OpenAttack
version for datasets

文檔•功能和用途•用法示例•攻擊模型•工具包設計
OpenAttack是一個基於開源Python的文本對抗攻擊工具包,它處理了整個文本對抗攻擊的過程,包括預處理文本,訪問受害者模型,生成對抗性示例和評估。
配進所有攻擊類型的支持。 OpenATTACK支持所有類型的攻擊,包括句子/word-/cartar-level擾動和梯度 - /得分/基於決策/盲攻擊模型;
多語言。 OpenAttack現在支持英語和中文。它的可擴展設計可快速支持更多語言。
並行處理。 OpenAttack為攻擊模型的多進程運行提供了支持,以提高攻擊效率;
配立?擁抱臉。 OpenAttack完全集成了?變壓器和數據集庫;
️巨大的可擴展性。您可以在任何自定義數據集上輕鬆攻擊定制的受害者模型,或開發和評估定制的攻擊模型。
✅為攻擊模型提供各種方便的基線;
✅使用其徹底評估指標全面評估攻擊模型;
✅在其共同攻擊組件的幫助下,協助快速開發新的攻擊模型;
✅評估機器學習模型對各種對抗性攻擊的魯棒性;
✅通過用產生的對抗性示例豐富訓練數據,進行對抗訓練以提高機器學習模型的魯棒性。
pip (推薦) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install安裝後,您可以嘗試運行demo.py以檢查OpenAttack是否效果很好:
python demo.py
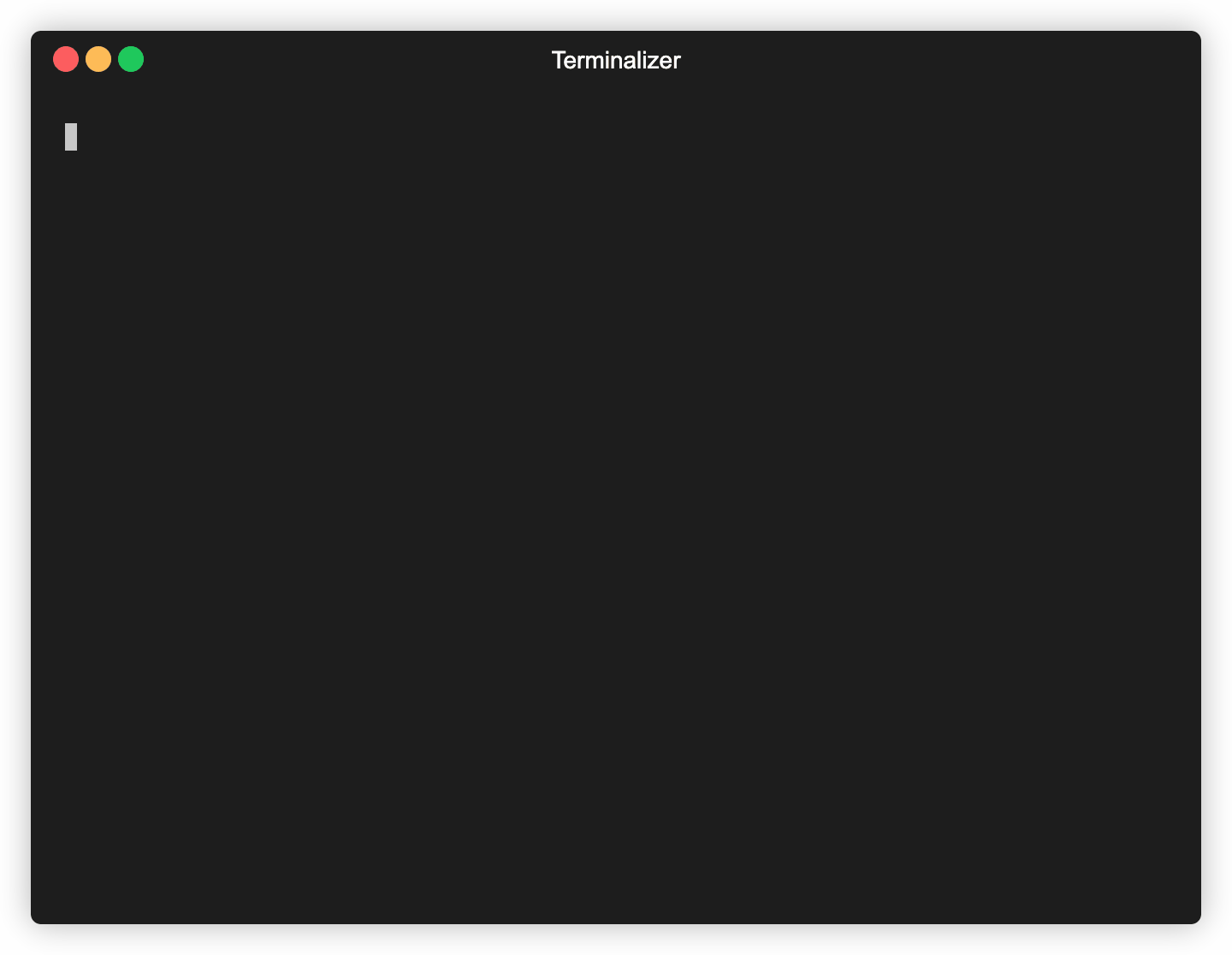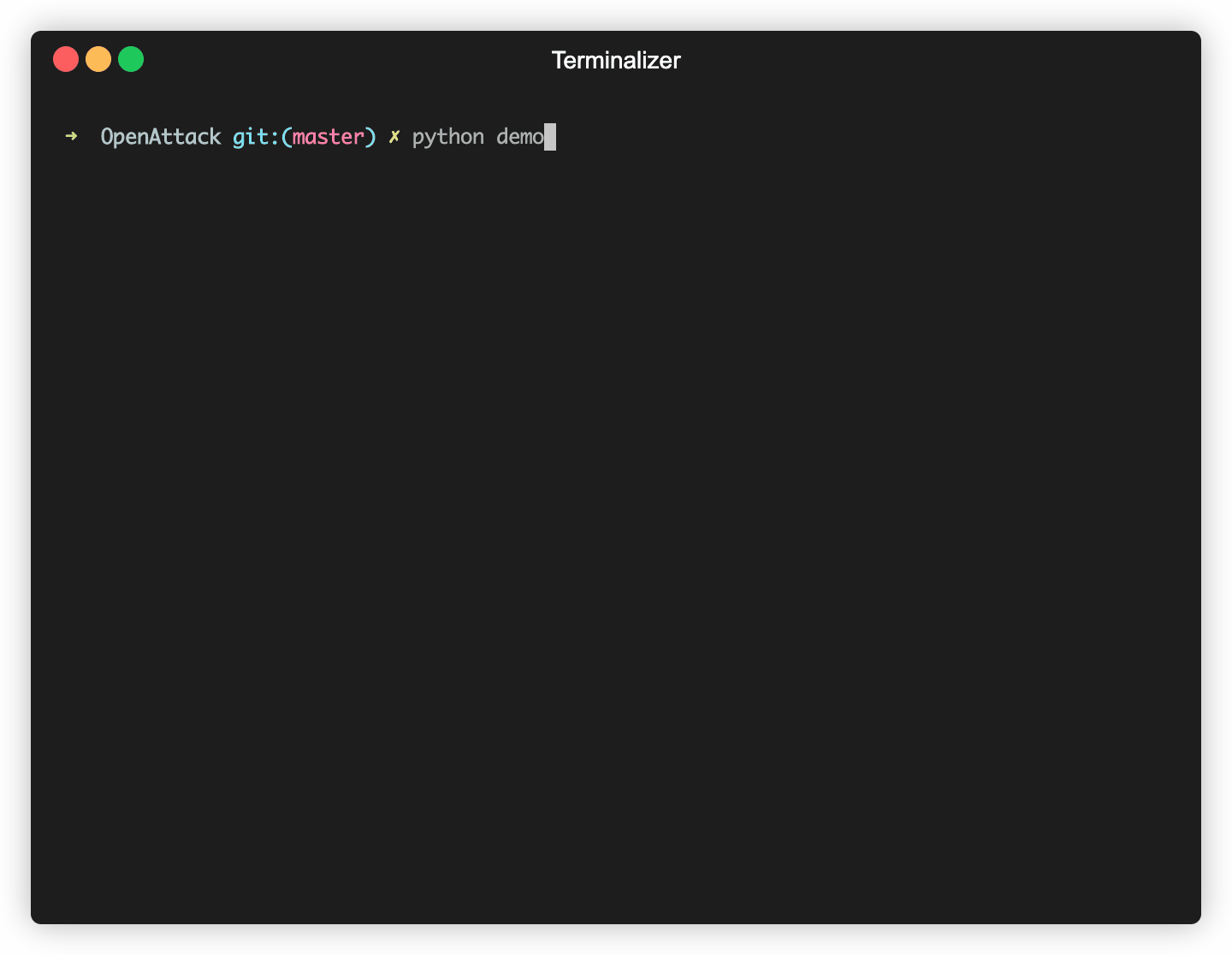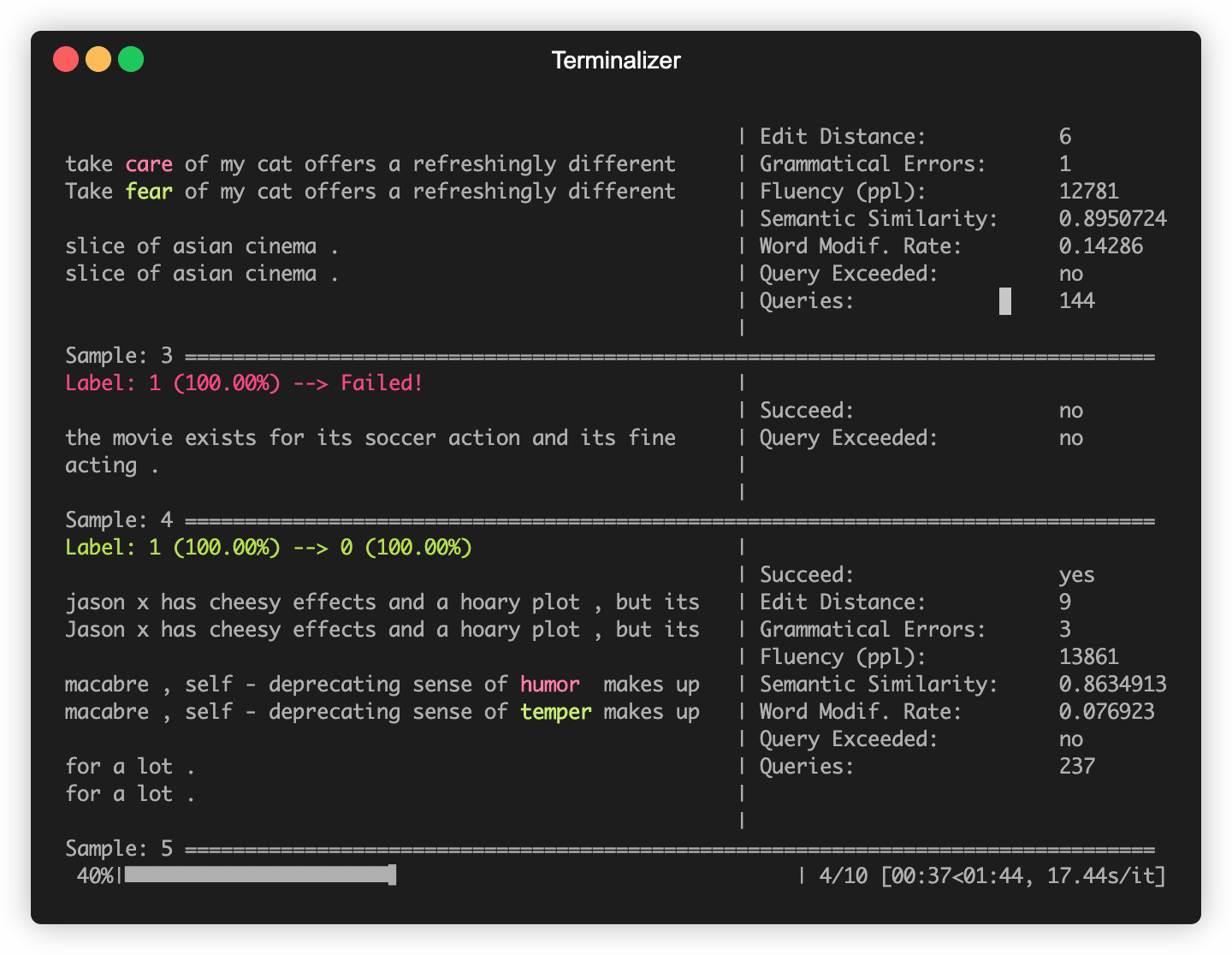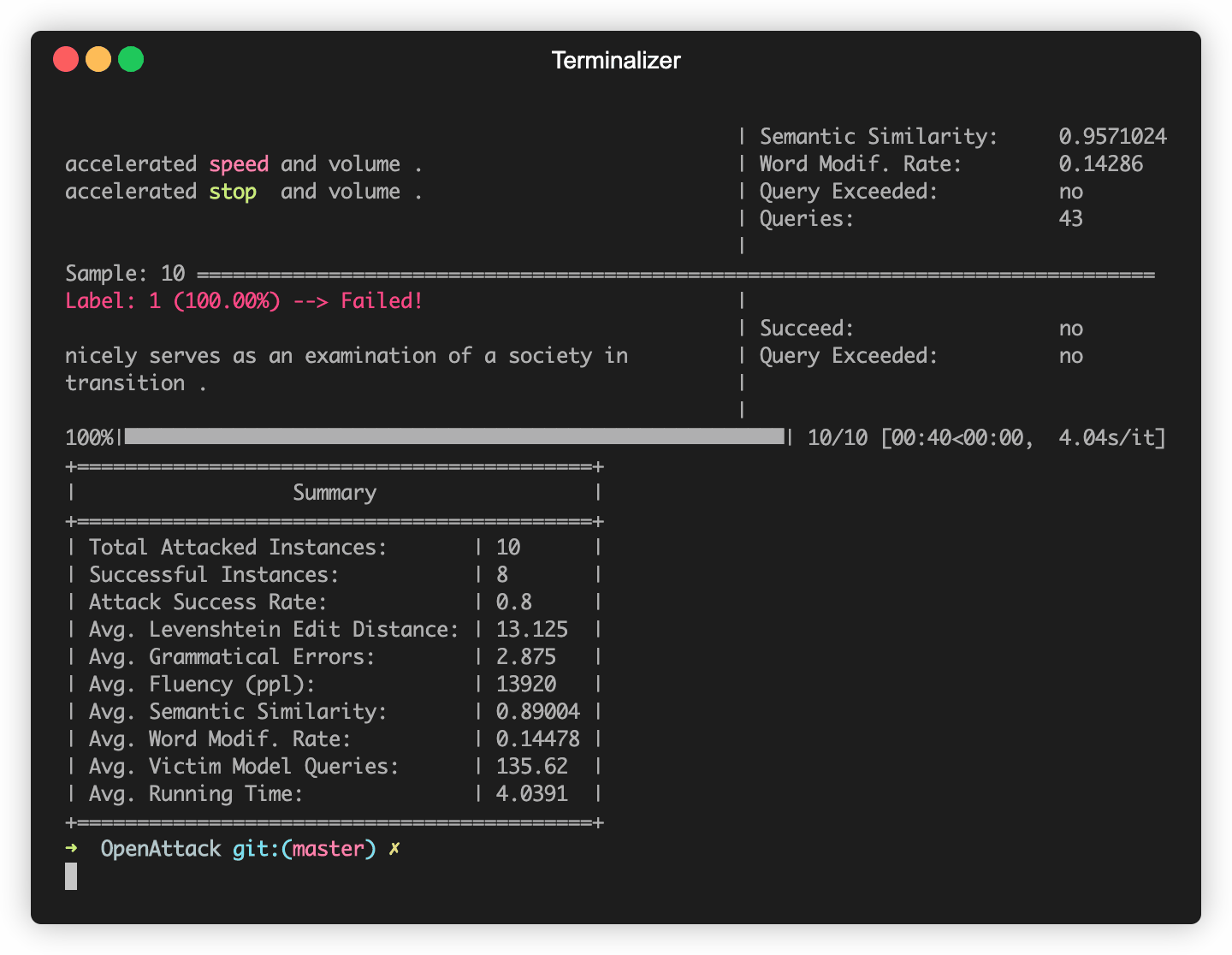
OpenAttack在一些常用的NLP模型中構建,例如Bert(Devlin等人,2018年)和Roberta(Liu等人,2019年),它們在一些常用的數據集(例如SST-2)上進行了微調。您可以輕鬆地針對這些內置受害者模型進行對抗性攻擊。
以下代碼片段顯示瞭如何使用PWWS,這是一種基於貪婪算法的攻擊模型(Ren等,2019),以攻擊SST-2數據集中的BERT(完整的可執行代碼在此處)。
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )以下代碼片段顯示瞭如何使用PWW在SST-2上攻擊自定義的情感分析模型(NLTK內置的統計模型)(完整的可執行代碼在此處)。
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )以下代碼段顯示瞭如何使用PWW在自定義數據集上攻擊現有的微調情感分析模型(完整的可執行代碼在此處)。
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )OpenAttack支持方便的多處理,以加速對抗攻擊的過程。以下代碼段顯示瞭如何在具有遺傳的對抗攻擊中使用多處理(Alzantot等人,2018),這是一種基於遺傳算法的攻擊模型(完整的可執行代碼在這裡)。
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )OpenAttack現在支持對英國和中國受害者模型的對抗性攻擊。這是使用PWWS對中國評論分類模型進行對抗性攻擊的示例守則。
OpenAttack結合了許多方便的組件,這些組件可以輕鬆組裝到新的攻擊模型中。這裡給出了一個示例,說明如何設計一個簡單的攻擊模型,該模型在原始句子中調整了令牌。
OpenATTACK可以通過攻擊訓練集中的實例輕鬆地產生對抗性示例,該實例可以添加到原始培訓數據集中,以重新訓練更強大的受害者模型,即對對抗性培訓。這裡舉例說明瞭如何使用OpenAttack進行對抗訓練。
攻擊句子對分類模型。除了單句分類模型外,OpenAttack還支持針對句子對分類模型的攻擊。這是對使用OpenAttack進行NLI模型進行對抗性攻擊的示例代碼。
定制評估指標。 OpenAttack支持設計定制的對抗攻擊評估度量。這裡舉了一個示例,說明如何添加自定義評估度量標準並使用它來評估對抗性攻擊。
根據對原始輸入施加的擾動水平,文本對抗攻擊模型可以歸類為句子級別,單詞級,字符級攻擊模型。
根據對受害者模型的可訪問性,文本對抗攻擊模型可以分為基於gradient的,基於score ,基於decision和blind攻擊模型。
Taadpapers是一個紙質清單,總結了幾乎所有有關文本對抗攻擊和防禦的論文。您可以查看此列表以查找更多攻擊模型。
當前,OpenAttack包括15個針對涵蓋所有攻擊類型的文本分類模型的典型攻擊模型。
這是當前涉及的攻擊模型的列表。
decision [PDF] [代碼]blind [PDF] [代碼和數據]decision [PDF] [代碼]score [PDF] [代碼]score [PDF] [代碼]score [PDF] [代碼]score [PDF] [代碼]score [PDF] [代碼]score [PDF] [代碼]gradient [PDF]gradient score [PDF]gradient [PDF] [代碼] [網站]gradient [PDF] [代碼]score [PDF] [代碼和數據]score [PDF] [代碼]下表說明了攻擊模型的比較。
| 模型 | 可訪問性 | 擾動 | 大意 |
|---|---|---|---|
| 海 | 決定 | 句子 | 基於規則的釋義 |
| SCPN | 瞎的 | 句子 | 釋義 |
| 甘 | 決定 | 句子 | 通過編碼器編碼器的文本生成 |
| TextFooler | 分數 | 單詞 | 貪婪的詞替代 |
| pwws | 分數 | 單詞 | 貪婪的詞替代 |
| 遺傳 | 分數 | 單詞 | 基於遺傳算法的單詞替代 |
| 半疾病 | 分數 | 單詞 | 基於粒子群優化的單詞替代 |
| 伯特攻擊 | 分數 | 單詞 | 貪婪的情境化詞替代 |
| 貝 | 分數 | 單詞 | 貪婪的上下文化詞替代和插入 |
| fd | 坡度 | 單詞 | 基於梯度的單詞替代 |
| Textbugger | 漸變,得分 | word+char | 貪婪的單詞替代和性格操縱 |
| UAT | 坡度 | 字,char | 基於梯度的單詞或角色操縱 |
| 熱彈 | 坡度 | 字,char | 基於梯度的單詞或角色替代 |
| 毒蛇 | 瞎的 | char | 視覺上相似的角色替代 |
| DeepWordbug | 分數 | char | 貪婪的角色操縱 |
考慮到不同攻擊模型之間的顯著區別,我們為攻擊模型的骨架設計留下了相當大的自由,並專注於簡化對抗性攻擊的一般處理以及攻擊模型中使用的常見組件。
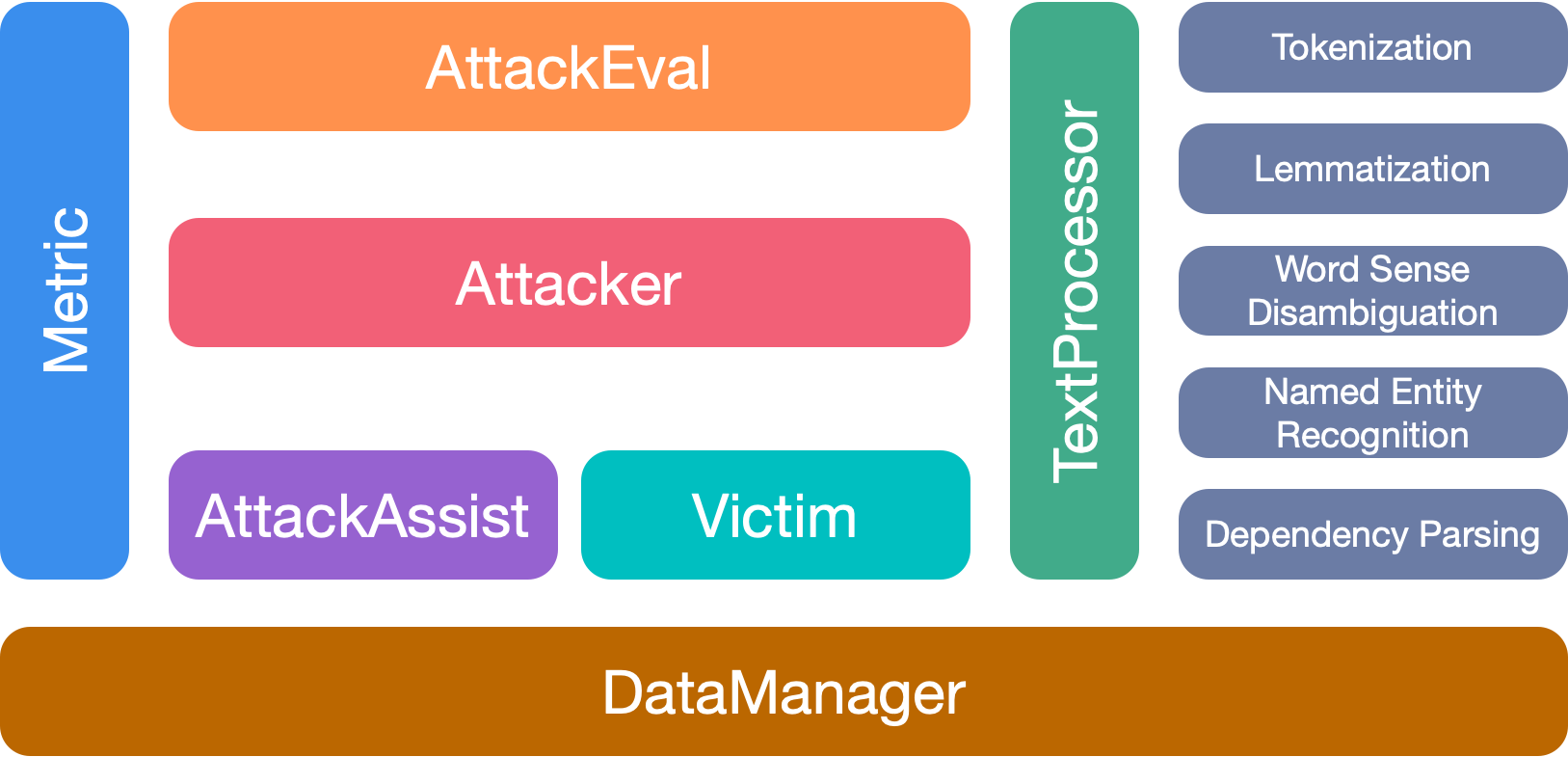
OpenAttack有7個主要模塊:
如果您使用此工具包,請引用我們的論文:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
我們感謝該項目的所有貢獻者。非常歡迎更多的貢獻。


