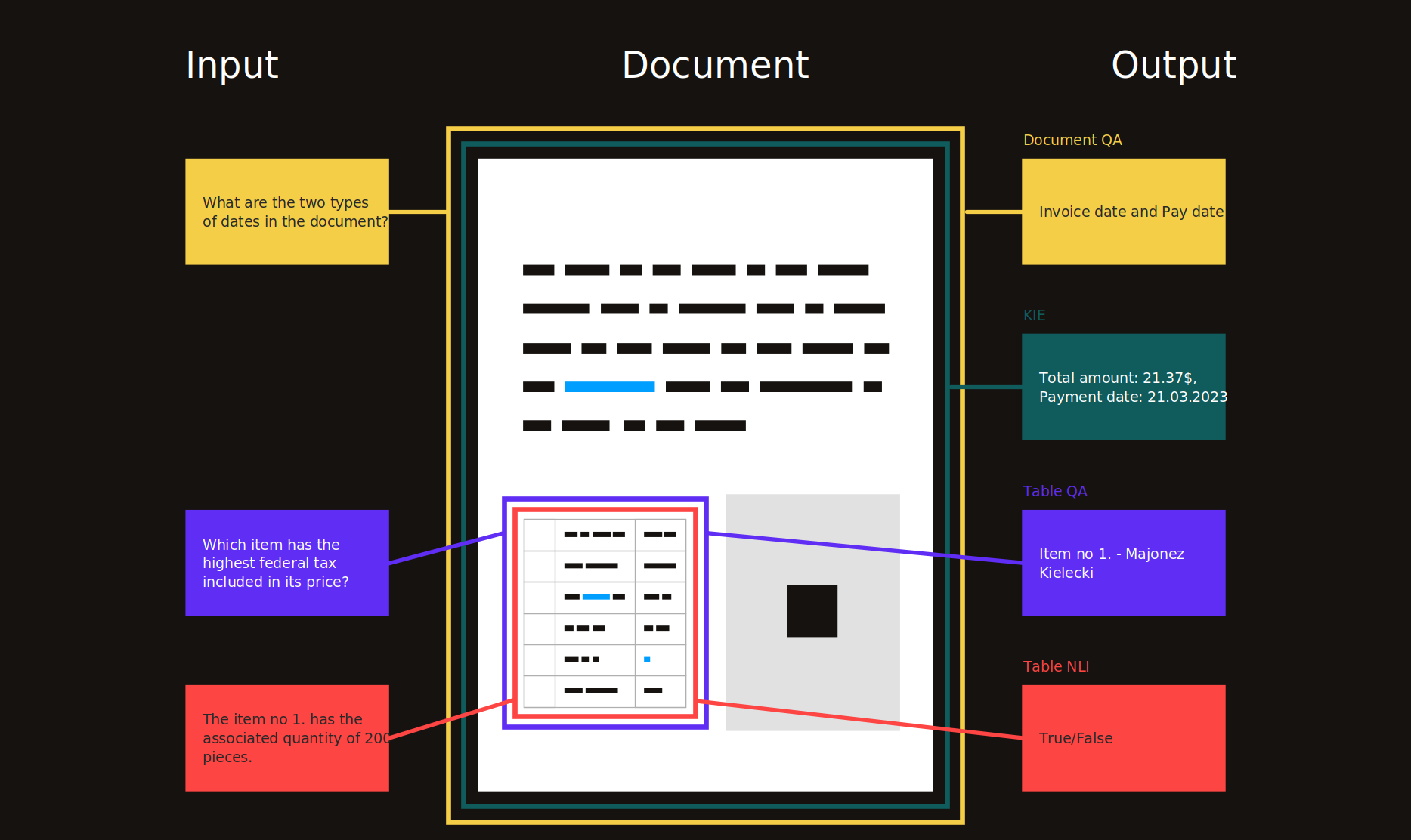
목차
- 소개
- 연구 주제
- 주요 정보 추출 (KIE)
- 문서 레이아웃 분석 (DLA)
- 문서 질문 응답 (DQA)
- 과학 문서 이해 (SDU)
- 광학 문자 인식 (OCR)
- 관련된
- 일반적인
- 표 형 데이터 이해 (TDC)
- 로봇 공정 자동화 (RPA)
- 기타
- 자원
- 사전 훈련 언어 모델을위한 데이터 세트
- PDF 처리 도구
- 회의 / 워크샵
- 블로그
- 솔루션
- 예
- 시각적으로 풍부한 문서 (VRD)
- 주요 정보 추출 (KIE)
- 문서 레이아웃 분석 (DLA)
- 문서 질문 응답 (DQA)
- 영감
소개
문서는 법, 재무 및 기술과 같은 많은 분야의 많은 비즈니스의 핵심 부분입니다. 송장, 계약 및 이력서와 같은 문서에 대한 자동 이해는 유리하며 많은 새로운 비즈니스 길을 열어줍니다. 자연 언어 처리 및 컴퓨터 비전 분야는 딥 러닝의 개발을 통해 엄청난 진전을 보였으므로 이러한 방법은 현대 문서 이해 시스템에 주입되기 시작했습니다. 원천
서류
2023
- 문서 정보 현지화 및 추출에 대한 연약한 벤치 마크, [웹 사이트] [벤치 마크] [코드]
Štěpán Šimsa, Milan Šulc, Michal UQuzičád, Yash Patel, Ahmed Hamdi, Matěj Kocián, Matyáš Skalický, Jizí Matas, Antoine Doucet, Mickaël Coustaty, Dimosthenis Karatzas Pre-Print 2023
이 백서는 주요 정보 현지화 및 추출 및 라인 항목 인식 작업에 대한 가장 큰 비즈니스 문서 데이터 세트와 함께 연약한 벤치 마크를 소개합니다. 여기에는 6.7K 주석이 달린 비즈니스 문서, 합성 된 100K 문서 및 감독되지 않은 사전 훈련을위한 거의 ~ 1m의 표지되지 않은 문서가 포함되어 있습니다. 이 데이터 세트는 도메인 및 작업 별 측면에 대한 지식으로 구축되어 다음과 같은 주요 기능을 초래했습니다. (i) 55 개의 클래스의 주석은 이전에 게시 된 주요 정보 추출 데이터 세트의 세분성을 큰 마진으로 능가합니다. (ii) 라인 항목 인식은 주요 정보를 테이블의 항목에 할당 해야하는 매우 실용적인 정보 추출 작업을 나타냅니다. (iii) 문서는 수많은 레이아웃에서 나오고 테스트 세트에는 제로 및 소수의 케이스와 훈련 세트에서 일반적으로 볼 수있는 레이아웃이 포함됩니다. 벤치 마크에는 Roberta, LayoutLMV3 및 DETR 기반 테이블 변압기를 포함한 여러 기준이 있습니다. 이 기준 모델은 연약한 벤치 마크의 두 작업에 적용되었으며,이 백서에서 결과가 공유되어 향후 작업을위한 빠른 출발점을 제공합니다. 데이터 세트 및 기준선은이 HTTPS URL에서 사용할 수 있습니다.
2022
2021
2020
2018
- 비즈니스 문서의 자동 처리의 미래 패러다임
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
이 논문에서 우리는 비즈니스 문서에 적용되는 자동화 된 처리 기술 개발에 관심이있는 지역 사회에서 얻은 결과를 요약하고, 그 기술의 현재 단계에서 자체적으로 또는 담보 부문 발전에 의해 요구되는 몇 가지 진화를 고안합니다. 지난 30 년 동안 많은 변화를 일으킨 문제를 해결하는 데 엄청난 노력을 기울이고 있으며, 이제 문서 처리를 한쪽의 워크 플로 관리 시스템에 통합하고 다른쪽에 클라우드 컴퓨팅 기술을 도입하여 도출 된 기능을 포함하도록 빠르게 발전하고 있습니다. 우리는 위의 두 개의 진화 라인에서 나오는 비즈니스 문서 처리를위한 아키텍처 스키마를 제안합니다.
더 오래
인쇄 된 문서의 지능형 처리를위한 기계 학습
F. Esposito, D. Malerba, F. Lisi -2004
용지 문서 처리 시스템은 인쇄 된 문서 또는 필기 문서의 정보를 컴퓨터 방지 형식으로 변환하는 정보 시스템 구성 요소입니다. 종이 문서 처리를위한 지능형 시스템 에서이 정보 캡처 프로세스는 문서의 특정 레이아웃 및 논리 구조에 대한 지식을 기반으로합니다. 이 기사는 서신 및 저널과 같은 인쇄 된 문서를 관리하는 지능형 문서 처리 시스템 (Wisdom ++)이 요구하는 특정 지식을 획득하기 위해 기계 학습 기술의 적용을 제안합니다. 지식은 의사 결정 트리 및 일련의 교육 문서에서 자동으로 생성 된 1 차 규칙으로 표시됩니다. 특히, 분류 된 블록의 분류에 사용되는 의사 결정 트리의 획득에 증분 결정 트리 학습 시스템이 적용되는 반면, 1 차 학습 시스템은 레이아웃 기반 분류 및 문서 이해에 사용되는 규칙의 유도에 적용됩니다. 결정 트리의 증분 유도와 1 차 규칙 학습에서 숫자 및 상징적 데이터의 처리에 관한 문제에 대해 논의하며, 제안 된 솔루션의 유효성은 실제 인쇄 된 문서 세트를 처리함으로써 경험적으로 평가됩니다. 문서 이해 : 연구 방향
S. Srihari, S. Lam, V. Govindaraju, R. Srihari, J. Hull -1994
문서 이미지는 저널 기사 페이지, 팩스 커버 페이지, 기술 문서, 사무실 서신 등과 같은 인쇄 된 페이지를 시각적으로 표현한 것입니다. 연구 노력으로 문서 이해는 스캔 한 물리적 문서에서 문서의 높은 수준의 의미 론적 설명에 이르기까지 다양한 표현을 통해 문서를 작성하는 것과 관련된 모든 프로세스를 연구하는 것으로 구성됩니다. 유용한 표현 유형 중 일부는 다음과 같습니다. 편집 가능한 설명, 정확한 복제를 가능하게하는 설명 및 문서 컨텐츠에 대한 높은 수준의 의미 론적 설명입니다. 이 보고서는 주로 인쇄 된 문서와 관련된 문서 이해 내에서 5 개의 연구 하위 도메인에 대한 정의입니다. 설명 된 주제는 다음과 같습니다. 문서 이해를위한 모듈 식 아키텍처; 문서의 분해 및 구조 분석; 모델 기반 OCR; 표, 다이어그램 및 이미지 이해; 왜곡 및 소음에서 성능 평가.
연구 주제
- 주요 정보 추출 (KIE)
- 문서 레이아웃 분석 (DLA)
- 문서 질문 응답 (DQA)
- 과학 문서 이해 (SDU)
- 광학 문자 추천 (OCR)
- 관련된
- 일반적인
- 표 형 데이터 이해 (TDC)
- 로봇 공정 자동화 (RPA)
기타
자원
위로 돌아갑니다
사전 훈련 언어 모델을위한 데이터 세트
- RVL -CDIP 데이터 세트 - 데이터 세트는 16 개의 클래스에서 400,000 개의 그레이 스케일 이미지로 구성되며 수업 당 25,000 개의 이미지가 있습니다.
- 업계 문서 라이브러리 - UCSF 라이브러리가 주최하는 공중 보건에 영향을 미치는 산업에서 만든 수백만 문서에 대한 포털
- 컬러 문서 데이터 세트 - 암스테르담 대학교의 지능형 감각 정보 시스템에서
- IIT CDIP 컬렉션 - 데이터 세트는 1990 년대 담배 산업에 대한 주 소송의 문서로 구성되며 약 7 백만 개의 문서로 구성됩니다.
PDF 처리 도구
- BORB- PDF 문서를 읽고 쓰고, 조작 할 수있는 순수한 파이썬 라이브러리입니다. 중첩 된 목록, 사전 및 프리미티브 (숫자, 문자열, 부울 등)의 JSON과 유사한 데이터 구조로 PDF 문서를 나타냅니다.
- Pawls- 레이블 및 구조가있는 PDF 주석은 PDF 문서와 관련된 일련의 주석을 쉽게 수집 할 수있는 소프트웨어입니다.
- pdfplumber -Plumb 각 텍스트 문자, 사각형 및 라인에 대한 자세한 정보를위한 PDF. 플러스 : 테이블 추출 및 시각적 디버깅
- PDFMINER.SIX -PDFMINER.SIX는 원래 PDFMINER의 커뮤니티를 유지 관리하는 커뮤니티입니다. PDF 문서에서 정보를 추출하는 도구입니다. 텍스트 데이터를 얻고 분석하는 데 중점을 둡니다
- 레이아웃 파서 - 레이아웃 파서는 문서 이미지 레이아웃 분석 작업을위한 딥 러닝 기반 도구입니다.
- Tabulo- 이미지에서 테이블 추출
- OCRMYPDF -OCRMYPDF는 스캔 한 PDF 파일에 OCR 텍스트 레이어를 추가하여 검색하거나 복사 할 수 있습니다.
- PDFbox- Apache PDFBox 라이브러리는 PDF 문서로 작업하기위한 오픈 소스 Java 도구입니다. 이 프로젝트는 새로운 PDF 문서를 작성, 기존 문서 조작 및 문서에서 컨텐츠를 추출 할 수있는 기능을 제공합니다.
- PDFPIG-이 프로젝트를 통해 사용자는 PDF 파일에서 텍스트 및 기타 컨텐츠를 읽고 추출 할 수 있습니다. 또한 라이브러리는 텍스트와 기하학적 형태가 포함 된 간단한 PDF 문서를 만드는 데 사용될 수 있습니다. 이 프로젝트는 PDFBox를 C#에 포트하는 것을 목표로합니다.
- Parsing-Prickly-PDFS- 같은 이름의 Nicar 2016 워크숍에 대한 리소스 및 워크 시트
- PDF-TEXT-EXTRACTION-BENCHMARM-PDF 도구 벤치 마크
- 태어난 디지털 PDF 스캐너 - PDF가 태어난 지시 여부를 확인
- OpenContracts OpenContracts Apache2-Licensed, PDF 주석은 원래 레이아웃을 보존하고 토큰에 대한 x, y 위치 데이터를 보존하는 시각적으로 풍부한 문서를위한 PDF 주석을 달성합니다. Pawls를 기반으로하지만 Python 기반 백엔드를 사용하여 로컬 기계, 회사 인트라넷 또는 Docker Compose를 통해 쉽게 배포 할 수 있습니다.
- DeepDoctection Deep Doctection은 딥 러닝 모델을 사용하여 이미지 및 PDF 문서에 대한 문서 추출 및 문서 레이아웃 분석 작업을 조정하는 파이썬 라이브러리입니다. 모델을 구현하지는 않지만 객체 감지, OCR 및 선택된 NLP 작업을 위해 고도로 인정 된 라이브러리를 사용하여 파이프 라인을 구축 할 수 있으며 미세 조정, 평가 및 실행 실행을위한 통합 프레임 워크를 제공합니다.
- pydoxtools pydoxtools는 dpocument 분석을위한 AI 컴포지 라이브러리입니다. 복잡한 문서 분석 파이프 라인을 구축하기위한 광범위한 도구 세트를 특징으로하며 대부분의 문서 형식을 상자에서 인식합니다. 키워드, 요약, Question_answering과 같은 일반적인 NLP 작업을 지원합니다. 고품질 저 CPU/메모리 테이블 추출 알고리즘을 특징으로하며 클러스터에서 NLP 배치 작업을 쉽게 만듭니다.
회의, 워크샵
위로 돌아갑니다
일반 / 비즈니스 / 금융
- 문서 분석 및 인식에 관한 국제 회의 (ICDAR) [2021, 2019, 2017]
- 문서 인텔리전스 워크숍 (DI) [2021, 2019]
- 금융 내러티브 처리 워크숍 (FNP) [2021, 2020, 2019]
- 경제 및 자연어 처리에 관한 워크숍 (ECONLP) [2021, 2019, 2018]
- 문서 분석 시스템에 관한 국제 워크숍 (DAS) [2020, 2018, 2016]
- 금융 AI에 관한 ACM 국제 회의 (ICAIF)
- 금융 서비스의 구조화되지 않은 데이터에서 지식 발견에 관한 AAAI-21 워크숍
- CVPR 2020 딥 러닝 시대의 텍스트 및 문서에 대한 워크숍
- 금융의 기계 학습에 관한 KDD 워크숍 (KDD MLF 2020)
- Finir 2020 : 금융 정보 검색에 관한 첫 번째 워크숍
- 금융의 이상 탐지에 관한 2 차 KDD 워크숍 (KDD 2019)
- 문서 이해 회의 (DUC 2007)
과학적 문서 이해
- 과학 문서 이해에 관한 AAAI-21 워크숍 (SDU 2021)
- 학술 문서 처리에 대한 첫 번째 워크숍 (SDPROC 2020)
- 과학 문서 분석에 관한 국제 워크숍 (SCIDOCA) [2020, 2018, 2017]
블로그
위로 돌아갑니다
- 문서 이해 모델에 대한 조사, 2021
- 문서 양식 추출, 2021
- 구조화되지 않은 데이터로 프로세스를 자동화하는 방법, 2021
- RPA 및 문서 이해가있는 OCR에 대한 포괄적 인 안내서, 2021
- 그래프 컨볼 루션 네트워크를 사용한 영수증으로부터의 정보 추출, 2021
- 송장에서 구조화 된 데이터를 추출하는 방법, 2021
- 템플릿 문서에서 구조화 된 데이터 추출, 2020
- 양호한 AI를 적용하려면 양식 추출, 2020을 생각해보십시오
- UIPATH 문서 솔루션 아키텍처 및 접근 이해, 2020
- 복잡한 문서에서 데이터 추출을 자동화하려면 어떻게해야합니까?, 2020
- LegalTech : 법률 문서의 정보 추출, 2020
솔루션
위로 돌아갑니다
대기업 :
- 애비
- Accenture
- 아마존
- Google
- 마이크로 소프트
- uipath
더 작은 :
- applica.ai
- base64.ai
- Docstack
- 요소 ai
- 인디코
- Instabase
- Konfuzio
- 메타 제
- 나노 넷
- 로섬
- 사일로
예
시각적으로 풍부한 문서
위로 돌아갑니다
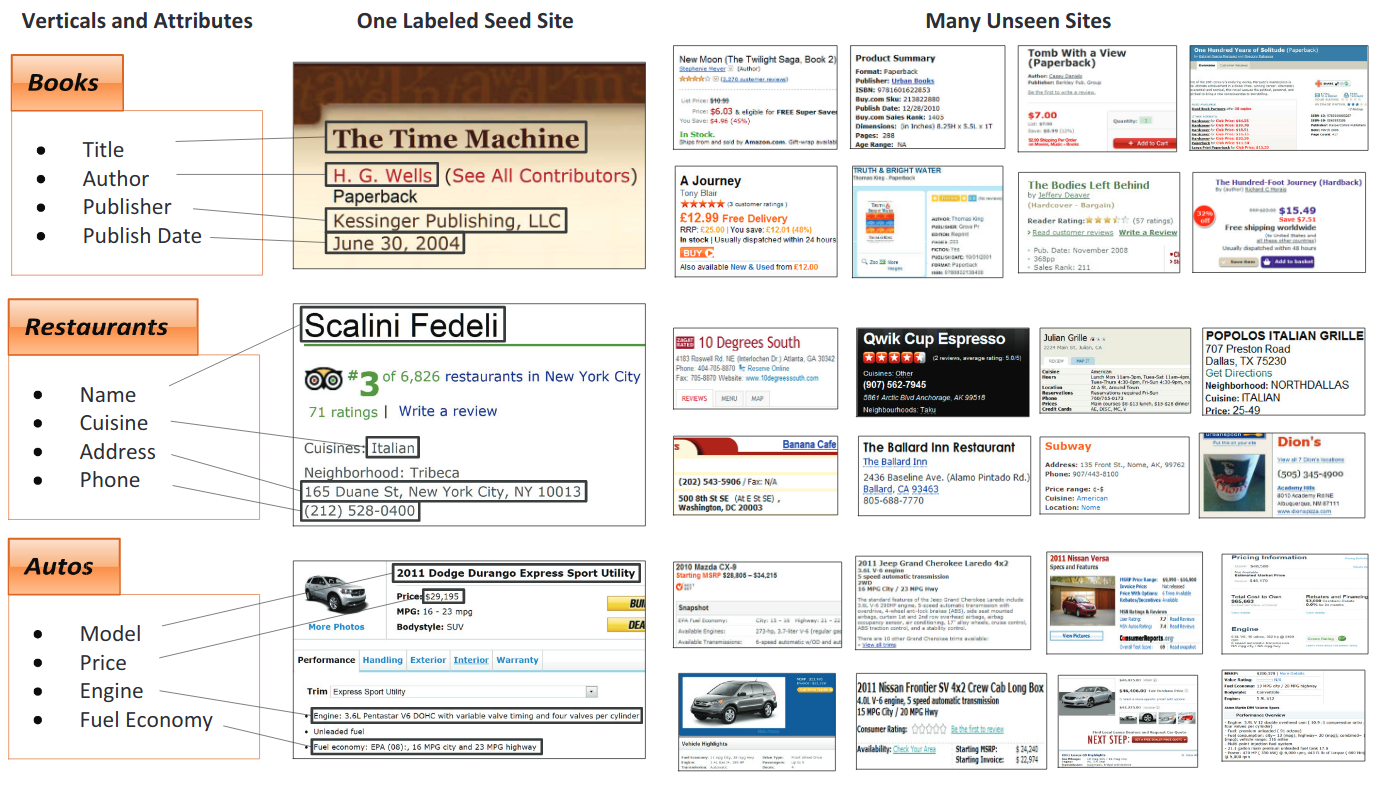
VRD에서는 레이아웃 정보의 중요성이 전체 문서를 올바르게 이해하는 데 중요합니다 (거의 모든 비즈니스 문서의 경우). 인간의 공간 정보는 가독성을 향상시키고 문서 이해 속도를 향상시킵니다.
송장 / 이력서 / 작업 광고

NDA / 연례 보고서

주요 정보 추출
위로 돌아갑니다
이 작업의 목표는 유사한 주요 엔티티를 포함하는 주어진 문서 모음에서 여러 주요 필드의 텍스트를 추출하는 것입니다.
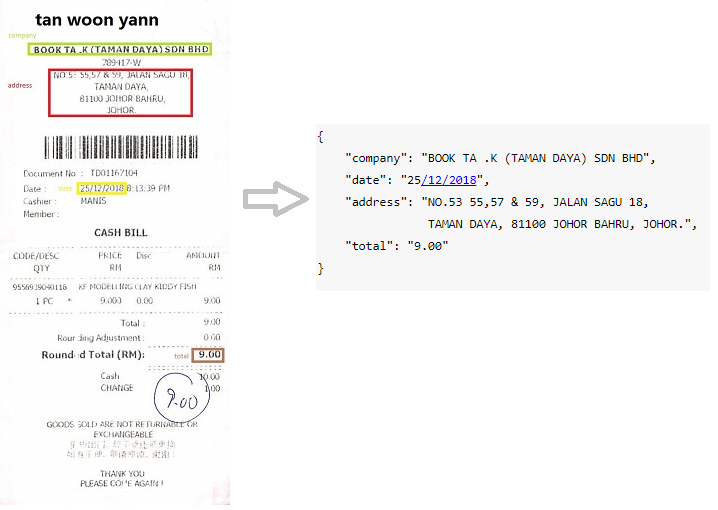
스캔 된 영수증
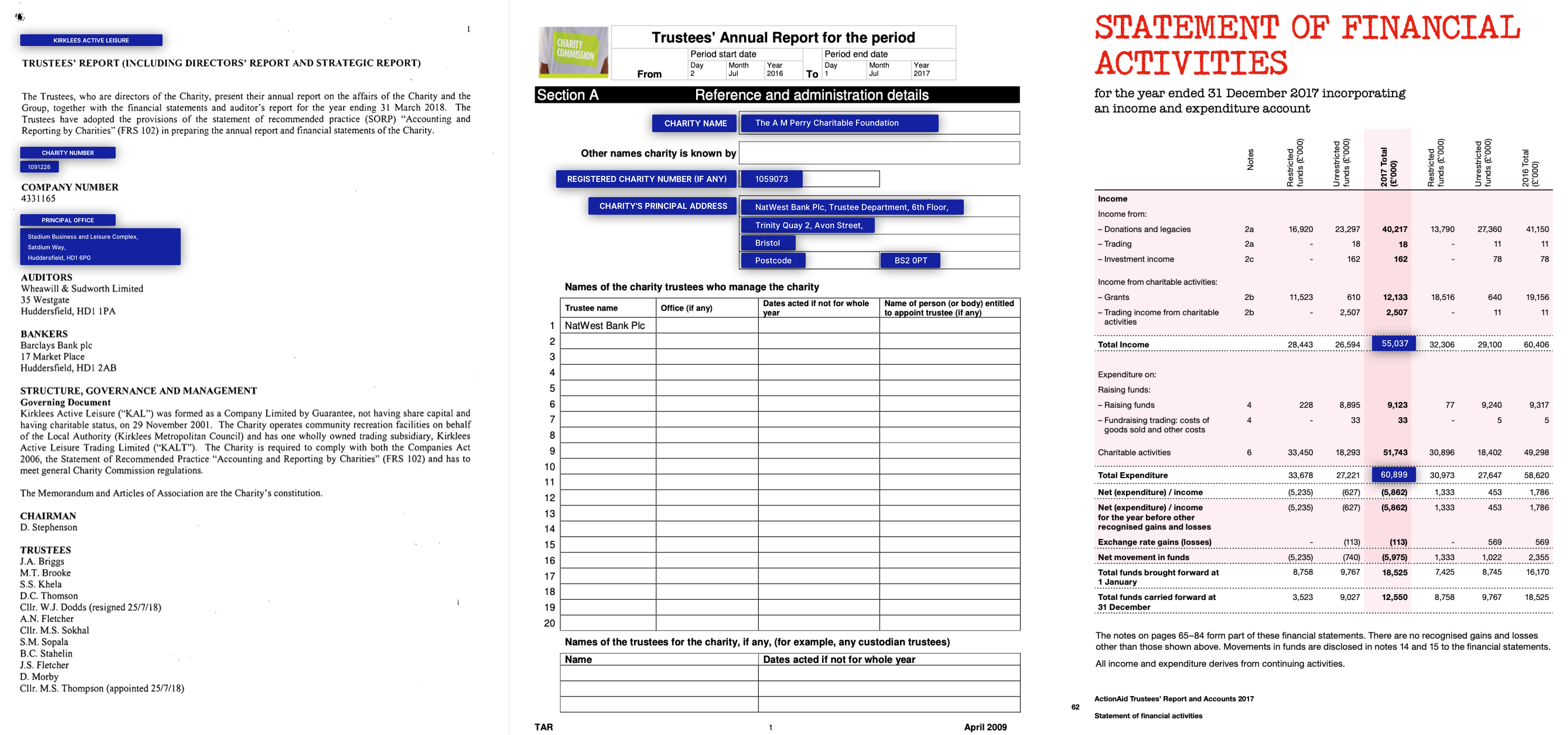
NDA / 연례 보고서
Kleister 데이터 세트의 실제 비즈니스 응용 프로그램 및 데이터의 예 (주요 엔티티는 파란색입니다)
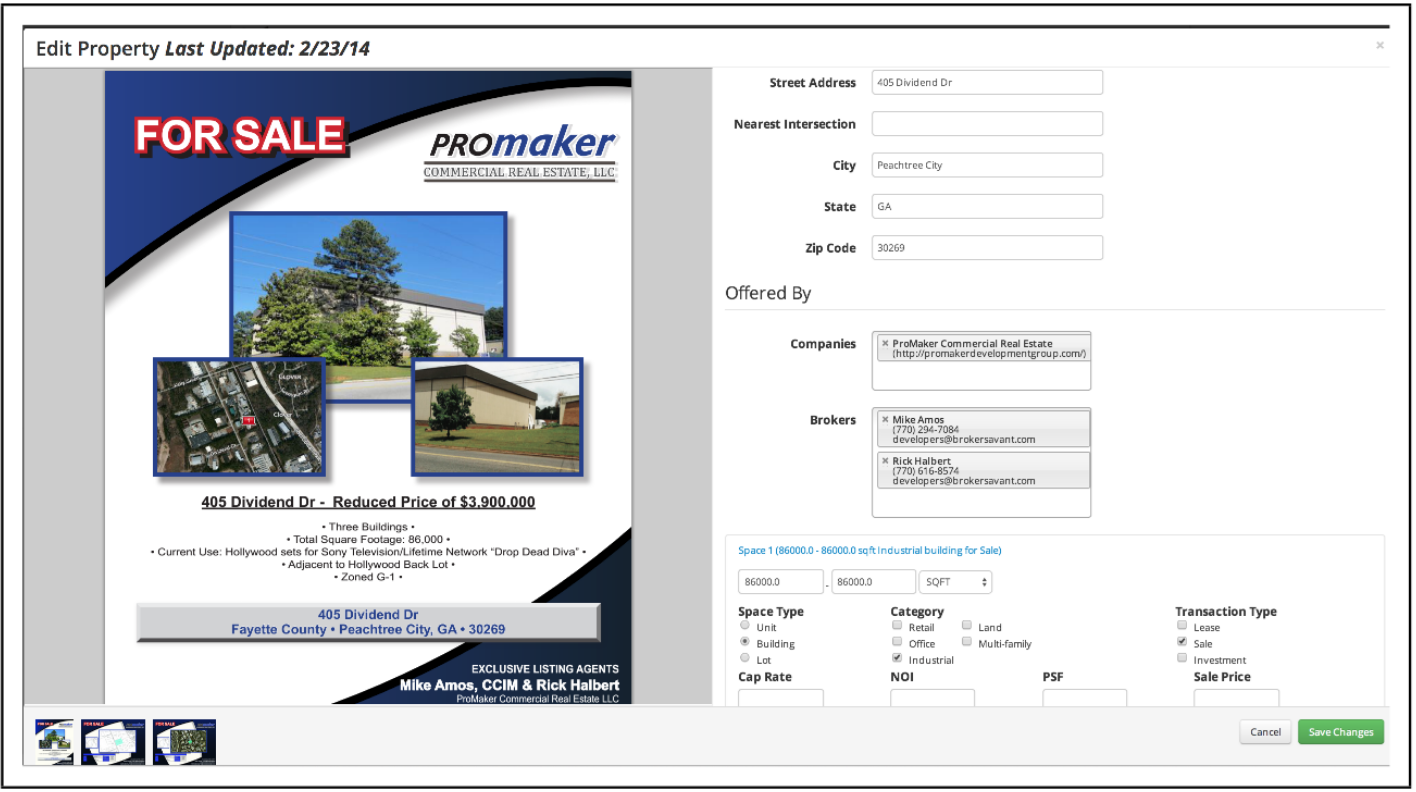
멀티미디어 온라인 전단지
상업용 부동산 전단지 및 수동으로 입력 된 목록 정보의 예 © Promaker Commercial Real Estate LLC, © Brokersavant Inc.
부가가치 세금 송장

웹 페이지
문서 레이아웃 분석
위로 돌아갑니다
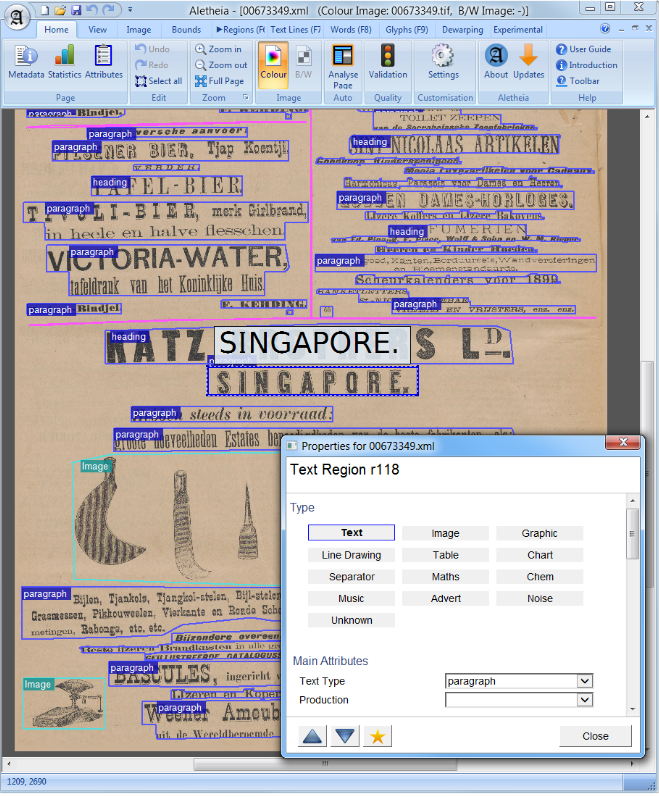
컴퓨터 비전 또는 자연어 처리에서 문서 레이아웃 분석은 텍스트 문서의 스캔 이미지에서 관심있는 영역을 식별하고 분류하는 프로세스입니다. 읽기 시스템은 텍스트 영역에서 텍스트 영역을 세분화하고 올바른 읽기 순서로 배열이 필요합니다. 문서에 내장 된 텍스트 본문, 그림, 수학 기호 및 테이블로서 다른 영역 (또는 블록)의 탐지 및 라벨링을 기하학적 레이아웃 분석이라고합니다. 그러나 텍스트 영역은 문서 내에서 다른 논리적 역할 (제목, 캡션, 각주 등)을 재생하며 이러한 종류의 의미 론적 라벨링은 논리적 레이아웃 분석의 범위입니다. (https://en.wikipedia.org/wiki/document_layout_analysis)
과학 간행물
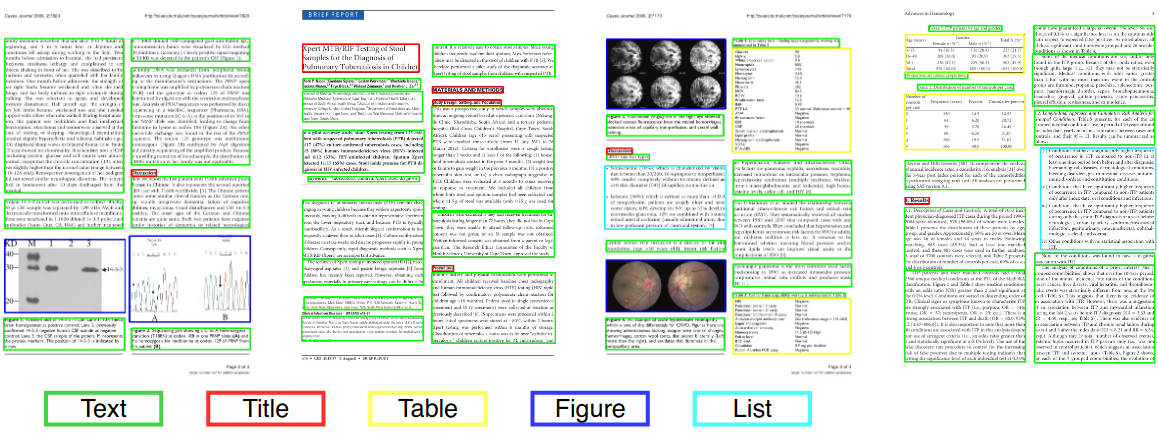

역사적 신문
비즈니스 문서
빨간색 : 텍스트 블록, 파란색 : 그림.

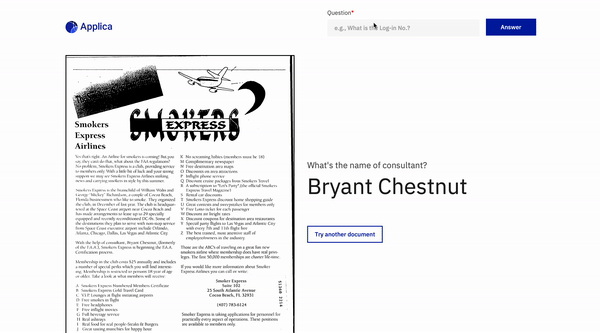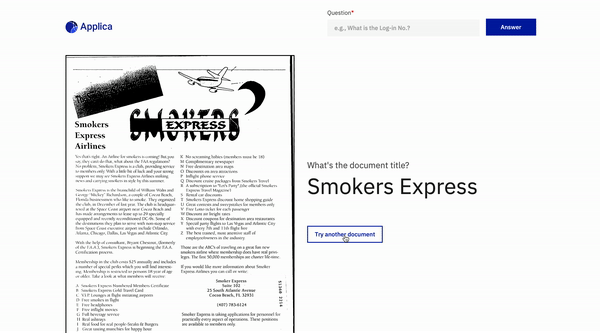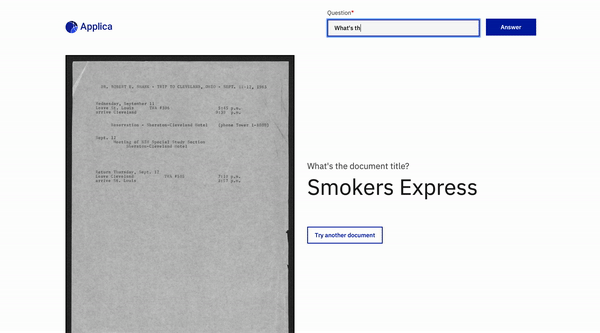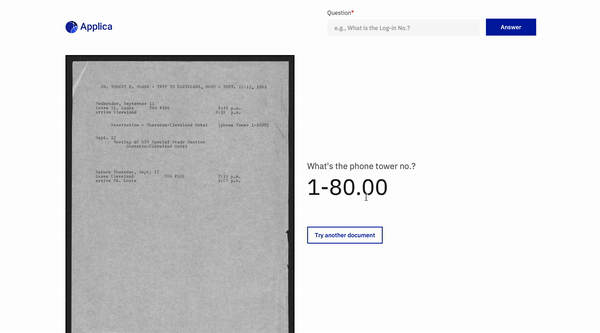
문서 질문 답변
위로 돌아갑니다
DOCVQA 예

틸트 모델 데모
영감
위로 돌아갑니다
도메인
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentlayoutanalysis
- https://github.com/bikash/documentunderstanding
- https://github.com/harpribot/awesome-information-reverieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity-related-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
일반 AI/DL/ml
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awoome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesomecomputer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


