Pemahaman dokumen yang luar biasa
Daftar sumber daya yang dikuratori untuk topik pemahaman dokumen (DU) yang terkait dengan pemrosesan dokumen cerdas (IDP), yang relatif terhadap otomatisasi proses robot (RPA) dari data yang tidak terstruktur, terutama dokumen kaya visual (VRD).
Catatan 1: Posisi tebal lebih penting daripada yang lain.
Catatan 2: Karena kebaruan lapangan, daftar ini sedang dibangun - kontribusi dipersilakan (terima kasih sebelumnya!). Harap ingat untuk menggunakan konvensi berikut:
- Judul publikasi / judul dataset / sumber daya, [kode / data / situs web]
Daftar Konferensi Penulis/Nama Nama Jurnal
Ukuran dataset: kereta api (tidak ada contoh), dev (tidak ada contoh), tes (tidak ada contoh) [opsional untuk kertas/sumber daya dataset]; Abstrak/Deskripsi Singkat ...
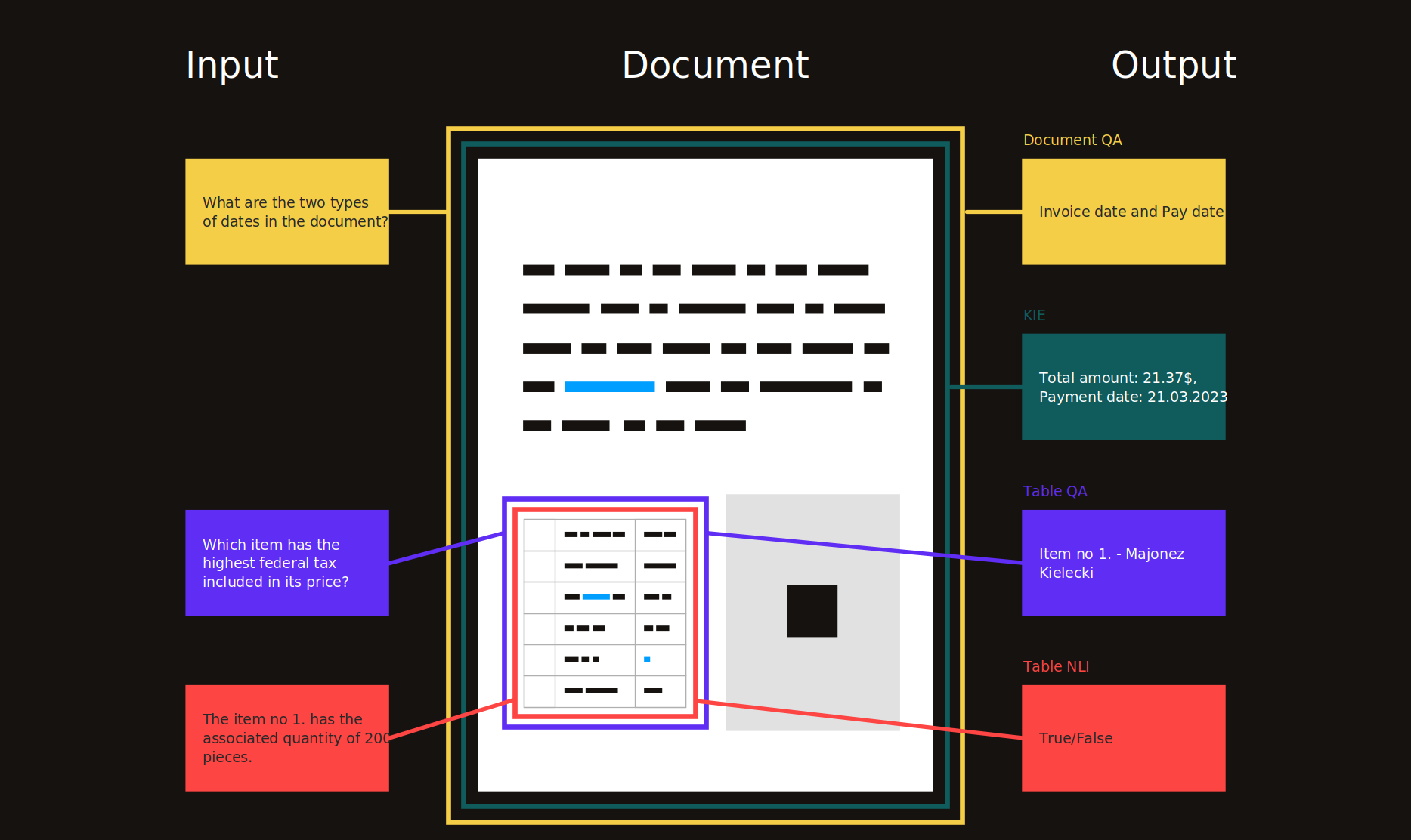
Daftar isi
- Perkenalan
- Topik Penelitian
- Ekstraksi Informasi Utama (KIE)
- Analisis Tata Letak Dokumen (DLA)
- Penjawab pertanyaan dokumen (DQA)
- Pemahaman Dokumen Ilmiah (SDU)
- Pengenalan Karakter Optik (OCR)
- Terkait
- Umum
- Pemahaman Data Tabular (TDC)
- Otomasi Proses Robot (RPA)
- Yang lain
- Sumber daya
- Dataset untuk model bahasa pra-pelatihan
- Alat pemrosesan PDF
- Konferensi / lokakarya
- Blog
- Solusi
- Contoh
- Dokumen kaya visual (VRD)
- Ekstraksi Informasi Utama (KIE)
- Analisis Tata Letak Dokumen (DLA)
- Penjawab pertanyaan dokumen (DQA)
- Inspirasi
Perkenalan
Dokumen adalah bagian inti dari banyak bisnis di banyak bidang seperti hukum, keuangan, dan teknologi. Pemahaman otomatis tentang dokumen -dokumen seperti faktur, kontrak, dan resume itu menguntungkan, membuka banyak jalan bisnis baru. Bidang pemrosesan bahasa alami dan visi komputer telah melihat kemajuan yang luar biasa melalui pengembangan pembelajaran yang mendalam sehingga metode ini telah mulai diresapi dalam sistem pemahaman dokumen kontemporer. sumber
Dokumen
2023
- Benchmark patuh untuk lokalisasi dan ekstraksi informasi dokumen, [situs web] [benchmark] [kode]
Štěpán Šimsa, Milan Šulc, Michal Uřičář, Yash Patel, Ahmed Hamdi, Matěj Kocián, Matyáš Skalický, Jiří Matas, Antoine Doucet, Mickaël Coustaty, Dimosthenis Karatzas Arxiva-Pre-print coustaty, Dimosthenis Karatzas Arxiva Arx3
Makalah ini memperkenalkan tolok ukur patuh dengan dataset dokumen bisnis terbesar untuk tugas -tugas lokalisasi dan ekstraksi informasi utama dan pengakuan item baris. Ini berisi 6,7K dokumen bisnis beranotasi, 100 ribu dokumen yang dihasilkan secara sintetis, dan hampir ~ 1M dokumen yang tidak berlabel untuk pra-pelatihan tanpa pengawasan. Dataset telah dibangun dengan pengetahuan tentang aspek domain dan tugas-spesifik, yang menghasilkan fitur-fitur utama berikut: (i) anotasi di 55 kelas, yang melampaui granularitas kumpulan data ekstraksi informasi utama yang diterbitkan sebelumnya dengan margin besar; (ii) pengenalan item baris merupakan tugas ekstraksi informasi yang sangat praktis, di mana informasi utama harus ditetapkan ke item dalam tabel; (iii) Dokumen berasal dari berbagai tata letak dan set tes mencakup kasus nol dan beberapa-shot serta tata letak yang biasa terlihat dalam set pelatihan. Benchmark dilengkapi dengan beberapa baseline, termasuk Roberta, LayoutLMV3 dan Detr Table Transformer. Model -model dasar ini diterapkan pada kedua tugas tolok ukur yang patuh, dengan hasil yang dibagikan dalam makalah ini, menawarkan titik awal yang cepat untuk pekerjaan di masa depan. Dataset dan garis dasar tersedia di URL HTTPS ini.
2022
Ekstraksi Informasi Dokumen Bisnis: Menuju Tolok Ukur Praktis
Matyáš Skalický, Štěpán Šimsa, Michal Uřičář, Milan Šulc Clef 2022
Ekstraksi informasi dari dokumen semi-terstruktur sangat penting untuk komunikasi bisnis tanpa gesekan (B2B). Sementara masalah pembelajaran mesin yang terkait dengan ekstraksi informasi dokumen (IE) telah dipelajari selama beberapa dekade, banyak definisi dan tolok ukur masalah umum tidak mencerminkan aspek khusus domain dan kebutuhan praktis untuk mengotomatisasi komunikasi dokumen B2B. Kami meninjau lanskap dokumen, yaitu masalah, kumpulan data, dan tolok ukur. Kami menyoroti aspek -aspek praktis yang hilang dalam definisi umum dan menentukan masalah lokalisasi dan ekstraksi informasi utama (Kile) dan masalah pengenalan item (LIR). Ada kekurangan kumpulan data dan tolok ukur yang relevan untuk dokumen IE pada dokumen bisnis semi-terstruktur karena konten mereka biasanya dilindungi secara hukum atau sensitif. Kami membahas sumber -sumber potensial dari dokumen yang tersedia termasuk data sintetis. Doc2Graph: Kerangka Pemahaman Dokumen Agnostik Tugas Berdasarkan Grafik Jaringan Saraf, [Kode]
Andrea Gemelli, Sanket Biswas, Enrico Civitelli, Josep Lladós, Simone Marinai Tie Workshop @ ECCV 2022
Geometris Deep Learning baru -baru ini menarik minat yang signifikan dalam berbagai bidang pembelajaran mesin, termasuk analisis dokumen. Penerapan grafik jaringan saraf (GNNs) telah menjadi penting dalam berbagai tugas terkait dokumen karena mereka dapat mengungkap pola struktural yang penting, mendasar dalam proses ekstraksi informasi utama. Pekerjaan sebelumnya dalam literatur mengusulkan model yang digerakkan oleh tugas dan tidak memperhitungkan kekuatan penuh grafik. Kami mengusulkan Doc2Graph, kerangka pemahaman dokumen-agnostik tugas berdasarkan model GNN, untuk menyelesaikan tugas yang berbeda yang diberikan berbagai jenis dokumen. Kami mengevaluasi pendekatan kami pada dua set data yang menantang untuk ekstraksi informasi utama dalam pemahaman bentuk, analisis tata letak faktur dan deteksi tabel
2021
Dokumen AI: Tolok Ukur, Model, dan Aplikasi
Lei Cui, Yiheng Xu, Tengchao LV, Furu Wei Arxiv 2021
Dokumen AI, atau Dokumen Intelijen, adalah topik penelitian yang relatif baru yang mengacu pada teknik untuk membaca, memahami, dan menganalisis dokumen bisnis secara otomatis. Ini adalah arah penelitian yang penting untuk pemrosesan bahasa alami dan visi komputer. Dalam beberapa tahun terakhir, popularitas teknologi pembelajaran mendalam telah sangat memajukan pengembangan AI dokumen, seperti analisis tata letak dokumen, ekstraksi informasi visual, penjawab pertanyaan visual dokumen, klasifikasi gambar dokumen, dll. Makalah ini secara singkat meninjau beberapa model, tugas, dan dataset tolok ukur yang representatif. Selain itu, kami juga memperkenalkan analisis dokumen berbasis aturan heuristik tahap awal, algoritma pembelajaran mesin statistik, dan pendekatan pembelajaran mendalam terutama metode pra-pelatihan. Akhirnya, kami melihat arah masa depan untuk penelitian AI. Pemrosesan otomatis yang efisien dari dokumen yang tidak terstruktur menggunakan kecerdasan buatan: tinjauan literatur sistematis dan arah masa depan
Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, Ketan Kotecha IEEE Access 2021
Data yang tidak terstruktur berdampak 95% dari organisasi dan menghabiskan biaya jutaan dolar per tahun. Jika dikelola dengan baik, itu dapat secara signifikan meningkatkan produktivitas bisnis. Teknik ekstraksi informasi tradisional terbatas dalam fungsinya, tetapi teknik berbasis AI dapat memberikan solusi yang lebih baik. Investigasi menyeluruh terhadap teknik berbasis AI untuk ekstraksi informasi otomatis dari dokumen yang tidak terstruktur tidak ada dalam literatur. Tujuan dari Systematic Literature Review (SLR) ini adalah untuk mengenali, dan menganalisis penelitian tentang teknik yang digunakan untuk ekstraksi informasi otomatis dari dokumen yang tidak terstruktur dan untuk memberikan arahan untuk penelitian di masa depan. The SLR guidelines proposed by Kitchenham and Charters were adhered to conduct a literature search on various databases between 2010 and 2020. We found that: 1. The existing information extraction techniques are template-based or rule-based, 2. The existing methods lack the capability to tackle complex document layouts in real-time situations such as invoices and purchase orders, 3.The datasets available publicly are task-specific and of low quality. Oleh karena itu, ada kebutuhan untuk mengembangkan dataset baru yang mencerminkan masalah dunia nyata. SLR kami menemukan bahwa pendekatan berbasis AI memiliki potensi yang kuat untuk mengekstraksi informasi yang berguna dari dokumen yang tidak terstruktur secara otomatis. Namun, mereka menghadapi tantangan tertentu dalam memproses banyak tata letak dokumen yang tidak terstruktur. SLR kami memunculkan konseptualisasi kerangka kerja untuk pembangunan dataset dokumen tidak terstruktur berkualitas tinggi dengan teknik validasi data yang kuat untuk ekstraksi informasi otomatis. SLR kami juga mengungkapkan perlunya hubungan yang erat antara bisnis dan peneliti untuk menangani berbagai tantangan analisis data yang tidak terstruktur.
2020
2018
- Paradigma Masa Depan Pemrosesan Otomatis Dokumen Bisnis
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
Dalam makalah ini kami merangkum hasil yang diperoleh sejauh ini di masyarakat yang tertarik dalam pengembangan teknik pemrosesan otomatis sebagaimana diterapkan pada dokumen bisnis, dan menyusun beberapa evolusi yang diminta oleh tahap saat ini dari teknik tersebut sendiri atau dengan kemajuan sektor jaminan. Ini muncul gambaran yang jelas tentang bidang yang telah berupaya keras dalam memecahkan masalah yang banyak berubah selama 30 tahun terakhir, dan sekarang dengan cepat berkembang untuk memasukkan pemrosesan dokumen ke dalam sistem manajemen alur kerja di satu sisi dan untuk memasukkan fitur yang diperoleh dengan pengenalan teknologi komputasi awan di sisi lain. Kami mengusulkan skema arsitektur untuk pemrosesan dokumen bisnis yang berasal dari dua lini evolusi di atas.
Lebih tua
Topik Penelitian
- Ekstraksi Informasi Utama (KIE)
- Analisis Tata Letak Dokumen (DLA)
- Penjawab pertanyaan dokumen (DQA)
- Pemahaman Dokumen Ilmiah (SDU)
- Recogtion Karakter Optik (OCR)
- Terkait
- Umum
- Pemahaman Data Tabular (TDC)
- Otomasi Proses Robot (RPA)
Yang lain
Sumber daya
Kembali ke atas
Dataset untuk model bahasa pra-pelatihan
- Dataset RVL -CDIP - Dataset terdiri dari 400.000 gambar grayscale di 16 kelas, dengan 25.000 gambar per kelas
- Perpustakaan Dokumen Industri - Portal ke jutaan dokumen yang dibuat oleh industri yang mempengaruhi kesehatan masyarakat, yang diselenggarakan oleh Perpustakaan UCSF
- Dataset Dokumen Warna - Dari Sistem Informasi Sensor Cerdas, Universitas Amsterdam
- Koleksi CDIP IIT - Dataset terdiri dari dokumen dari gugatan negara bagian terhadap industri tembakau pada 1990 -an, terdiri dari sekitar 7 juta dokumen
Alat pemrosesan PDF
- Borb - adalah perpustakaan Python murni untuk dibaca, menulis, dan memanipulasi dokumen PDF. Ini mewakili dokumen PDF sebagai struktur data seperti JSON dari daftar bersarang, kamus dan primitif (angka, string, booleans, dll).
- Pawls - Anotasi PDF dengan label dan struktur adalah perangkat lunak yang memudahkan untuk mengumpulkan serangkaian anotasi yang terkait dengan dokumen PDF
- PDFPLOBER - Plumb a PDF untuk informasi terperinci tentang setiap karakter teks, persegi panjang, dan baris. Plus: Ekstraksi tabel dan debugging visual
- Pdfminer.six - pdfminer.six adalah garpu yang dikelola komunitas dari PDFMiner asli. Ini adalah alat untuk mengekstraksi informasi dari dokumen PDF. Ini berfokus pada mendapatkan dan menganalisis data teks
- Tata Letak Parser - Tata Letak Parser adalah alat berbasis pembelajaran yang mendalam untuk tugas analisis tata letak gambar dokumen
- Tabulo - Ekstraksi tabel dari gambar
- OCRMYPDF - OCRMYPDF menambahkan lapisan teks OCR ke file PDF yang dipindai, memungkinkan mereka dicari atau disalin
- PDFBox - Perpustakaan Apache PDFBox adalah alat Java open source untuk bekerja dengan dokumen PDF. Proyek ini memungkinkan pembuatan dokumen PDF baru, manipulasi dokumen yang ada dan kemampuan untuk mengekstrak konten dari dokumen
- PDFPIG - Proyek ini memungkinkan pengguna untuk membaca dan mengekstrak teks dan konten lainnya dari file PDF. Selain itu perpustakaan dapat digunakan untuk membuat dokumen PDF sederhana yang berisi teks dan bentuk geometris. Proyek ini bertujuan untuk port pdfbox ke c#
- Parsing-Prickly-PDFS-Sumber Daya dan Lembar Kerja untuk Lokakarya Nikar 2016 dengan nama yang sama
- PDF-text-Extraction-Benchmark-PDF Tools Benchmark
- Lahir Pemindai PDF Digital - Memeriksa apakah PDF dilahirkan digital
- OpenContracts Apache2-Licensed, PDF Anotasi platform untuk dokumen kaya visual yang mempertahankan tata letak asli dan ekspor X, Y data posisi untuk token serta rentang dimulai dan berhenti. Berdasarkan Pawls, tetapi dengan backend berbasis Python dan mudah digunakan pada mesin lokal Anda, Intranet Perusahaan atau Web melalui Docker Compose.
- DeepDoctection Deep Doctection adalah perpustakaan Python yang mengatur ekstraksi dokumen dan tugas analisis tata letak dokumen untuk gambar dan dokumen PDF menggunakan model pembelajaran mendalam. Itu tidak mengimplementasikan model tetapi memungkinkan Anda untuk membangun jaringan pipa menggunakan perpustakaan yang sangat diakui untuk deteksi objek, OCR dan tugas NLP yang dipilih dan menyediakan kerangka kerja terintegrasi untuk menyempurnakan, mengevaluasi, dan menjalankan model.
- Pydoxtools Pydoxtools adalah perpustakaan komposisi AI untuk analisis dpocument. Ini fitur perangkat yang luas untuk membangun pipa analisis dokumen yang kompleks dan mengenali sebagian besar format dokumen di luar kotak. Ini mendukung tugas -tugas NLP yang khas seperti kata kunci, peringkasan, question_answering di luar kotak. dan fitur algoritma ekstraksi tabel rendah-CPU/memori berkualitas tinggi dan membuat operasi batch NLP mudah pada cluster.
Konferensi, lokakarya
Kembali ke atas
Umum / Bisnis / Keuangan
- Konferensi Internasional tentang Analisis Dokumen dan Pengakuan (ICDAR) [2021, 2019, 2017]
- Lokakarya tentang Intelijen Dokumen (DI) [2021, 2019]
- Lokakarya Pemrosesan Narasi Keuangan (FNP) [2021, 2020, 2019]
- Lokakarya tentang Ekonomi dan Pemrosesan Bahasa Alami (ECONLP) [2021, 2019, 2018]
- Lokakarya Internasional tentang Sistem Analisis Dokumen (DAS) [2020, 2018, 2016]
- Konferensi Internasional ACM tentang AI di bidang Keuangan (ICAIF)
- Lokakarya AAAI-21 tentang Penemuan Pengetahuan dari Data Tidak Terstruktur dalam Jasa Keuangan
- Lokakarya CVPR 2020 tentang Teks dan Dokumen di Era Pembelajaran yang mendalam
- Lokakarya KDD tentang Pembelajaran Mesin di bidang Keuangan (KDD MLF 2020)
- Finir 2020: Lokakarya pertama tentang pengambilan informasi di bidang keuangan
- Lokakarya KDD ke -2 tentang Deteksi Anomali di bidang Keuangan (KDD 2019)
- Konferensi Pemahaman Dokumen (DUC 2007)
Pemahaman Dokumen Ilmiah
- Lokakarya AAAI-21 tentang Pemahaman Dokumen Ilmiah (SDU 2021)
- Lokakarya pertama tentang pemrosesan dokumen ilmiah (SDPROC 2020)
- Lokakarya Internasional tentang Analisis Dokumen Ilmiah (SCIDOCA) [2020, 2018, 2017]
Blog
Kembali ke atas
- Survei Model Pemahaman Dokumen, 2021
- Ekstraksi Formulir Dokumen, 2021
- Cara mengotomatisasi proses dengan data yang tidak terstruktur, 2021
- Panduan Komprehensif untuk OCR dengan RPA dan Pemahaman Dokumen, 2021
- Ekstraksi informasi dari tanda terima dengan Grafik Convolutional Networks, 2021
- Cara mengekstrak data terstruktur dari faktur, 2021
- Mengekstraksi data terstruktur dari Dokumen Templatik, 2020
- Untuk menerapkan AI untuk kebaikan, pikirkan ekstraksi bentuk, 2020
- Dokumen UIPath Memahami Arsitektur dan Pendekatan Solusi, 2020
- Bagaimana cara mengotomatisasi ekstraksi data dari dokumen kompleks?, 2020
- LegalTech: Ekstraksi Informasi dalam Dokumen Hukum, 2020
Solusi
Kembali ke atas
Perusahaan Besar:
- Abby
- Accenture
- Amazon
- Google
- Microsoft
- Uipath
Lebih kecil:
- Applica.ai
- Base64.ai
- DocStack
- Elemen ai
- Indico
- Instabase
- Konfuzio
- Metamaze
- Nanonet
- Rossum
- Silo
Contoh
Dokumen yang kaya secara visual
Kembali ke atas
Dalam VRD pentingnya informasi tata letak sangat penting untuk memahami seluruh dokumen dengan benar (ini adalah kasus dengan hampir semua dokumen bisnis). Untuk informasi spasial manusia meningkatkan keterbacaan dan kecepatan pemahaman dokumen.
Faktur / Resume / Iklan Pekerjaan

Laporan NDA / Tahunan

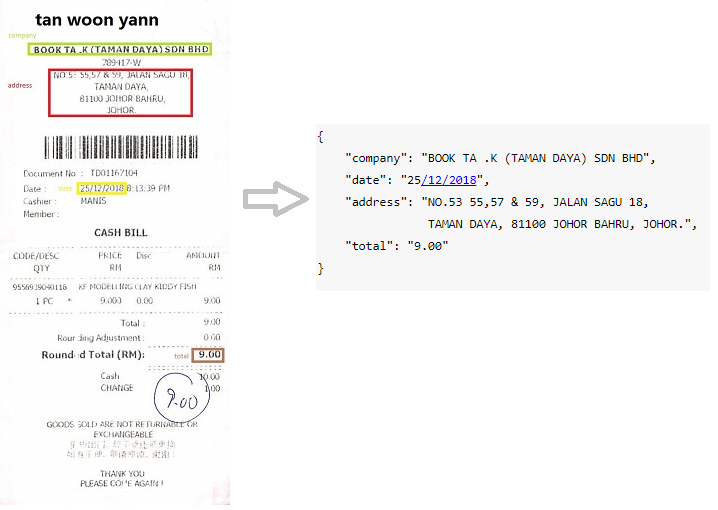
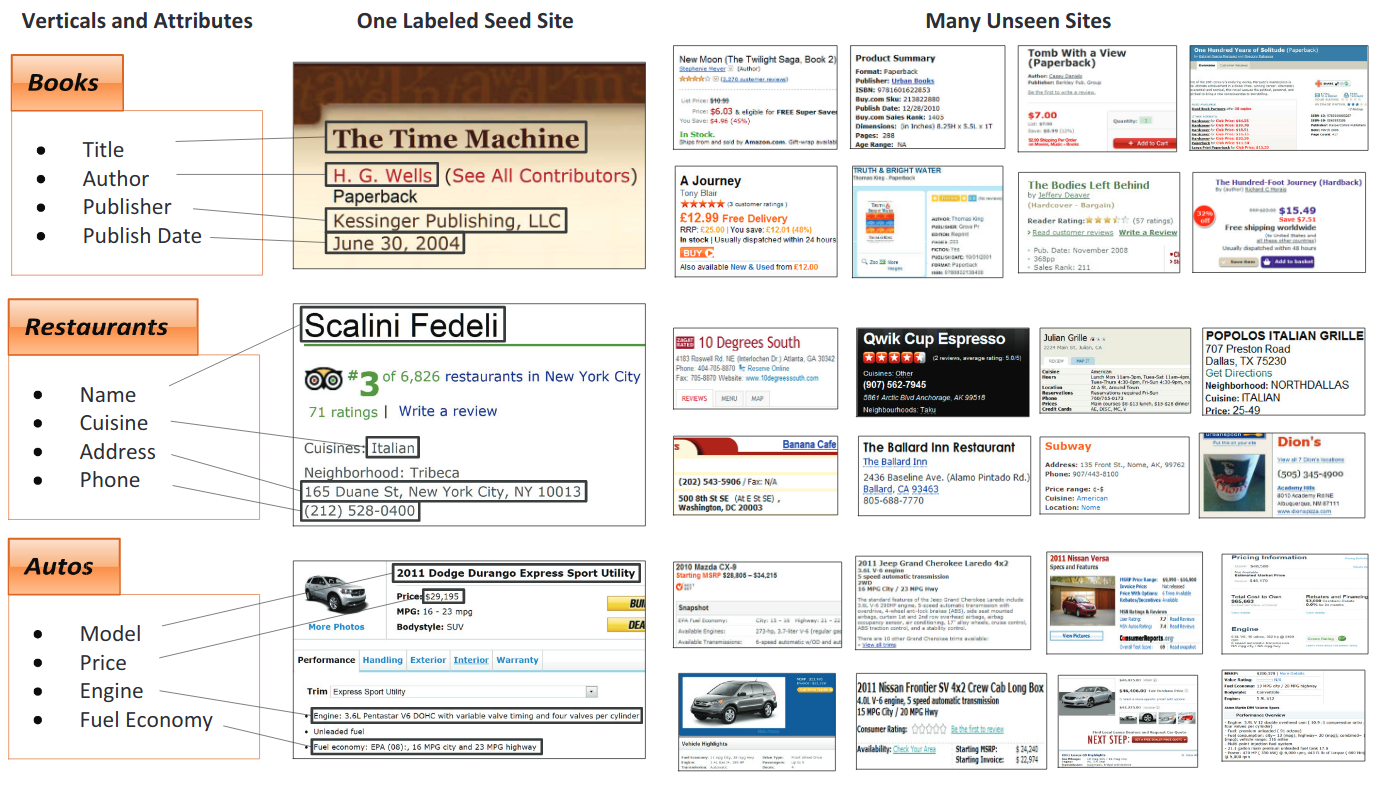
Ekstraksi Informasi Utama
Kembali ke atas
Tujuan dari tugas ini adalah untuk mengekstrak teks dari sejumlah bidang utama dari kumpulan dokumen yang berisi entitas kunci yang serupa.
Tanda terima yang dipindai
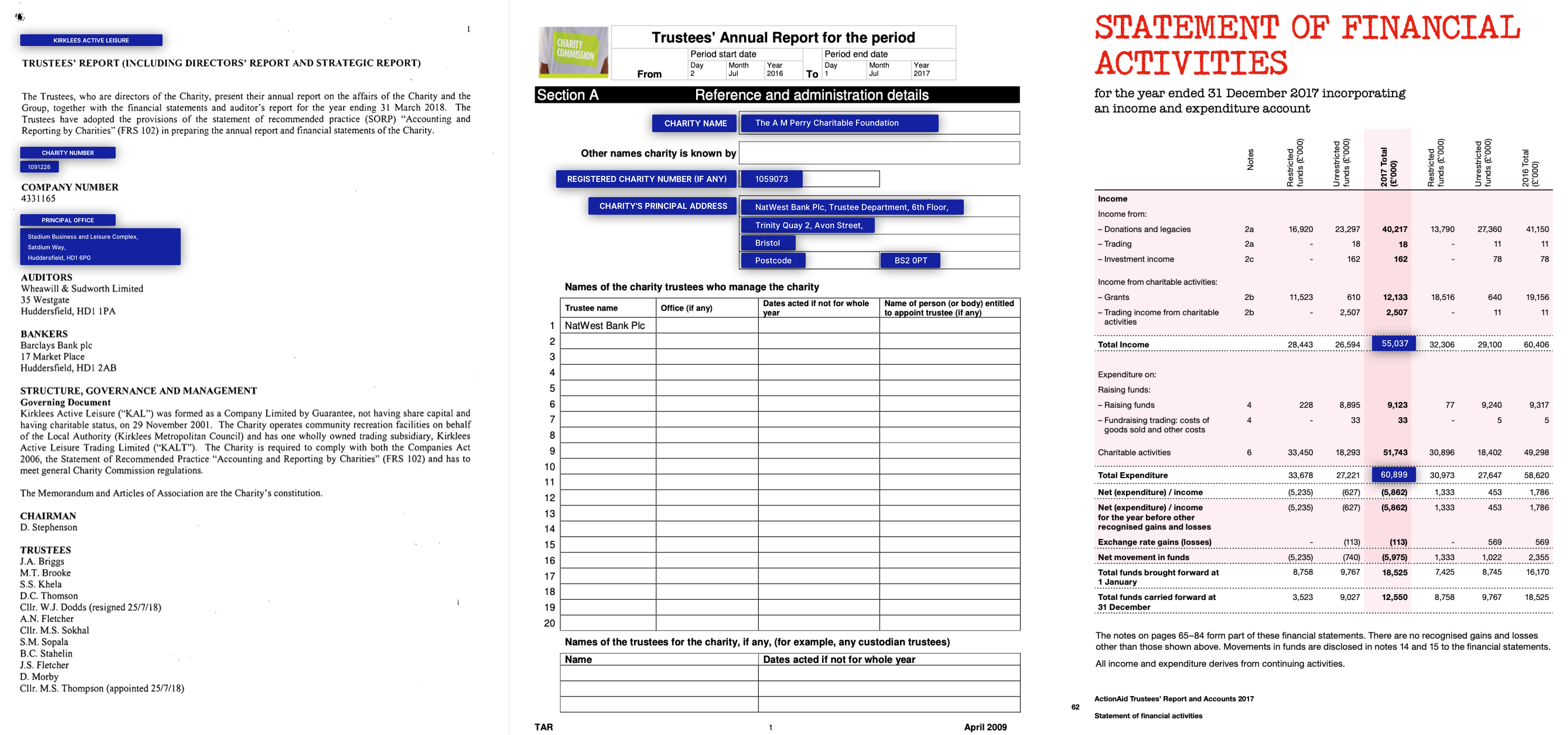
Laporan NDA / Tahunan
Contoh aplikasi bisnis nyata dan data untuk kumpulan data Kleister (entitas utama berwarna biru)
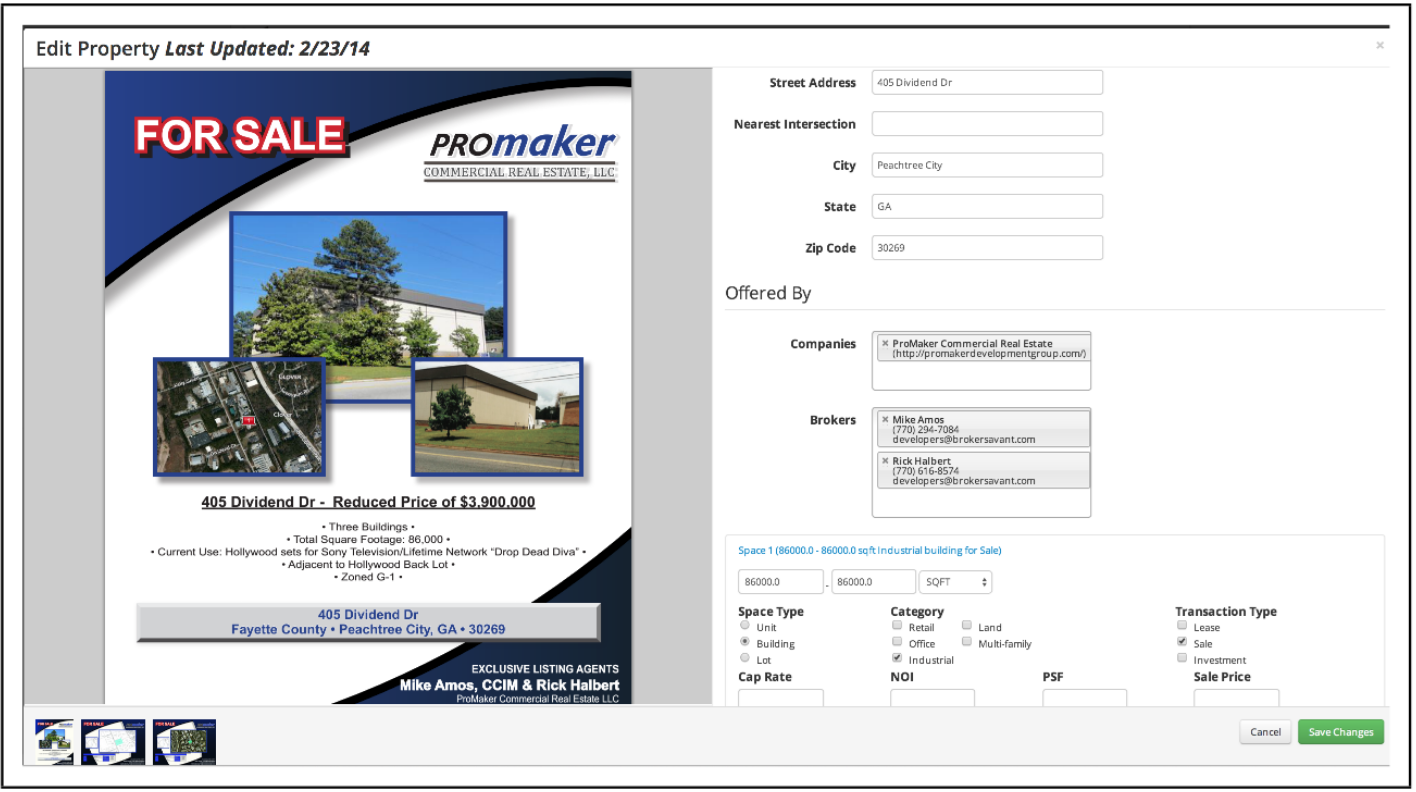
Selebaran online multimedia
Contoh dari selebaran real estat komersial dan informasi daftar yang dimasukkan secara manual © Promaker Komersial Real Estat LLC, © Brokersavant Inc.
Faktur Pajak Tambahan Nilai

Halaman web
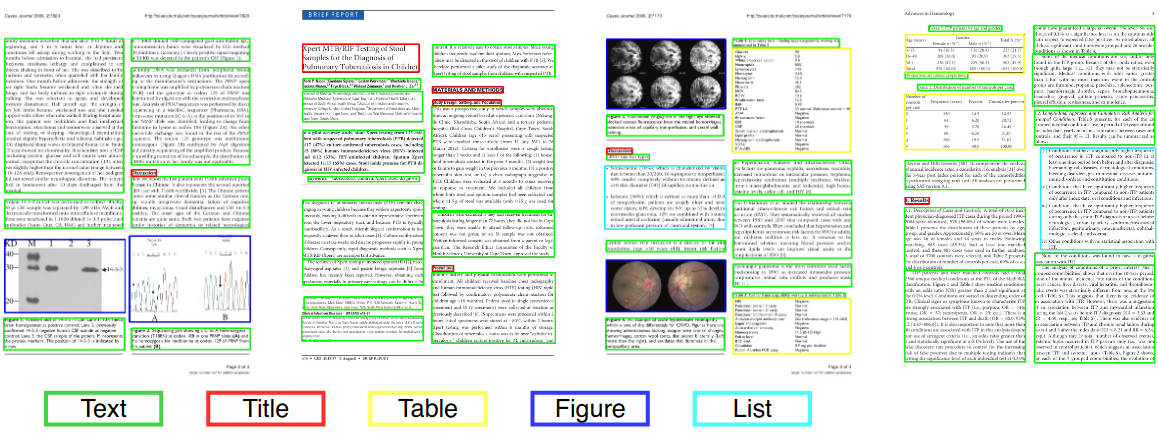
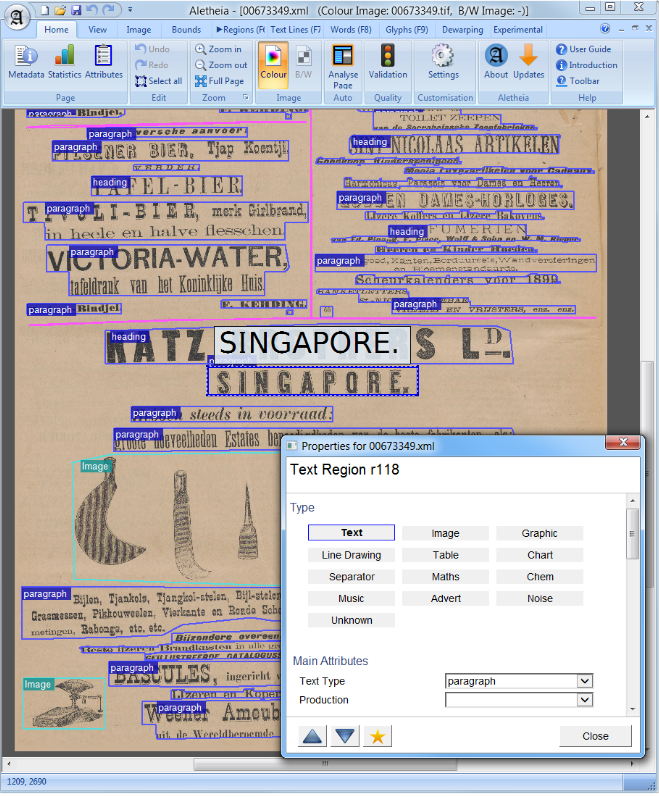
Analisis tata letak dokumen
Kembali ke atas
Dalam visi komputer atau pemrosesan bahasa alami, analisis tata letak dokumen adalah proses mengidentifikasi dan mengkategorikan wilayah yang menarik dalam gambar yang dipindai dari dokumen teks. Sistem membaca membutuhkan segmentasi zona teks dari yang non-tekstual dan pengaturan dalam urutan bacaan yang benar. Deteksi dan pelabelan zona yang berbeda (atau blok) sebagai badan teks, ilustrasi, simbol matematika, dan tabel yang tertanam dalam dokumen disebut analisis tata letak geometris. Tetapi zona teks memainkan peran logis yang berbeda di dalam dokumen (judul, keterangan, catatan kaki, dll.) Dan pelabelan semantik semacam ini adalah ruang lingkup dari analisis tata letak logis. (https://en.wikipedia.org/wiki/document_layout_analysis)
Publikasi ilmiah

Surat Kabar Sejarah
Dokumen Bisnis
Merah: Blok Teks, Biru: Gambar.

Jawaban Pertanyaan Dokumen
Kembali ke atas
Contoh DOCVQA

Demo model miring
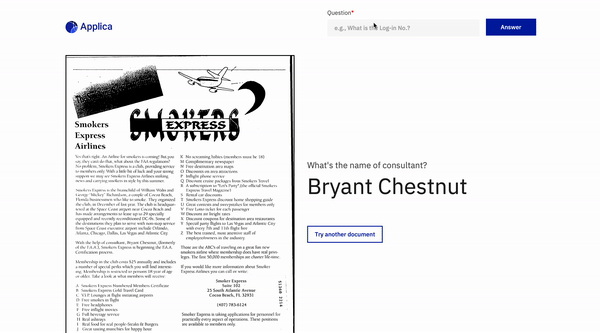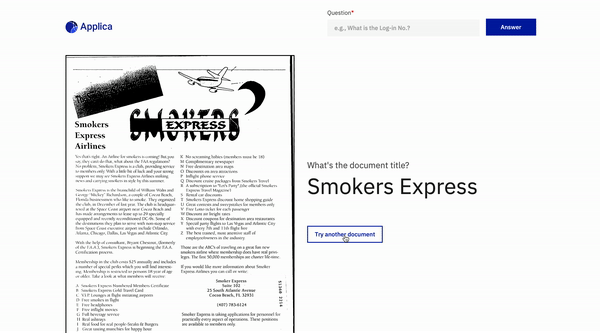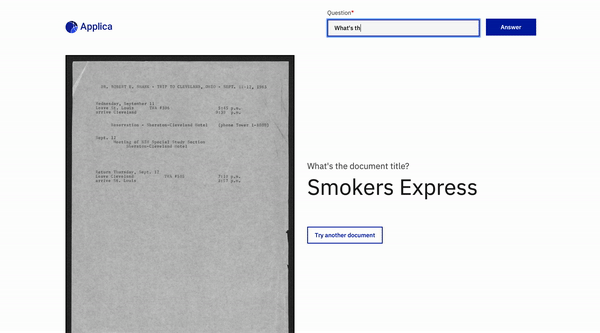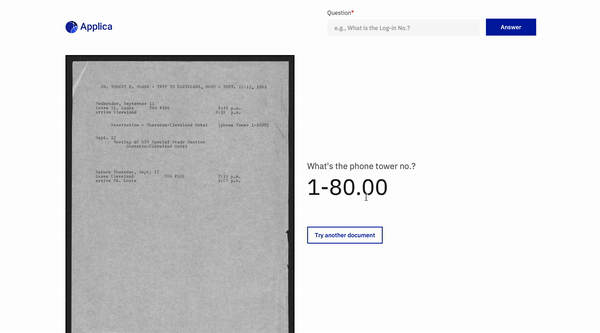
Inspirasi
Kembali ke atas
Domain
- https://github.com/kba/awesome-ocr
- https://github.com/liquid-legal-institute/legal-text-analytics
- https://github.com/icoxfog417/awese-financial-nlp
- https://github.com/bobld/documentlayoutanalysis
- https://github.com/bikash/documumunderstanding
- https://github.com/harpribot/awesome-information-retrieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-lioie
- https://github.com/hellorusk/entity-related-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/legalpapers
- https://github.com/heartexlabs/awesome-data-labeling
Umum AI/DL/ML
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/ethicalml/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/plmpapers
- https://github.com/jbhuang0604/aweome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/bailool/doyouevenlearn
- https://github.com/hibayesian/awesome-tapers-papers


