Fantastisches Dokumentverständnis
Eine kuratierte Liste von Ressourcen für das Thema Dokumentverständnis (DU), das sich auf die intelligente Dokumentenverarbeitung (IDP) bezieht, die im Verhältnis zur Roboterprozessautomatisierung (RPA) aus unstrukturierten Daten, insbesondere aus visuell reichhaltigen Dokumenten (VRDs), steht.
Anmerkung 1: Fettdrucke Positionen sind wichtiger als andere.
Anmerkung 2: Aufgrund der Neuheit des Feldes befindet sich diese Liste im Bau - Beiträge sind willkommen (danke im Voraus!). Bitte denken Sie daran, die folgende Konvention zu verwenden:
- Titel einer Veröffentlichung / Datensatz / Ressourcentitel, [Code / Daten / Website]
Liste der Autorenkonferenz/Journal -Namensjahr
Datensatzgröße: Zug (Nein von Beispielen), Dev (Nein von Beispielen), Test (Nein von Beispielen) [optional für Datensatzpapiere/Ressourcen]; Zusammenfassung/kurze Beschreibung ...
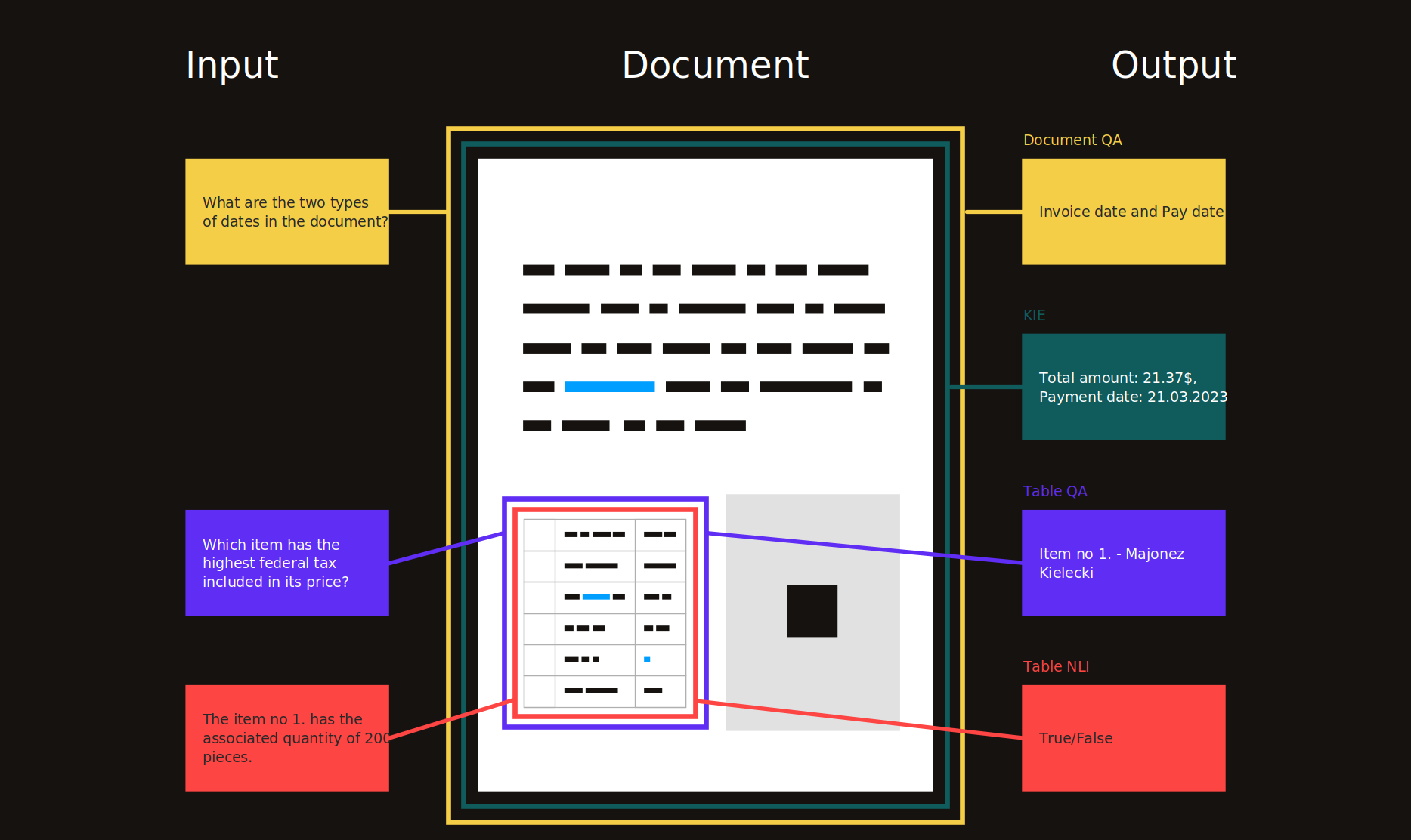
Inhaltsverzeichnis
- Einführung
- Forschungsthemen
- Schlüsselinformationsextraktion (KIE)
- Dokumentlayoutanalyse (DLA)
- Beantwortung von Dokumentfragen (DQA)
- Wissenschaftliches Dokumentverständnis (SDU)
- Optische Charaktererkennung (OCR)
- Verwandt
- Allgemein
- Tabelle Datenverständnis (TDC)
- Roboterprozessautomatisierung (RPA)
- Andere
- Ressourcen
- Datensätze für Sprachmodelle vor dem Training
- PDF -Verarbeitungstools
- Konferenzen / Workshops
- Blogs
- Lösungen
- Beispiele
- Visuell reiche Dokumente (VRDs)
- Schlüsselinformationsextraktion (KIE)
- Dokumentlayoutanalyse (DLA)
- Beantwortung von Dokumentfragen (DQA)
- Inspirationen
Einführung
Dokumente sind unter anderem ein zentraler Bestandteil vieler Unternehmen in vielen Bereichen wie Recht, Finanzierung und Technologie. Das automatische Verständnis von Dokumenten wie Rechnungen, Verträgen und Lebensläufen ist lukrativ und eröffnet viele neue Geschäftswege. Die Bereiche der Verarbeitung natürlicher Sprache und der Computer Vision haben durch die Entwicklung des Deep -Lernens einen enormen Fortschritt verzeichnet, so dass diese Methoden in zeitgenössischen Dokumentenverständnissystemen infundiert wurden. Quelle
Papiere
2023
- Lebende Benchmark für die Lokalisierung und Extraktion von Dokumenteninformationen, [Website] [Benchmark] [Code]
Štěpán Šimsa, Mailand Šulc, Michal uřičář, Yash Patel, Ahmed Hamdi, Matěj Kocián, Matyáš Skalický, Jiří Matas, Antoine Doucet, Mickaël Coustaty, Dimosthenis karatzas Arxiv Pre-Pint 2023
In diesem Artikel wird der fügsame Benchmark mit dem größten Datensatz von Geschäftsdokumenten für die Aufgaben der wichtigsten Informationslokalisierung und -Extraktion und Werbekenntnisse vorgestellt. Es enthält 6,7K-kommentierte Geschäftsdokumente, synthetisch generierte Dokumente von 100K und fast ~ 1 m unmarkierte Dokumente für unbeaufsichtigte Voraussetzungen. Der Datensatz wurde mit Kenntnissen der domänen- und aufgabenspezifischen Aspekte erstellt, was zu den folgenden Schlüsselmerkmalen führt: (i) Annotationen in 55 Klassen, die die Granularität zuvor veröffentlichter Datensätze der wichtigsten Informationsextraktion mit großem Rand übertreffen. (ii) Werbemerkennung stellt eine hochpraktische Aufgabe zur Extraktion von Informationen dar, bei der Schlüsselinformationen Elementen in einer Tabelle zugewiesen werden müssen. (iii) Dokumente stammen aus zahlreichen Layouts, und der Testsatz enthält Null- und wenige Fälle sowie Layouts, die häufig im Trainingssatz zu sehen sind. Der Benchmark verfügt über mehrere Baselines, darunter Roberta, Layoutlmv3 und DETR-basierte Tabellentransformator. Diese Basismodelle wurden auf beide Aufgaben des fügsamen Benchmarks angewendet, wobei die Ergebnisse in diesem Artikel geteilt wurden und einen kurzen Ausgangspunkt für zukünftige Arbeiten bieten. Die Datensatz und die Basislinien sind in dieser HTTPS -URL verfügbar.
2022
Geschäftsdokumentinformationsextraktion: Auf dem Weg zu praktischen Benchmarks
Matyáš Skalický, Štěpán Šimsa, Michal Uřičář, Mailand Šulc Clef 2022
Die Informationsextraktion aus semi-strukturierten Dokumenten ist entscheidend für die reibungslose Kommunikation (Business-to-Business). Während maschinelle Lernprobleme im Zusammenhang mit der Dokumentinformationsextraktion (IE) seit Jahrzehnten untersucht werden, spiegeln viele gemeinsame Problemdefinitionen und Benchmarks nicht domänenspezifische Aspekte und praktische Anforderungen zur Automatisierung der B2B-Dokumentkommunikation wider. Wir überprüfen die Landschaft des Dokuments, dh Probleme, Datensätze und Benchmarks. Wir heben die praktischen Aspekte hervor, die in den gemeinsamen Definitionen fehlen, und definieren die wichtigsten Probleme der Lokalisierung und Extraktion (KILE) und der LIR -Erkennung (LIR -Erkennung). Es fehlt an relevanten Datensätzen und Benchmarks für Dokumente, dh in semi-strukturierten Geschäftsdokumenten, da der Inhalt in der Regel rechtlich geschützt oder empfindlich ist. Wir diskutieren potenzielle Quellen verfügbarer Dokumente, einschließlich synthetischer Daten. DOC2GRAPH: Eine Aufgabe Agnostisches Dokumentverständnis -Framework basierend auf Grafik Neuronal Networks, [Code]
Andrea Gemelli, Sanket Biswas, Enrico Civitelli, Josep Lladós, Simone Marinai Tie Workshop @ ECCV 2022
Geometrisches Deep Learning hat in letzter Zeit ein wesentliches Interesse an einer Vielzahl von Bereichen für maschinelles Lernen geweckt, einschließlich der Dokumentenanalyse. Die Anwendung von Graph Neural Networks (GNNs) ist bei verschiedenen dokumentbezogenen Aufgaben von entscheidender Bedeutung geworden, da sie wichtige strukturelle Muster entwirren können, was für wichtige Informationsextraktionsprozesse von grundlegender Bedeutung ist. Frühere Arbeiten in der Literatur schlagen aufgabenorientierte Modelle vor und berücksichtigen nicht die volle Leistung von Graphen. Wir schlagen vor, Doc2Graph, ein auf einem GNN-Modell basierendes Rahmen für das Verständnis von Task-Agnostic Dokument, um verschiedene Aufgaben zu lösen, die unterschiedliche Arten von Dokumenten haben. Wir haben unseren Ansatz auf zwei herausfordernden Datensätzen für wichtige Informationen zum Verständnis, zur Analyse von Rechnungslayout und die Erkennung von Tabellen bewertet
2021
Dokument AI: Benchmarks, Modelle und Anwendungen
Lei Cui, Yiheng Xu, Tengchao LV, Furu Wei Arxiv 2021
Dokument AI oder Document Intelligence ist ein relativ neues Forschungsthema, das sich auf die Techniken zum automatischen Lesen, Verständnis und Analysieren von Geschäftsdokumenten bezieht. Es ist eine wichtige Forschungsrichtung für die Verarbeitung natürlicher Sprache und Computer Vision. In den letzten Jahren hat die Popularität der Deep -Learning -Technologie die Entwicklung der Dokument -KI, wie z. B. Dokumentlayoutanalyse, visuelle Informationen, Extraktion, Dokument visuelle Fragenbeantwortung, Dokumentbildklassifizierung usw., erheblich erweitert. In diesem Artikel wird einige der repräsentativen Modelle, Aufgaben und Benchmark -Datensätze kurz überprüft. Darüber hinaus führen wir heuristische regelbasierte Dokumentenanalysen im Frühstadium, statistische Algorithmen für maschinelles Lernen und Deep-Lern-Ansätze vor, insbesondere vor dem Training. Schließlich untersuchen wir zukünftige Richtungen für die Dokument -AI -Forschung. Effiziente automatisierte Verarbeitung der unstrukturierten Dokumente unter Verwendung künstlicher Intelligenz: Eine systematische Literaturübersicht und zukünftige Anweisungen
Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, Ketan Kotecha IEEE Access 2021
Die unstrukturierten Daten wirken sich auf 95% der Organisationen aus und kosten pro Jahr Millionen von Dollar. Wenn es gut geschafft wird, kann dies die Geschäftsproduktivität erheblich verbessern. Die herkömmlichen Informationsextraktionstechniken sind in ihrer Funktionalität begrenzt, aber AI-basierte Techniken können eine bessere Lösung darstellen. In der Literatur fehlt eine gründliche Untersuchung von KI-basierten Techniken zur automatischen Informationsextraktion aus unstrukturierten Dokumenten. Der Zweck dieser systematischen Literaturübersicht (SLR) besteht darin, die Forschung zu den Techniken zu erkennen und zu analysieren, die für die automatische Informationsextraktion aus unstrukturierten Dokumenten verwendet werden und Anweisungen für zukünftige Forschungsergebnisse bereitstellen. Die von Kitchenham und Charters vorgeschlagenen SLR-Richtlinien wurden für eine Literaturrecherche in verschiedenen Datenbanken zwischen 2010 und 2020 eingehalten. Wir fanden heraus, dass die vorhandenen Informationsextraktionstechniken vorlagenbasierte oder regelbasierte, 2. Die vorhandenen Methoden fehlen die Fähigkeit, komplexe Dokumentlayouts in Echtzeit-Situationen zu bekämpfen, in Echtzeit-Situationen wie günstig und günstig. Daher besteht die Notwendigkeit, einen neuen Datensatz zu entwickeln, der reale Probleme widerspiegelt. Unsere SLR stellte fest, dass KI-basierte Ansätze ein starkes Potenzial haben, nützliche Informationen aus unstrukturierten Dokumenten automatisch zu extrahieren. Sie stehen jedoch vor bestimmten Herausforderungen bei der Verarbeitung mehrerer Layouts der unstrukturierten Dokumente. Unsere SLR bringt die Konzeptualisierung eines Rahmens für die Konstruktion hochwertiger unstrukturierter Dokumente mit starken Datenvalidierungstechniken für die automatisierte Informationsextraktion hervor. Unsere SLR zeigt auch die Notwendigkeit eines engen Zusammenhangs zwischen den Unternehmen und Forschern, um verschiedene Herausforderungen der unstrukturierten Datenanalyse zu bewältigen.
2020
2018
- Zukünftige Paradigmen der automatisierten Verarbeitung von Geschäftsdokumenten
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
In diesem Artikel fassen wir die bisherigen Ergebnisse in den Gemeinden zusammen, die sich für die Entwicklung automatisierter Verarbeitungstechniken wie für Geschäftsdokumente interessieren, und entwickeln einige Entwicklungen, die von der aktuellen Stufe dieser Techniken für sich selbst oder durch Fortschritte der Sicherheitensektor gefordert werden. Es entsteht ein klares Bild eines Feldes, das sich enorm anstrengt, Probleme zu lösen, die sich in den letzten 30 Jahren stark verändert haben, und sich nun schnell weiterentwickelt, um die Dokumentverarbeitung in Workflow -Managementsysteme auf einer Seite einzubeziehen und Funktionen zu enthalten, die durch die Einführung von Cloud -Computing -Technologien auf der anderen Seite abgeleitet wurden. Wir schlagen ein architektonisches Schema für die Verarbeitung von Geschäftsdokumenten vor, das aus den beiden oben genannten Evolutionslinien stammt.
Älter
Forschungsthemen
- Schlüsselinformationsextraktion (KIE)
- Dokumentlayoutanalyse (DLA)
- Beantwortung von Dokumentfragen (DQA)
- Wissenschaftliches Dokumentverständnis (SDU)
- OPTISCHE ZEICHNEHME (OCR) (OCR)
- Verwandt
- Allgemein
- Tabelle Datenverständnis (TDC)
- Roboterprozessautomatisierung (RPA)
Andere
Ressourcen
Zurück nach oben
Datensätze für Sprachmodelle vor dem Training
- Der RVL -CDIP -Datensatz - Datensatz besteht aus 400.000 Graustufenbildern in 16 Klassen mit 25.000 Bildern pro Klasse
- Die Branchendokumente Bibliothek - ein Portal zu Millionen von Dokumenten, die von Branchen erstellt wurden, die die öffentliche Gesundheit beeinflussen, die von der UCSF -Bibliothek veranstaltet werden
- Farbdokument -Datensatz - Aus den intelligenten sensorischen Informationssystemen der Universität Amsterdam
- Die IIT CDIP Collection - Dataset besteht aus Dokumenten aus der Klage der Staaten gegen die Tabakindustrie in den neunziger Jahren, besteht aus rund 7 Millionen Dokumenten
PDF -Verarbeitungstools
- BORB - ist eine reine Python -Bibliothek zum Lesen, Schreiben und Manipulieren von PDF -Dokumenten. Es repräsentiert ein PDF-Dokument als JSON-ähnliche Datastruktur von verschachtelten Listen, Wörterbüchern und Primitiven (Zahlen, String, Booleans usw.).
- Pawls - PDF -Anmerkungen mit Etiketten und Struktur ist Software, mit der es einfach ist, eine Reihe von Anmerkungen zu sammeln, die mit einem PDF -Dokument verbunden sind
- PDFPLUMBER - Plumb A PDF für detaillierte Informationen zu jedem Textcharakter, Rechteck und Zeile. Plus: Tabellenextraktion und visuelles Debuggen
- PdfMiner.Six - pdfminer.SIX ist eine Community -Gabel des ursprünglichen PDFMiner. Es ist ein Werkzeug zum Extrahieren von Informationen aus PDF -Dokumenten. Es konzentriert sich darauf, Textdaten zu erhalten und zu analysieren
- Layout -Parser - Layout -Parser ist ein tief lernbasiertes Tool für Dokumentenbild -Layout -Analyseaufgaben
- Tabulo - Tabellenextraktion aus den Bildern
- OCRMYPDF - OCRMYPDF fügt gescannte PDF -Dateien eine OCR -Textebene hinzu, sodass sie durchsucht oder kopiert werden können
- PDFBox - Die Apache PDFBox -Bibliothek ist ein Open -Source -Java -Tool für die Arbeit mit PDF -Dokumenten. Dieses Projekt ermöglicht die Erstellung neuer PDF -Dokumente, die Manipulation vorhandener Dokumente und die Möglichkeit, Inhalte aus Dokumenten zu extrahieren
- PDFPIG - Mit diesem Projekt können Benutzer Text und andere Inhalte aus PDF -Dateien lesen und extrahieren. Zusätzlich kann die Bibliothek verwendet werden, um einfache PDF -Dokumente zu erstellen, die Text und geometrische Formen enthalten. Dieses Projekt zielt darauf ab, die PDFbox nach C# zu portieren
- Parsing-PDFS-Ressourcen und Arbeitsblatt für den gleichnamigen Workshop 2016
- PDF-Text-Extraction-Benchmark-PDF Tools Benchmark
- Geboren digitaler PDF -Scanner - Überprüfen Sie, ob PDF geboren ist digital
- OpenContracts Apache2-lizenziert, PDF-Annotationsplattform für visuell reiche Dokumente, die das ursprüngliche Layout und die Exporte x, y Positionsdaten für Token sowie Starts und Stopps von Spannwaren erhalten. Basierend auf PAWLs, jedoch mit einem Python-basierten Backend und leicht eingesetzt werden auf Ihrer lokalen Maschine, Firma Intranet oder im Web über Docker Compose.
- DeepDocTection Deep Doctction ist eine Python -Bibliothek, die Aufgaben zur Extraktion und Dokumentlayoutanalyse für Bilder und PDF -Dokumente mit Deep -Learning -Modellen orchestriert. Es wird keine Modelle implementiert, ermöglicht es Ihnen, Pipelines mit hochanerkannten Bibliotheken für Objekterkennung, OCR und ausgewählte NLP-Aufgaben zu erstellen und bietet einen integrierten Framework für Feinabstimmungen, Bewertung und Ausführen von Modellen.
- Pydoxtools Pydoxtools ist eine AI-Kompositionsbibliothek für die DPocument-Analyse. Es verfügt über ein umfangreiches Toolset zum Erstellen komplexer Dokumentenanalyse -Pipelines und erkennt die meisten Dokumentformate außerhalb der Box. Es unterstützt typische NLP -Aufgaben wie Schlüsselwörter, Summarisierung und Frage, die von der Box herausgearbeitet werden. und verfügt über einen hochwertigen Extraktionsalgorithmus mit niedrigem CPU/Speichertisch und macht NLP-Batch-Operationen auf einem Cluster einfach.
Konferenzen, Workshops
Zurück nach oben
Allgemein / business / finanziert
- Internationale Konferenz über Dokumentanalyse und Anerkennung (ICDAR) [2021, 2019, 2017]
- Workshop über Dokument Intelligence (DI) [2021, 2019]
- Financial Narrative Processing Workshop (FNP) [2021, 2020, 2019]
- Workshop für Wirtschaft und natürliche Sprachverarbeitung (ECONLP) [2021, 2019, 2018]
- Internationaler Workshop über Dokumentanalysesysteme (DAS) [2020, 2018, 2016]
- ACM Internationale Konferenz über KI in Finanzen (ICAIF)
- Der AAAI-21-Workshop zur Erkennung von Wissen aus unstrukturierten Daten in Finanzdienstleistungen
- CVPR 2020 Workshop zu Text und Dokumenten in der Ära Deep Learning
- KDD -Workshop zum maschinellen Lernen in Finanzen (KDD MLF 2020)
- Finir 2020: Der erste Workshop zum Abrufen von Informationen im Finanzwesen
- 2. KDD -Workshop zur Erkennung von Anomalie in Finanzen (KDD 2019)
- Konferenz für Dokumentverständnisse (Duc 2007)
Wissenschaftliches Dokumentverständnis
- Der AAAI-21-Workshop zum Verständnis des wissenschaftlichen Dokuments (SDU 2021)
- Erster Workshop zur wissenschaftlichen Dokumentenverarbeitung (SDPROC 2020)
- Internationaler Workshop zur wissenschaftlichen Dokumentanalyse (SCIDOCA) [2020, 2018, 2017]
Blogs
Zurück nach oben
- Eine Übersicht über Dokumentverständnismodelle, 2021
- Dokumentformularextraktion, 2021
- So automatisieren Sie Prozesse mit unstrukturierten Daten, 2021
- Ein umfassender Leitfaden für OCR mit RPA und Dokumentverständnis, 2021
- Informationsextraktion aus Quittungen mit Graph -Faltungsnetzwerken, 2021
- So extrahieren Sie strukturierte Daten aus Rechnungen, 2021
- Extrahieren strukturierter Daten aus templatischen Dokumenten, 2020
- Um KI für immer anzuwenden, denken Sie an Form, 2020, 2020
- UIPath -Dokumentverständnis von Lösungsarchitektur und -ansatz, 2020
- Wie kann ich die Datenextraktion aus komplexen Dokumenten automatisieren ?, 2020
- LegalTech: Informationsextraktion in Rechtsdokumenten, 2020
Lösungen
Zurück nach oben
Große Unternehmen:
- Abby
- Akzentur
- Amazonas
- Google
- Microsoft
- Uipath
Kleiner:
- Applica.ai
- Basis64.ai
- Docstack
- Element ai
- Indiko
- Instabase
- Konfuzio
- Metamaze
- Nanonetten
- Rossum
- Silo
Beispiele
Visuell reiche Dokumente
Zurück nach oben
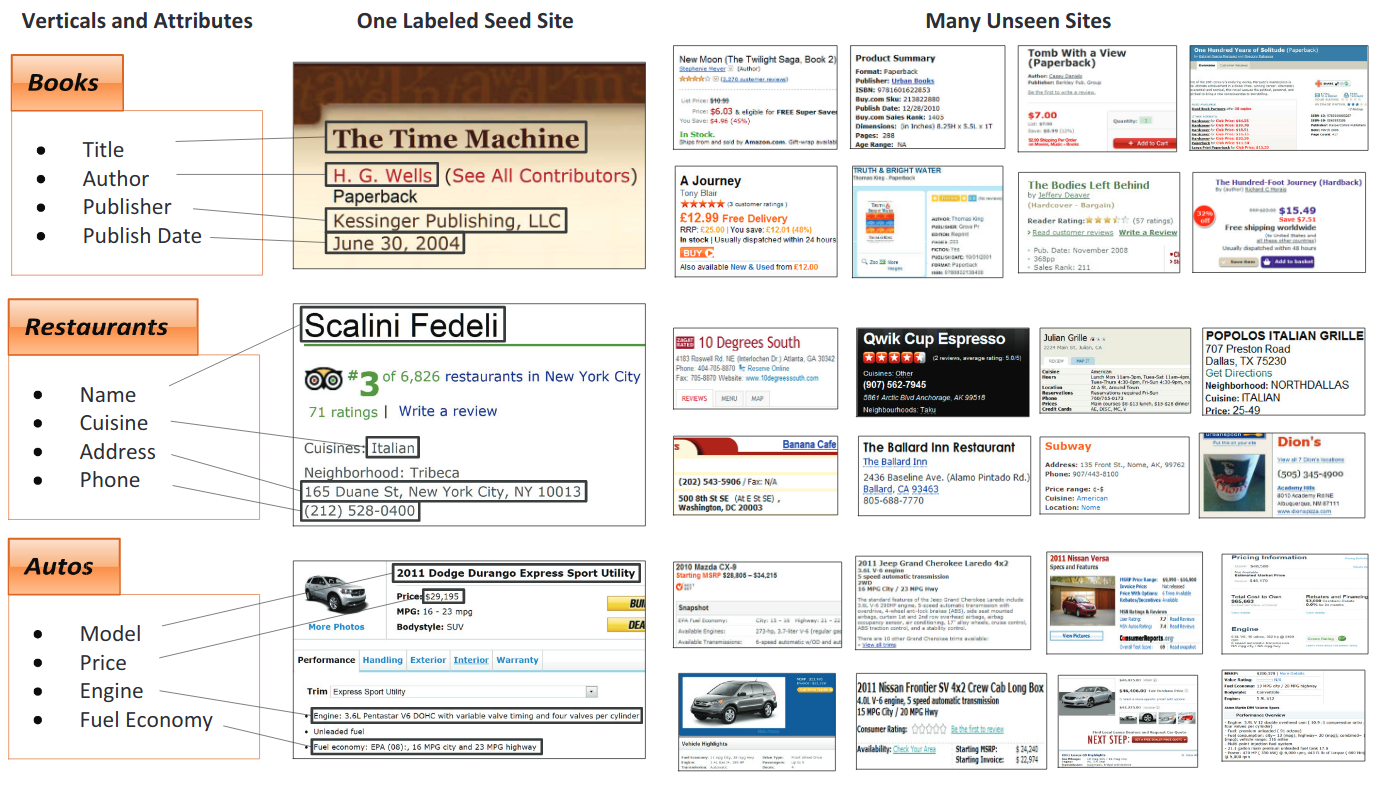
In VRDs ist die Bedeutung der Layoutinformationen von entscheidender Bedeutung, um das gesamte Dokument korrekt zu verstehen (dies ist bei fast allen Geschäftsdokumenten der Fall). Für Menschen verbessert räumliche Informationen die Lesbarkeit und das Verständnis des Dokuments des Dokuments.
Rechnung / Lebenslauf / Jobanzeige

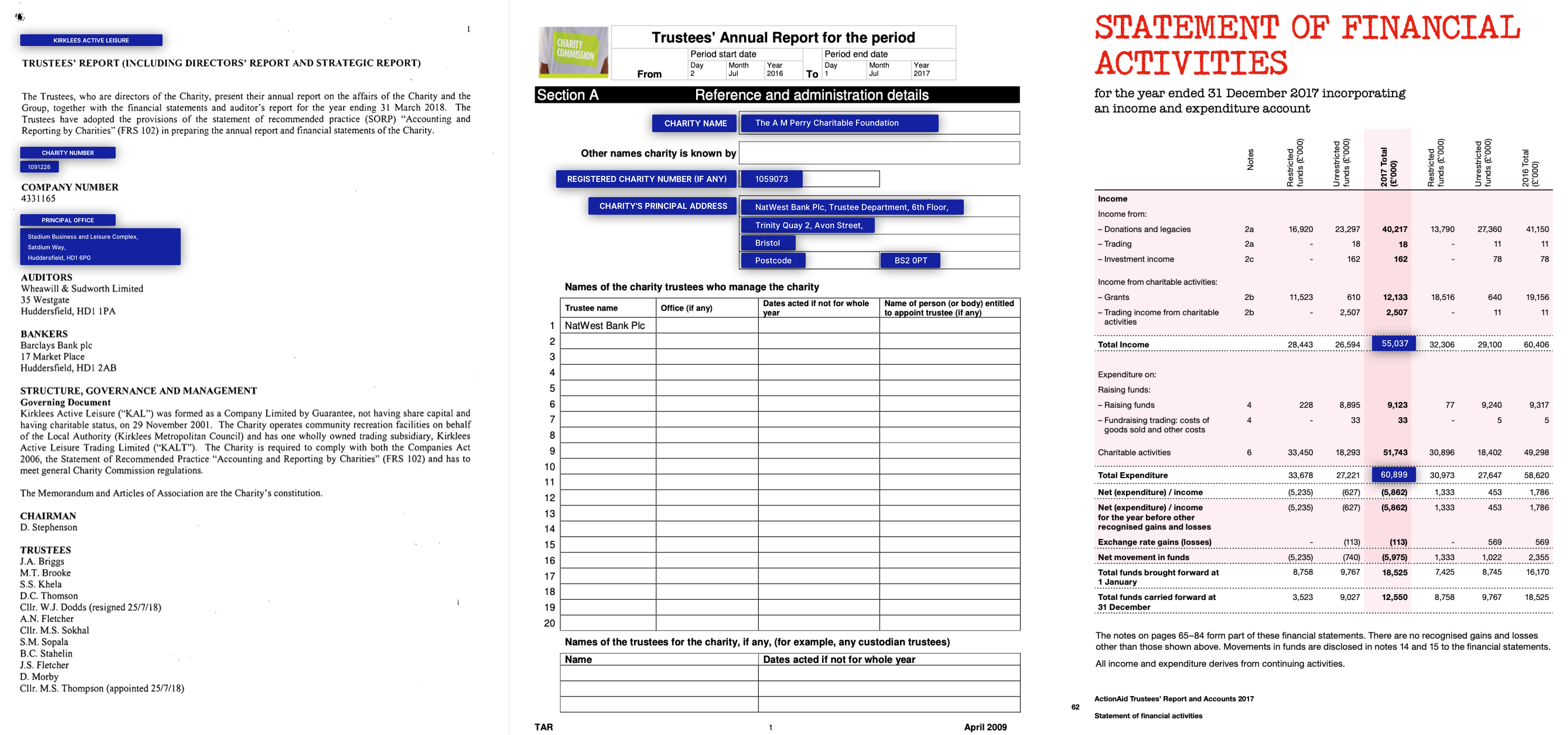
NDA / Jahresberichte

Schlüsselinformationsextraktion
Zurück nach oben
Ziel dieser Aufgabe ist es, Texte einer Reihe von Schlüsselfeldern aus einer bestimmten Sammlung von Dokumenten zu extrahieren, die ähnliche Schlüsseleinheiten enthalten.
Gescannte Quittungen
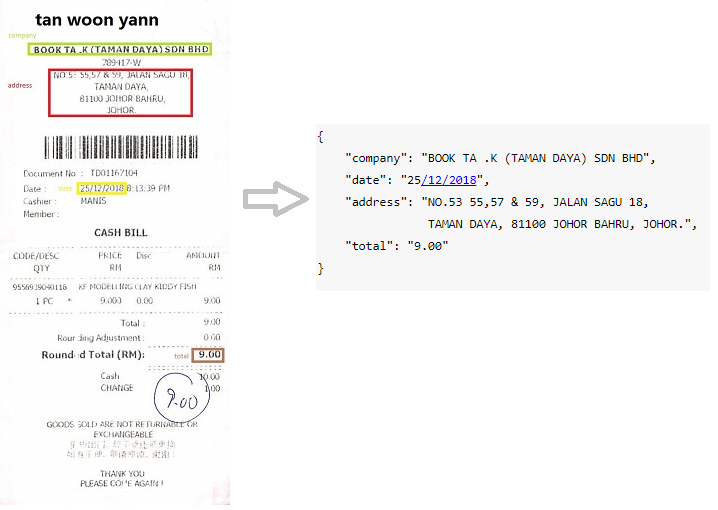
NDA / Jahresberichte
Beispiele für reale Geschäftsanwendungen und Daten für KLEISTER -Datensätze (die Schlüsseleinheiten sind blau)
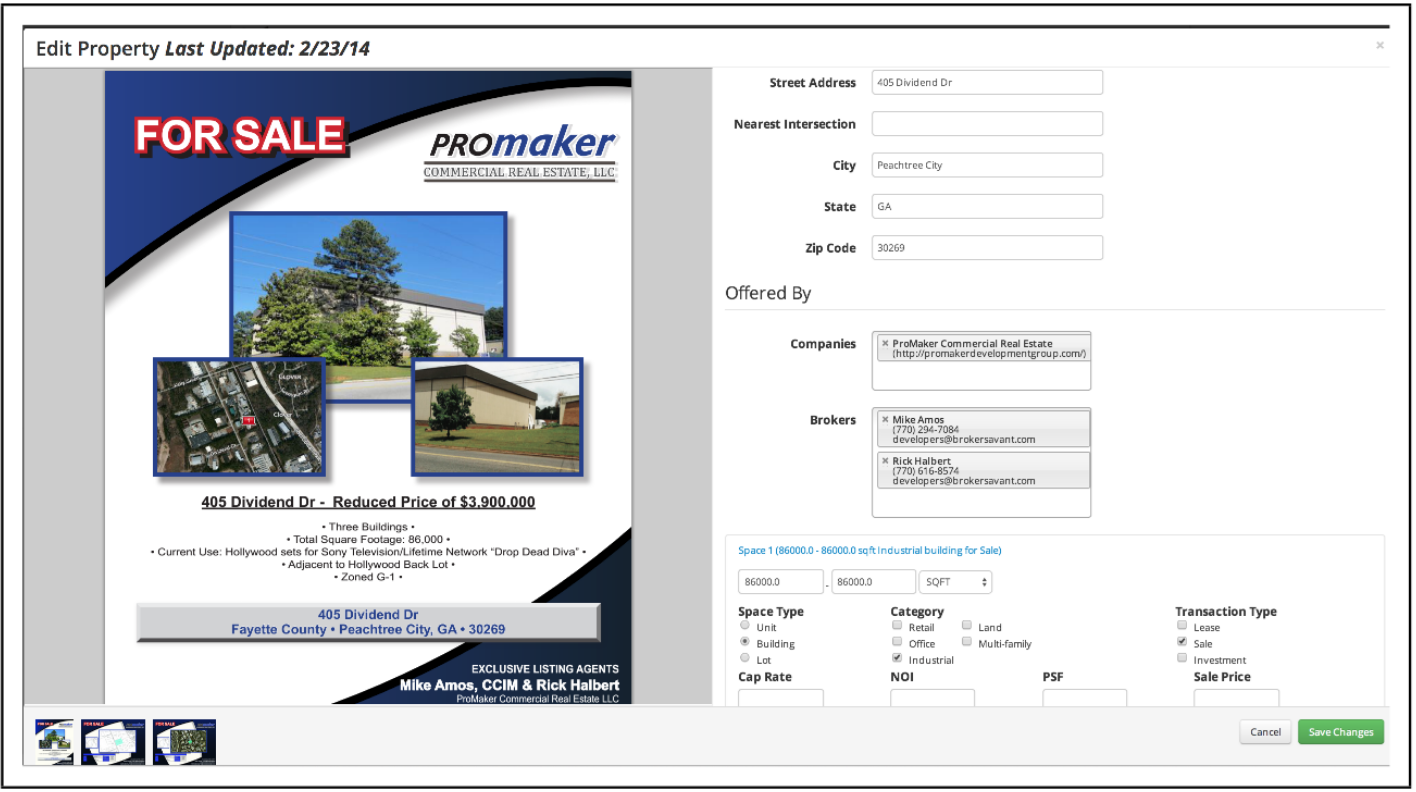
Multimedia Online -Flyer
Ein Beispiel für einen gewerblichen Immobilienflyer und ein manuell eingegebener Auflistungsinformationen © Promaker Commercial Real Estate LLC, © Brokersavant Inc.
Mehrwertsteuerrechnung

Webseiten
Dokumentlayoutanalyse
Zurück nach oben
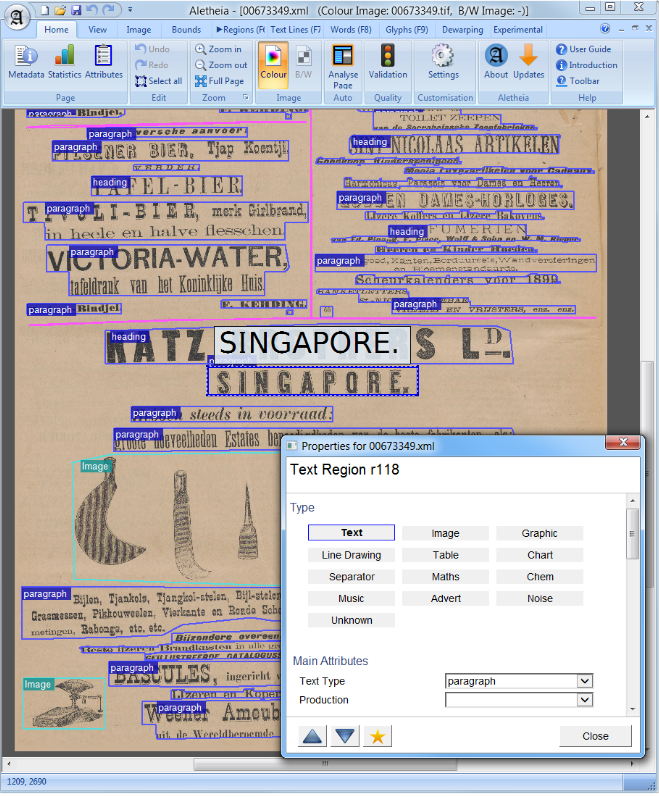
Bei der Verarbeitung von Computer Vision oder natürlicher Sprache ist die Dokumentlayoutanalyse der Prozess der Identifizierung und Kategorisierung der Interessensregionen am gescanntem Bild eines Textdokuments. Ein Lesesystem erfordert die Segmentierung von Textzonen von nicht-textuellen und die Anordnung in ihrer korrekten Lesereihenfolge. Die Erkennung und Kennzeichnung der verschiedenen Zonen (oder Blöcke) als Textkörper, Illustrationen, mathematische Symbole und in einem Dokument eingebettete Tabellen werden als geometrische Layoutanalyse bezeichnet. Textzonen spielen jedoch unterschiedliche logische Rollen im Dokument (Titel, Bildunterschriften, Fußnoten usw.), und diese Art der semantischen Kennzeichnung ist der Umfang der logischen Layoutanalyse. (https://en.wikipedia.org/wiki/document_layout_analysis)
Wissenschaftliche Veröffentlichung
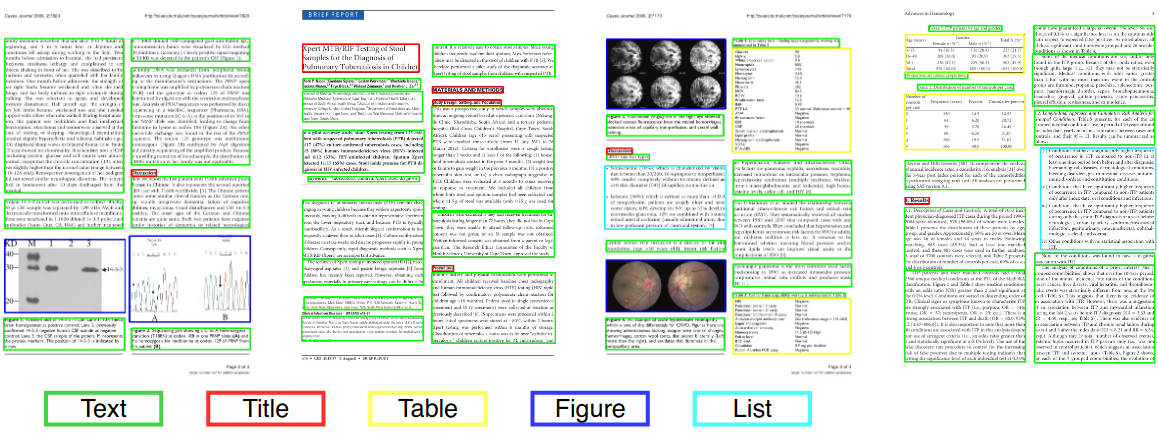

Historische Zeitungen
Geschäftsdokumente
Rot: Textblock, blau: Abbildung.

Beantwortung der Frage
Zurück nach oben
Docvqa Beispiel

Neigungsmodelldemo
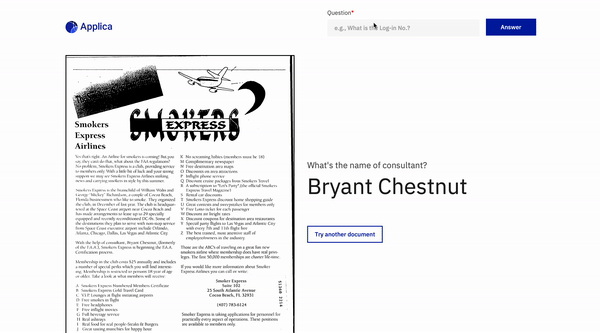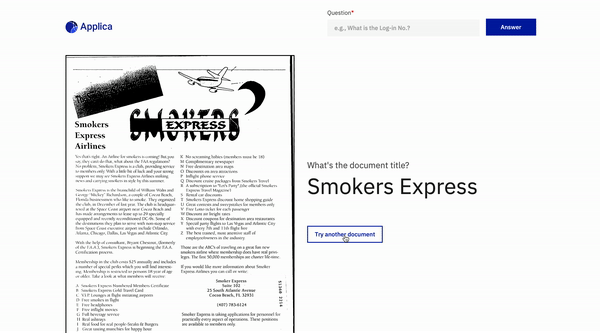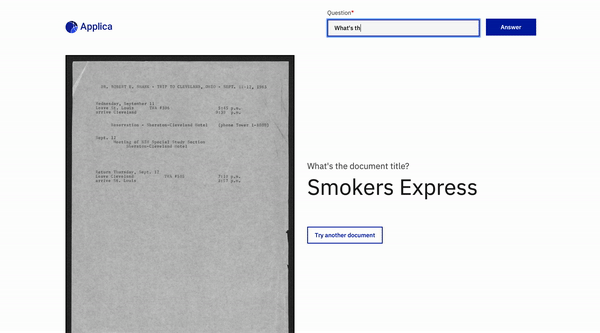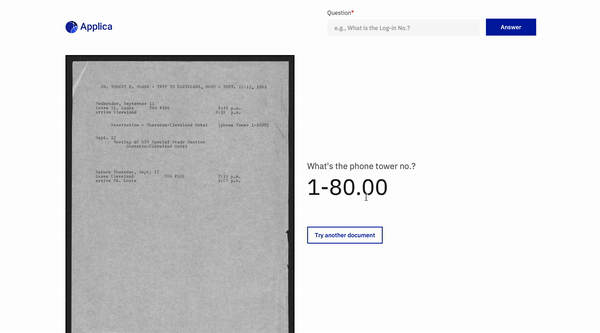
Inspirationen
Zurück nach oben
Domain
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/bobld/documentLayoutanalysis
- https://github.com/bikash/documentArtanden
- https://github.com/harpribot/awesome-information-retrieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/hellorusk/entity-related-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
Allgemeines AI/DL/ML
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-maachine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-ste-love/papers-ste-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-automlpapers


