素晴らしいドキュメントの理解
非構造化データからのロボットプロセス自動化(RPA)に関連するインテリジェントドキュメント処理(IDP)に関連するドキュメント理解(DU)トピックのリソースのキュレーションリスト、特に視覚的に豊富なドキュメント(VRD)が形成されます。
注1:太字の位置は他の位置よりも重要です。
注2:フィールドの斬新さにより、このリストは建設中です - 貢献は歓迎されます(事前にありがとう!)。次のコンベンションを使用することを忘れないでください:
- 出版物 /データセット /リソースタイトルのタイトル、[コード /データ /ウェブサイト]
著者会議/日記名のリスト
データセットサイズ:トレーニング(例なし)、開発(例なし)、テスト(例なし)[データセットペーパー/リソースのオプション];要約/短い説明...
目次
- 導入
- 研究トピック
- キー情報抽出(KIE)
- ドキュメントレイアウト分析(DLA)
- ドキュメント質問応答(DQA)
- 科学文書の理解(SDU)
- 光学文字認識(OCR)
- 関連している
- 一般的な
- 表形式データ理解(TDC)
- ロボットプロセスオートメーション(RPA)
- その他
- リソース
- トレーニング前の言語モデルのデータセット
- PDF処理ツール
- 会議 /ワークショップ
- ブログ
- ソリューション
- 例
- 視覚的に豊富なドキュメント(VRDS)
- キー情報抽出(KIE)
- ドキュメントレイアウト分析(DLA)
- ドキュメント質問応答(DQA)
- インスピレーション
導入
文書は、とりわけ、法律、金融、テクノロジーなど、多くの分野の多くの企業の中心的な部分です。請求書、契約、履歴書などのドキュメントの自動理解は有利であり、多くの新しいビジネスの道を開きます。自然言語処理とコンピュータービジョンの分野は、深い学習の開発を通じて大きな進歩を遂げており、これらの方法が現代の文書理解システムに注入され始めています。ソース
論文
2023
- ドキュメント情報のローカリゼーションと抽出のための従順なベンチマーク、[Webサイト] [ベンチマーク] [コード]
štěpánšimsa、ミラノšulc、ミカル・ウーチャチャ、ヤシュ・パテル、アーメド・ハムディ、マティ・ジ・コシアン、マティヤシュ・スカリッキー、ジージ・マタス、アントワーヌ・ドゥセット、ミッカル・クストティ、ディモステニス・カラトザス・カラツァス・アルクシブ・プリント2023
このペーパーでは、主要な情報のローカリゼーションと抽出およびラインアイテムの認識のタスクに関するビジネスドキュメントの最大のデータセットを使用して、従順なベンチマークを紹介します。 6.7kの注釈付きのビジネスドキュメント、合成された100kの合成文書、および監視されていない事前トレーニング用の約1mの非標識ドキュメントが含まれています。データセットは、ドメインおよびタスク固有の側面の知識を持って構築されているため、次の主要な機能が得られます。(i)55クラスの注釈は、以前に公開された主要な情報抽出データセットの粒度を大きなマージンで上回ります。 (ii)ラインアイテム認識は、テーブル内のアイテムに重要な情報を割り当てる必要がある非常に実用的な情報抽出タスクを表します。 (iii)ドキュメントは多数のレイアウトからのものであり、テストセットにはゼロおよび少ないショットのケースと、トレーニングセットで一般的に見られるレイアウトが含まれます。ベンチマークには、Roberta、LayoutlMv3、Detrベースのテーブルトランスなど、いくつかのベースラインが付属しています。これらのベースラインモデルは、従順なベンチマークの両方のタスクに適用され、このペーパーでは結果が共有され、将来の作業のための簡単な出発点が提供されました。データセットとベースラインは、このHTTPS URLで利用できます。
2022
2021
2020
2018年
- ビジネスドキュメントの自動処理の将来のパラダイム
Matteo Cristania、Andrea Bertolasob、Simone Scannapiecoc、Claudio Tomazzolia International Journal of Information Management 2018
この論文では、ビジネスドキュメントに適用される自動処理技術の開発に関心のあるコミュニティでこれまでに得られた結果を要約し、それらの技術の現在の段階でも、それ自体または副次セクターの進歩によって要求されるいくつかの進化を考案します。過去30年間に大きく変化した問題を解決するために多大な努力を払っており、現在ではドキュメント処理をワークフロー管理システムに組み込み、もう一方の側面にクラウドコンピューティングテクノロジーの導入によって導出された機能を含めるようになったフィールドの明確な絵が登場します。上記の2つの進化線から生じるビジネスドキュメント処理のための建築スキーマを提案します。
年上
研究トピック
- キー情報抽出(KIE)
- ドキュメントレイアウト分析(DLA)
- ドキュメント質問応答(DQA)
- 科学文書の理解(SDU)
- 光学キャラクターのレコーオン(OCR)
- 関連している
- 一般的な
- 表形式データ理解(TDC)
- ロボットプロセスオートメーション(RPA)
その他
リソース
トップに戻ります
トレーニング前の言語モデルのデータセット
- RVL -CDIPデータセット - データセットは、16のクラスで400,000のグレースケール画像で構成され、クラスごとに25,000の画像があります
- 業界文書ライブラリ - UCSFライブラリがホストする公衆衛生に影響を与える業界によって作成された数百万の文書へのポータル
- カラードキュメントデータセット - アムステルダム大学のインテリジェント感覚情報システムから
- IIT CDIPコレクション - データセットは、1990年代のタバコ産業に対する州の訴訟からの文書で構成されており、約700万の文書で構成されています
PDF処理ツール
- Borb- PDFドキュメントを読み、書き、操作するための純粋なPythonライブラリです。これは、ネストされたリスト、辞書、プリミティブのJSONのようなデータストラクチャとしてのPDFドキュメントを表しています(数字、文字列、ブール人など)。
- PAWLS -PDFラベルと構造を使用したPDFアノテーションは、PDFドキュメントに関連付けられた一連の注釈を簡単に収集できるソフトウェアです
- pdfplumber -各テキスト文字、長方形、および行の詳細については、PDFを配置します。プラス:テーブル抽出と視覚デバッグ
- pdfminer.six -pdfminer.sixは、元のpdfminerのコミュニティに維持されているフォークです。これは、PDFドキュメントから情報を抽出するためのツールです。テキストデータの取得と分析に焦点を当てています
- レイアウトパーサー - レイアウトパーサーは、ドキュメント画像レイアウト分析タスクのためのディープラーニングベースのツールです
- Tabulo-画像からのテーブル抽出
- ocrmypdf -ocrmypdfは、スキャンされたPDFファイルにOCRテキストレイヤーを追加し、検索またはコピーペストを作成できるようにします
- PDFBOX -Apache PDFBoxライブラリは、PDFドキュメントを操作するためのオープンソースJavaツールです。このプロジェクトにより、新しいPDFドキュメントの作成、既存のドキュメントの操作、およびドキュメントからコンテンツを抽出する機能が可能になります
- PDFPIG-このプロジェクトを使用すると、ユーザーはPDFファイルからテキストやその他のコンテンツを読み取り、抽出できます。さらに、ライブラリを使用して、テキストと幾何学的な形状を含む簡単なPDFドキュメントを作成できます。このプロジェクトは、PDFBOXをC#に移植することを目指しています
- Parsing-Prickly-PDFS-同じ名前のNicar 2016ワークショップのリソースとワークシート
- PDF-Text-Extraction-Benchmark-PDFツールベンチマーク
- 生まれたデジタルPDFスキャナー - PDFが生まれているかどうかを確認する
- OpenContracts Apache2ライセンスのPDF注釈プラットフォームは、元のレイアウトを保持し、トークンのX、Yの位置データをエクスポートし、スパンの開始と停止を展開します。 Pawlsに基づいていますが、Pythonベースのバックエンドがあり、ローカルマシン、Company Intranet、またはWebにDocker Composeを介して簡単に展開できます。
- DeepDoctection Deep Dectionは、ドキュメント抽出およびドキュメントレイアウト分析タスクを、深い学習モデルを使用してPDFドキュメントのドキュメントレイアウト分析タスクを調整するPythonライブラリです。モデルを実装するのではなく、オブジェクト検出、OCR、選択されたNLPタスクのために強く認められたライブラリを使用してパイプラインを構築でき、微調整、評価、ランニングモデルの統合フレームワークを提供します。
- Pydoxtools pydoxtoolsは、dpocument分析用のAIコンポジションライブラリです。複雑なドキュメント分析パイプラインを構築するための広範なツールセットを備えており、ほとんどのドキュメント形式を箱から出して認識しています。キーワード、要約、質問_などの典型的なNLPタスクをサポートしています。高品質の低CPU/メモリテーブル抽出アルゴリズムを備えており、クラスターでのNLPバッチ操作を簡単にします。
会議、ワークショップ
トップに戻ります
一般 /ビジネス /財務
- 文書分析と認識に関する国際会議(ICDAR) [2021、2019、2017]
- ドキュメントインテリジェンスに関するワークショップ(DI)[2021、2019]
- 金融物語加工ワークショップ(FNP)[2021、2020、2019]
- 経済学と自然言語処理に関するワークショップ(ECONLP)[2021、2019、2018]
- ドキュメント分析システムに関する国際ワークショップ(DAS)[2020、2018、2016]
- ACM International Conference on AI in Finance(ICAIF)
- 金融サービスの構造化されていないデータからの知識発見に関するAAAI-21ワークショップ
- CVPR 2020ディープラーニング時代のテキストとドキュメントに関するワークショップ
- 金融の機械学習に関するKDDワークショップ(KDD MLF 2020)
- Finir 2020:金融の情報検索に関する最初のワークショップ
- 財務における異常検出に関する第2 KDDワークショップ(KDD 2019)
- 文書理解会議(DUC 2007)
科学文書の理解
- 科学文書理解に関するAAAI-21ワークショップ(SDU 2021)
- 学術文書処理に関する最初のワークショップ(SDPROC 2020)
- 科学文書分析に関する国際ワークショップ(SCIDOCA)[2020、2018、2017]
ブログ
トップに戻ります
- 文書理解モデルの調査、2021
- ドキュメントフォーム抽出、2021
- 非構造化データでプロセスを自動化する方法、2021
- RPAとドキュメントの理解を伴うOCRの包括的なガイド、2021
- グラフ畳み込みネットワークを備えた領収書からの情報抽出、2021
- 請求書から構造化されたデータを抽出する方法、2021
- テンプラティックドキュメントから構造化データの抽出、2020
- AIを適切に適用するには、2020年のフォーム抽出を考えてください
- Uipath文書の理解ソリューションアーキテクチャとアプローチ、2020
- 複雑なドキュメントからデータ抽出を自動化するにはどうすればよいですか?、2020
- LegalTech:法的文書での情報抽出、2020
ソリューション
トップに戻ります
大企業:
- アビー
- アクセンチュア
- アマゾン
- グーグル
- マイクロソフト
- uipath
小さい:
- Applica.ai
- base64.ai
- docstack
- 要素AI
- インド
- Instabase
- Konfuzio
- メタマーズ
- ナノネット
- ロッサム
- サイロ
例
視覚的に豊富なドキュメント
トップに戻ります
VRDSでは、レイアウト情報の重要性は、ドキュメント全体を正しく理解するために重要です(これは、ほとんどすべてのビジネスドキュメントの場合です)。人間の場合、空間情報は読みやすさを向上させ、ドキュメントの理解を速くします。
請求書 /履歴書 /ジョブ広告

NDA /年次報告書

重要な情報抽出
トップに戻ります
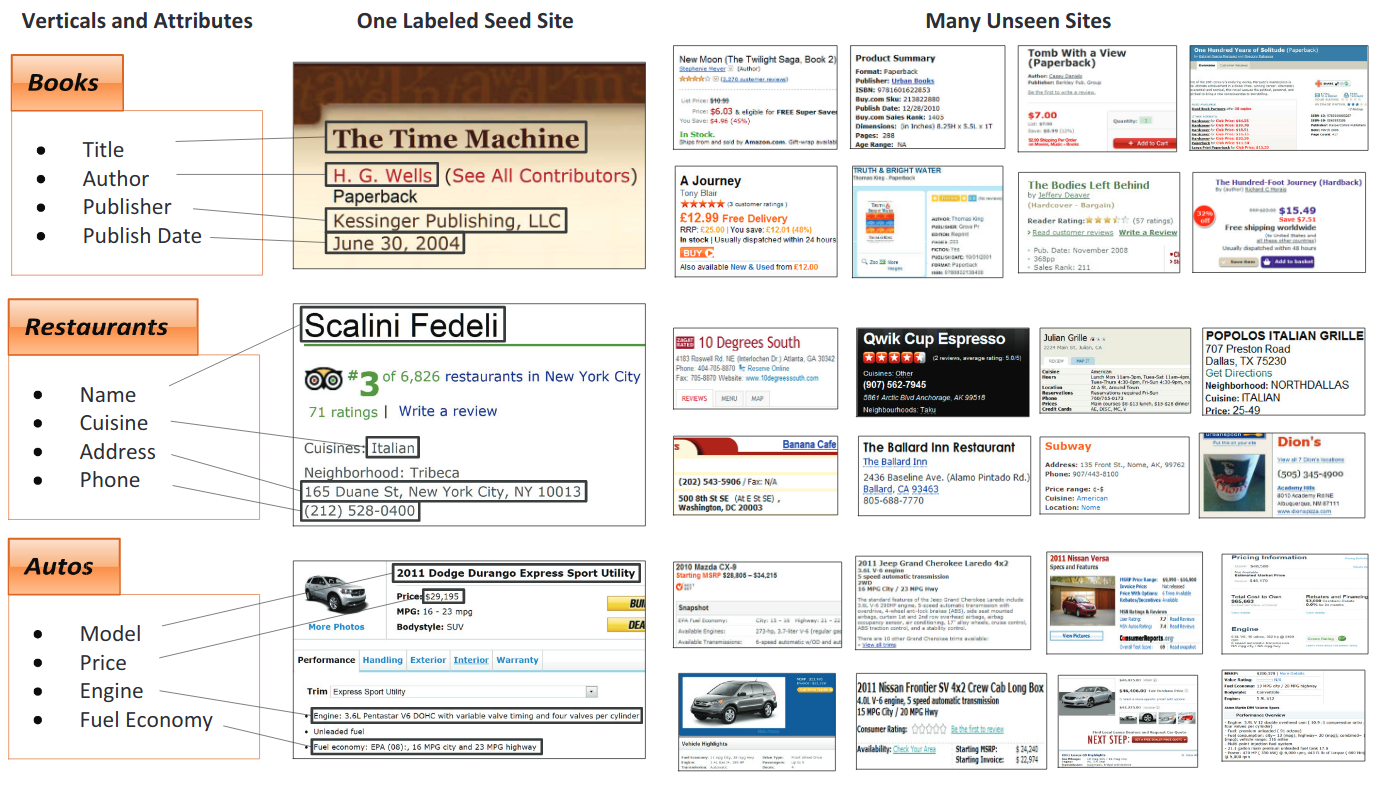
このタスクの目的は、同様の重要なエンティティを含むドキュメントの特定のコレクションから多くの重要なフィールドのテキストを抽出することです。
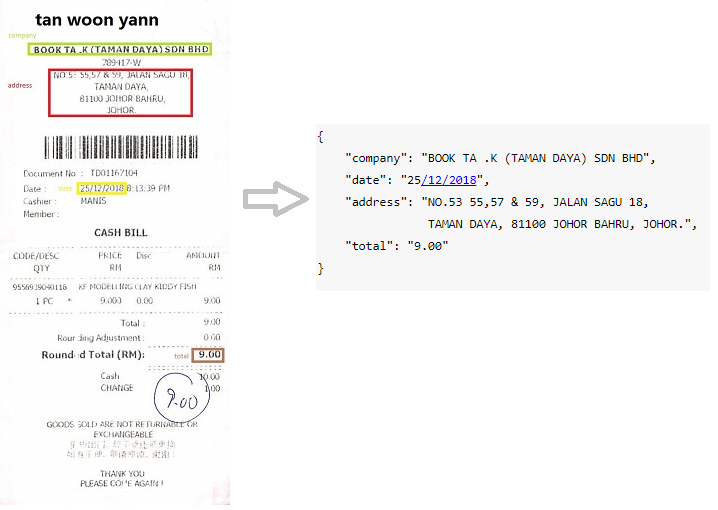
スキャンされた領収書
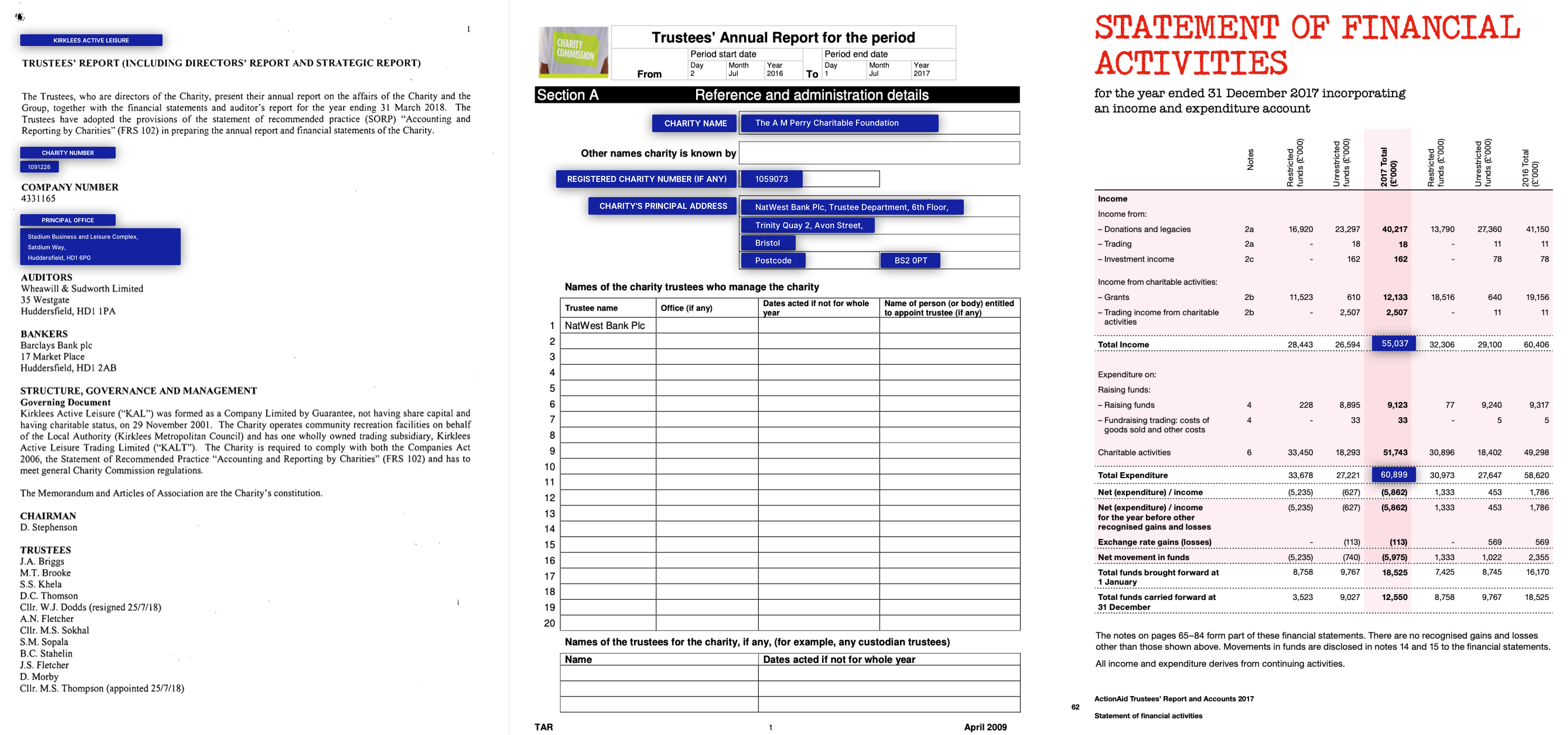
NDA /年次報告書
Kleisterデータセットの実際のビジネスアプリケーションとデータの例(重要なエンティティは青です)
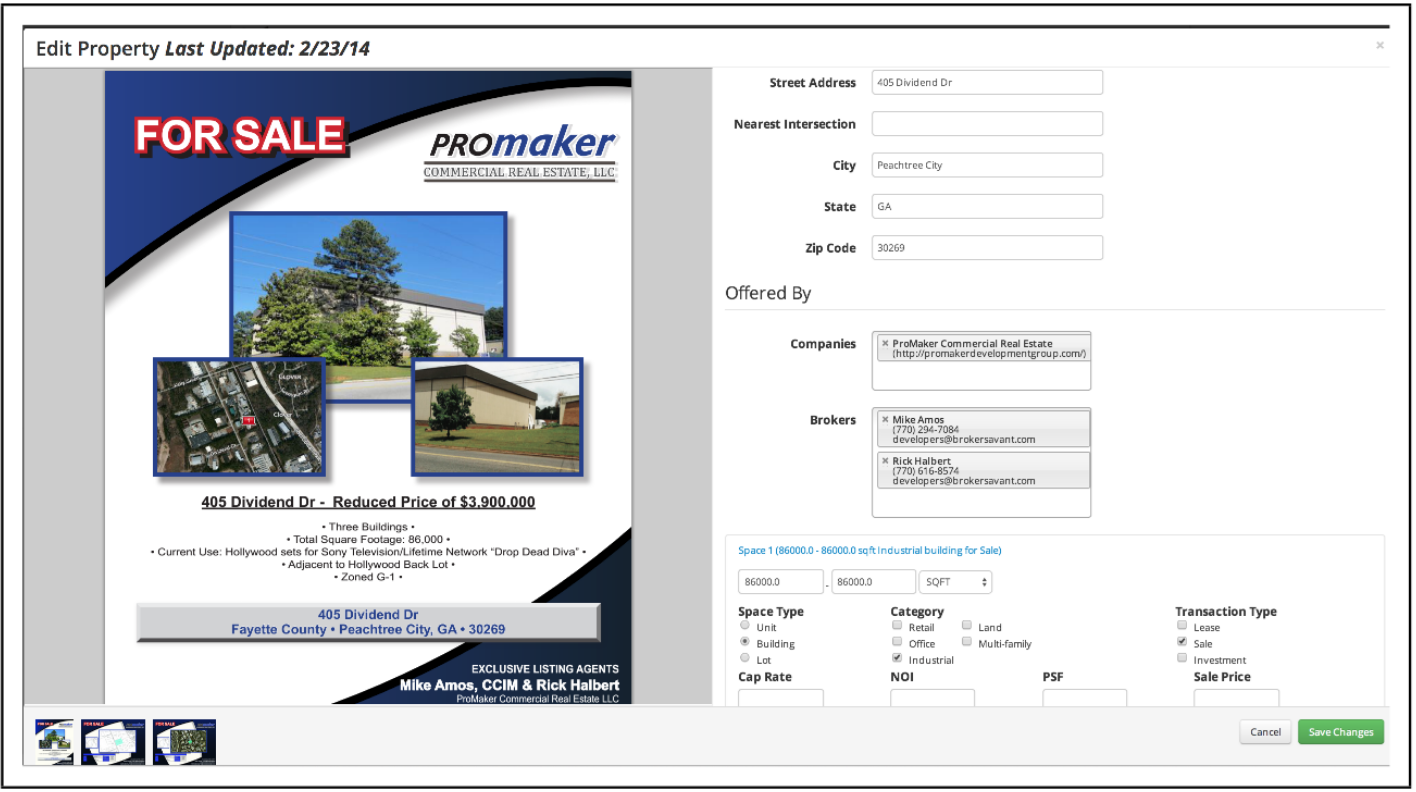
マルチメディアオンラインチラシ
商業用不動産チラシの例と手動で入力されたリスト情報©Promaker Commercial Real Estate LLC、©BrokerSavant Inc.
付加価値税の請求書

ウェブページ
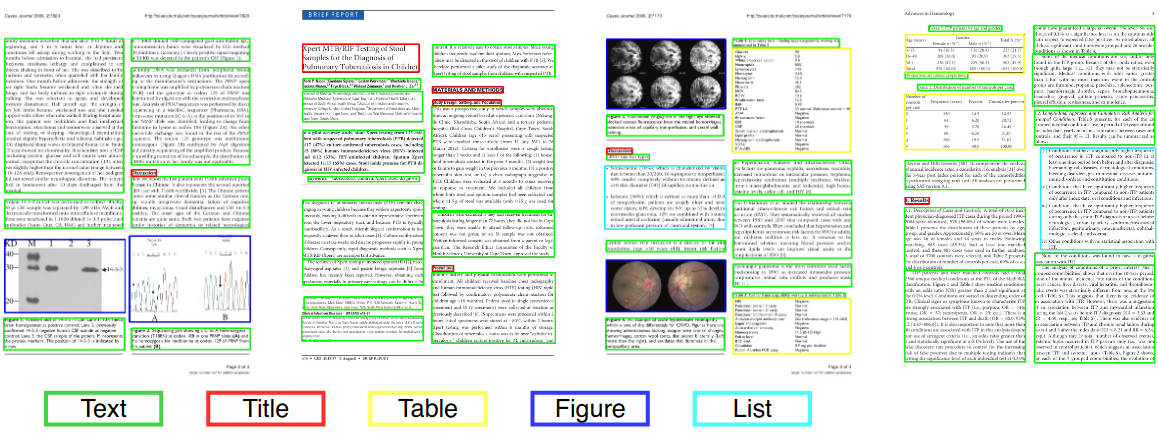
ドキュメントレイアウト分析
トップに戻ります
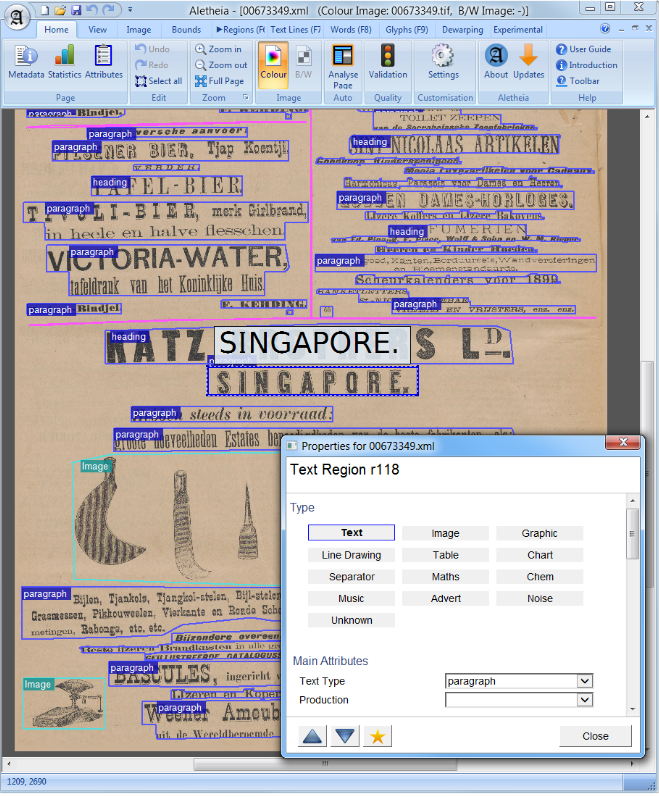
コンピュータービジョンまたは自然言語処理では、ドキュメントレイアウト分析は、テキストドキュメントのスキャンされた画像で関心のある領域を識別および分類するプロセスです。読み取りシステムでは、テキストゾーンからのテキストゾーンのセグメンテーションと、正しい読み取り順序での配置が必要です。ドキュメントに埋め込まれたテキスト本体、イラスト、数学記号、およびテーブルとしての異なるゾーン(またはブロック)の検出とラベル付けは、幾何学的レイアウト分析と呼ばれます。しかし、テキストゾーンはドキュメント内で異なる論理的役割(タイトル、キャプション、脚注など)を再生し、この種のセマンティックラベルは論理レイアウト分析の範囲です。 (https://en.wikipedia.org/wiki/document_layout_analysis)
科学出版物

歴史的な新聞
ビジネス文書
赤:テキストブロック、青:図。

ドキュメント質問応答
トップに戻ります
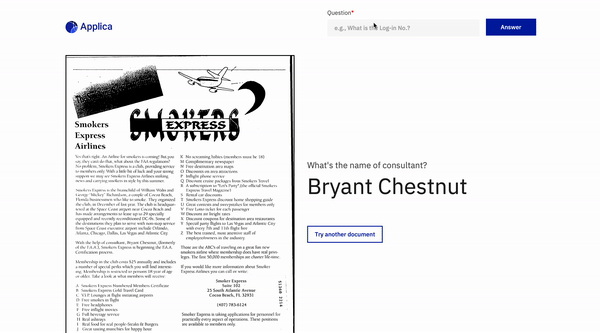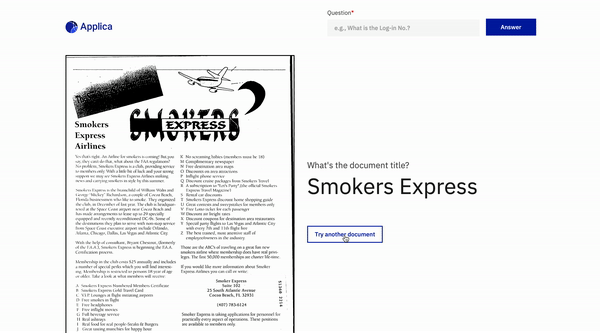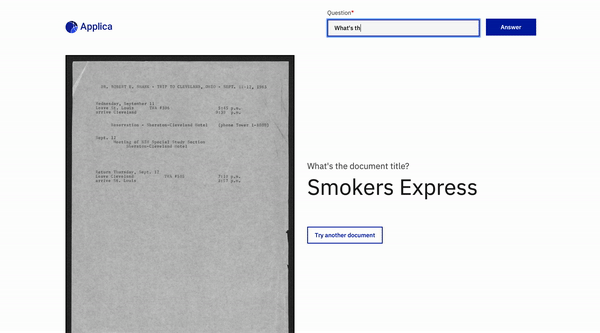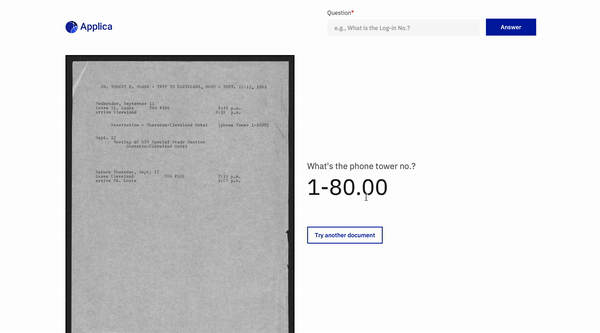
docvqaの例

チルトモデルデモ
インスピレーション
トップに戻ります
ドメイン
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentlayoutanalysis
- https://github.com/bikash/documentunderstanding
- https://github.com/harpribot/awesome-information-retrieval
- https://github.com/roomylee/awesome-lesation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/Entity--関連ペイパー
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
一般的なAI/DL/ML
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-rearning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automl-papers


