OpenAttack
version for datasets

Documentação • Recursos e usos • Exemplos de uso • Modelos de ataque • Design do kit de ferramentas
O OpenAttack é um kit de ferramentas de ataque adversário textual baseado em Python, que lida com todo o processo de ataque adversário textual, incluindo o pré-processamento de texto, acessando o modelo de vítima, gerando exemplos adversários e avaliação.
️ Suporte para todos os tipos de ataque . O OpenAttack suporta todos os tipos de ataques, incluindo perturbações no nível de sentença/palavra/caractere e modelos de ataque de gradiente/pontuação/decisões/cegos;
️ Multilinguidade multilíngue . O Openattack suporta inglês e chinês agora. Seu design extensível permite suporte rápido para mais idiomas;
️ Processamento paralelo . O OpenAttack fornece suporte para a execução de vários processos de modelos de ataque para melhorar a eficiência do ataque;
️ Compatibilidade com? Abraçando o rosto . O Openattack está totalmente integrado? Bibliotecas de transformadores e conjuntos de dados;
️ Grande extensibilidade . Você pode atacar facilmente um modelo de vítima personalizado em qualquer conjunto de dados personalizado ou desenvolver e avaliar um modelo de ataque personalizado.
✅ Fornecendo várias linhas de base úteis para modelos de ataque;
✅ Avaliação de modelos de ataque de forma abrangente usando suas métricas de avaliação completa;
✅ Auxiliar no desenvolvimento rápido de novos modelos de ataque com a ajuda de seus componentes de ataque comum;
✅ Avaliando a robustez de um modelo de aprendizado de máquina contra vários ataques adversários;
✅ Condução do treinamento adversário para melhorar a robustez de um modelo de aprendizado de máquina, enriquecendo os dados de treinamento com exemplos adversários gerados.
pip (recomendado) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install Após a instalação, você pode tentar executar demo.py para verificar se o OpenAttack funciona bem:
python demo.py
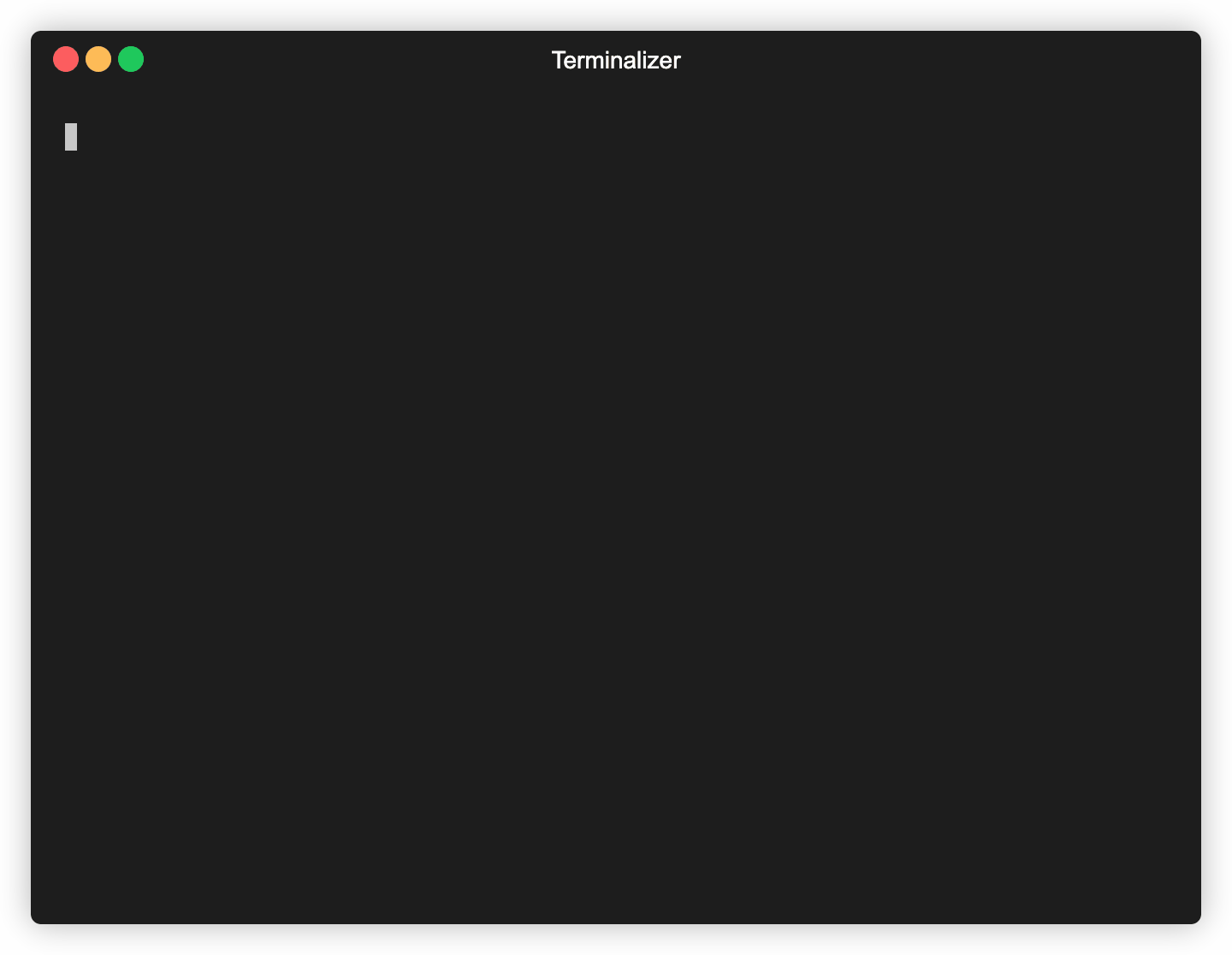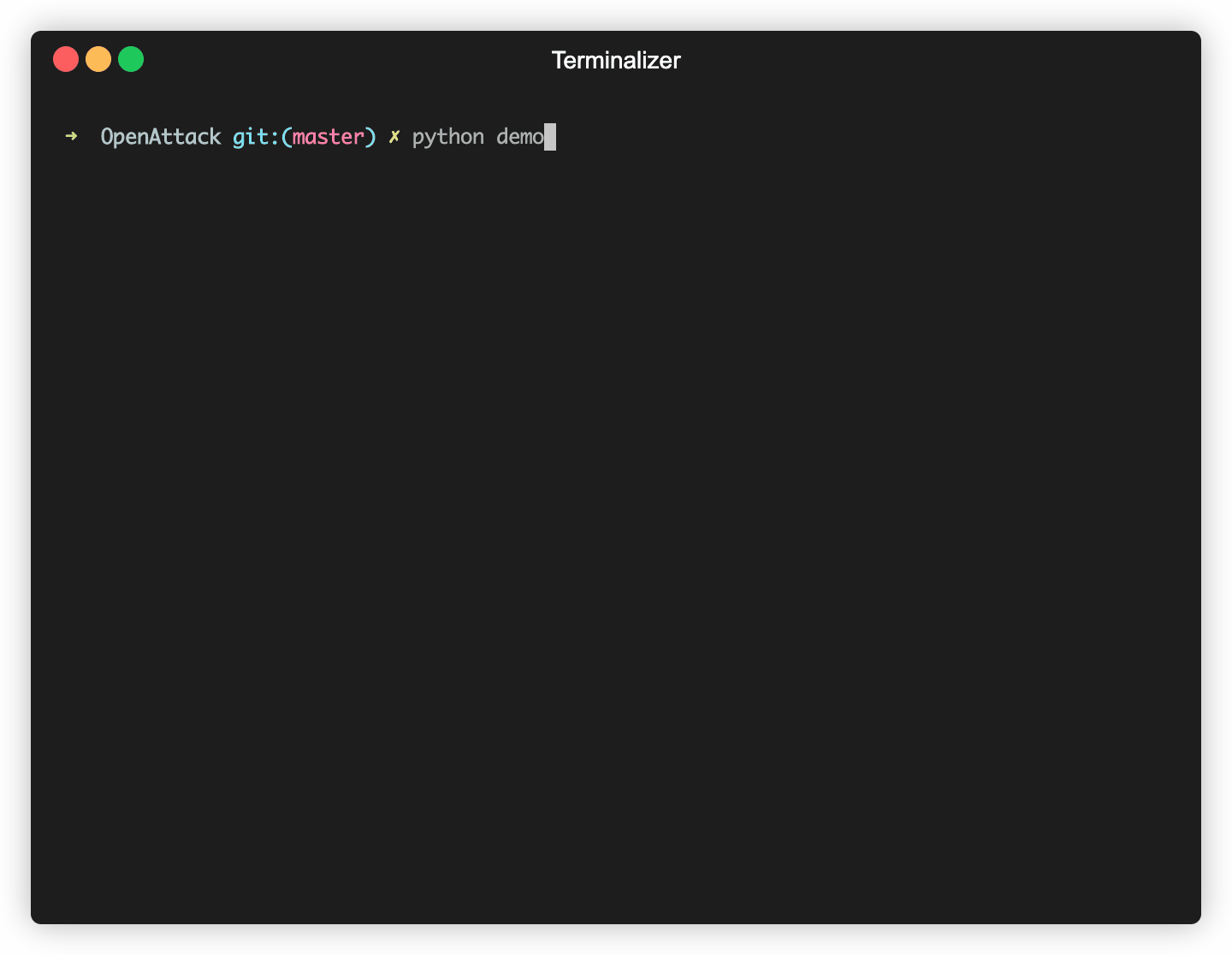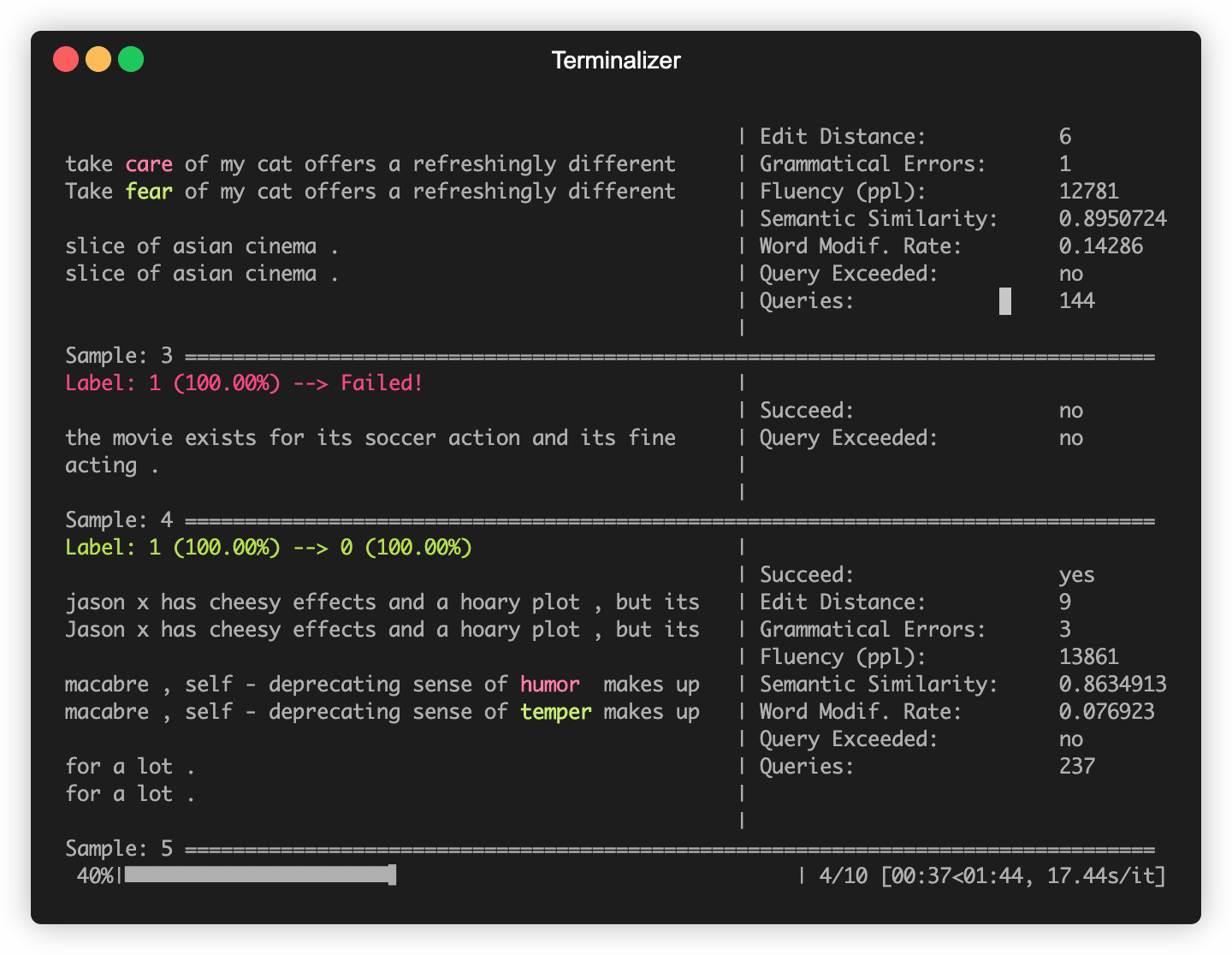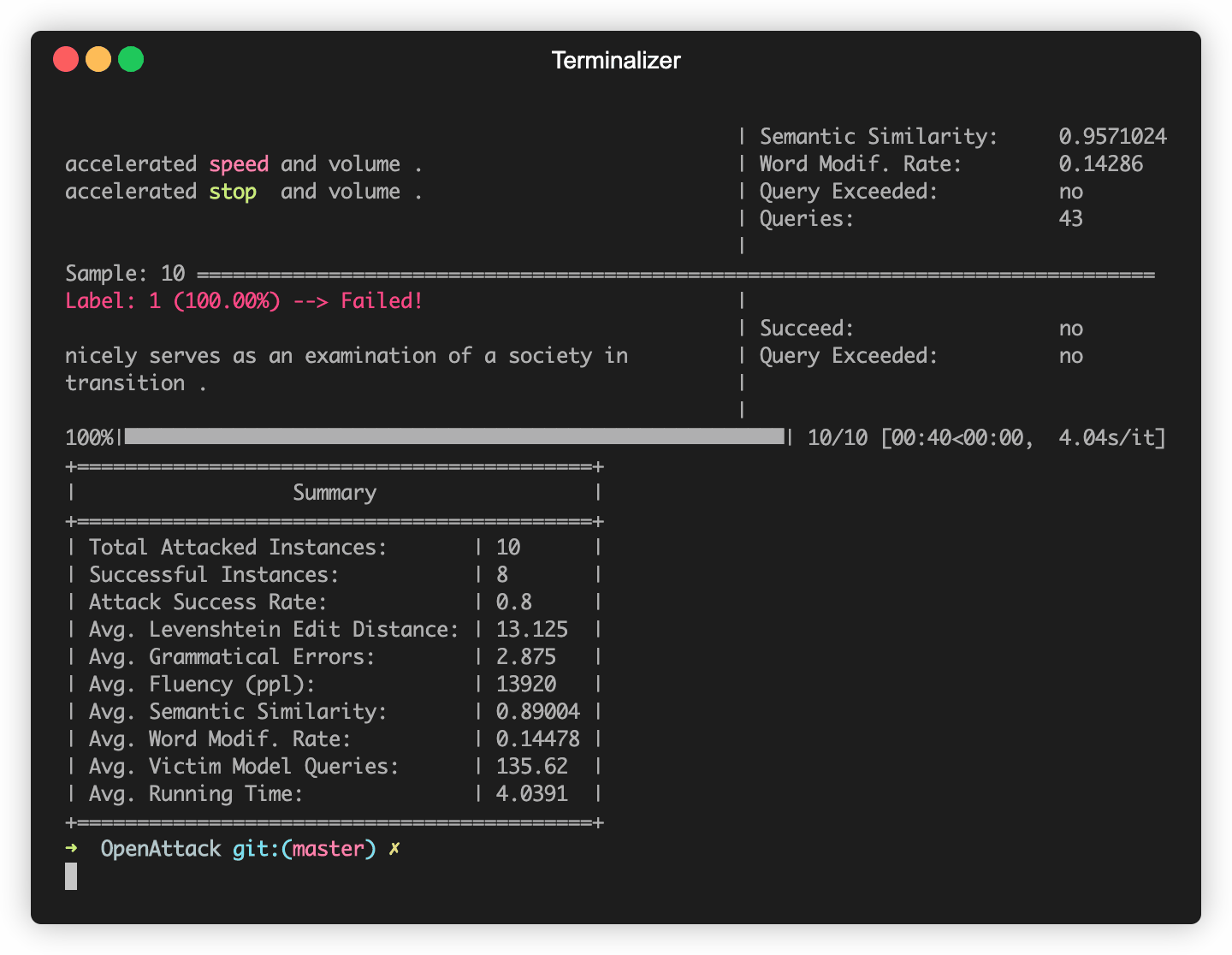
O OpenAttack constrói alguns modelos de PNL comumente usados como Bert (Devlin et al. 2018) e Roberta (Liu et al. 2019) que foram ajustados em alguns conjuntos de dados comumente usados (como o SST-2). Você pode realizar ataques adversários sem esforço contra esses modelos de vítimas embutidos.
O snippet de código a seguir mostra como usar o PWWS, um modelo de ataque ganancioso baseado em algoritmo (Ren et al., 2019), para atacar Bert no conjunto de dados SST-2 (o código executável completo está aqui).
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )O snippet de código a seguir mostra como usar o PWWS para atacar um modelo de análise de sentimentos personalizado (um modelo estatístico construído no NLTK) no SST-2 (o código executável completo está aqui).
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )O snippet de código a seguir mostra como usar o PWWS para atacar um modelo de análise de sentimentos ajustado existente em um conjunto de dados personalizado (o código executável completo está aqui).
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )O OpenAttack suporta multiprocessamento conveniente para acelerar o processo de ataques adversários. O snippet de código a seguir mostra como usar o multiprocessamento em ataques adversários com genético (Alzantot et al. 2018), um modelo de ataque baseado em algoritmo genético (o código executável completo está aqui).
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )O OpenAttack agora suporta ataques adversários contra modelos de vítimas inglesas e chinesas. Aqui está um exemplo de código de condução de ataques adversários contra um modelo de classificação de revisão chinês usando PWWS.
O OpenAttack incorpora muitos componentes úteis que podem ser facilmente montados em novos modelos de ataque. Aqui dá um exemplo de como projetar um modelo de ataque simples que embaralha os tokens na frase original.
O OpenAttack pode gerar facilmente exemplos adversários atacando instâncias no conjunto de treinamento, que podem ser adicionadas ao conjunto de dados de treinamento original para treinar um modelo de vítima mais robusto, ou seja, treinamento adversário. Aqui dá um exemplo de como realizar treinamento adversário com o OpenAttack.
Modelos de classificação de pares de frases de ataque. Além dos modelos de classificação de frases únicas, o OpenAttack suporta ataques contra modelos de classificação de pares de sentenças. Aqui está um exemplo de código de condução de ataques adversários contra um modelo NLI com o OpenAttack.
Métrica de avaliação personalizada. O OpenAttack suporta o design de uma métrica de avaliação de ataque adversário personalizada. Aqui fornece um exemplo de como adicionar uma métrica de avaliação personalizada e usá -la para avaliar ataques adversários.
De acordo com o nível de perturbações impostas à entrada original, os modelos de ataque adversários textuais podem ser categorizados em modelos de ataque no nível da frase e no nível da palavra.
De acordo com a acessibilidade ao modelo da vítima, os modelos de ataque adversários textuais podem ser categorizados em modelos de ataque baseados em gradient , baseados em score , baseados em decision e ataques blind .
Taadpapers é uma lista de papel que resume quase todos os papéis relativos ao ataque e defesa textuais adversários. Você pode dar uma olhada nesta lista para encontrar mais modelos de ataque.
Atualmente, o OpenAttack inclui 15 modelos de ataque típicos contra modelos de classificação de texto que cobrem todos os tipos de ataque.
Aqui está a lista de modelos de ataque atualmente envolvidos.
decision [PDF] [Código]blind [PDF] [Código e Dados]decision [PDF] [Código]score [pdf] [código]score [PDF] [Código]score [PDF] [Código]score [PDF] [Código]score [PDF] [Código]score [pdf] [código]gradient [PDF]score gradient [PDF]gradient [PDF] [Código] [Site]gradient [PDF] [Código]score [PDF] [Código e dados]score [PDF] [Código]A tabela a seguir ilustra a comparação dos modelos de ataque.
| Modelo | Acessibilidade | Perturbação | Idéia principal |
|---|---|---|---|
| MAR | Decisão | Frase | Parafraseamento baseado em regras |
| Scpn | Cego | Frase | Parafraseando |
| Gan | Decisão | Frase | Geração de texto por codificador decodificador |
| TextFooler | Pontuação | Palavra | Substituição de palavra gananciosa |
| PWWS | Pontuação | Palavra | Substituição de palavra gananciosa |
| Genético | Pontuação | Palavra | Substituição de palavra baseada em algoritmo genético |
| Sememepso | Pontuação | Palavra | Substituição de palavras baseada em otimização de partículas |
| Bert-Ataque | Pontuação | Palavra | Substituição de palavra contextualizada gananciosa |
| QUERIDO | Pontuação | Palavra | Substituição e inserção de palavras contextualizadas gananciosas |
| Fd | Gradiente | Palavra | Substituição de palavras baseada em gradiente |
| Textbugger | Gradiente, pontuação | Palavra+char | Substituição de palavra gananciosa e manipulação de caráter |
| Uat | Gradiente | Palavra, char | Manipulação de palavras ou caráter baseada em gradiente |
| Hotflip | Gradiente | Palavra, char | Substituição de palavra ou personagem baseada em gradiente |
| VÍBORA | Cego | Char | Substituição visualmente semelhante de caráter |
| DeepWordBug | Pontuação | Char | Manipulação de caráter ganancioso |
Considerando as distinções significativas entre diferentes modelos de ataque, deixamos uma liberdade considerável para o design do esqueleto dos modelos de ataque e focamos mais em simplificar o processamento geral do ataque adversário e os componentes comuns usados nos modelos de ataque.
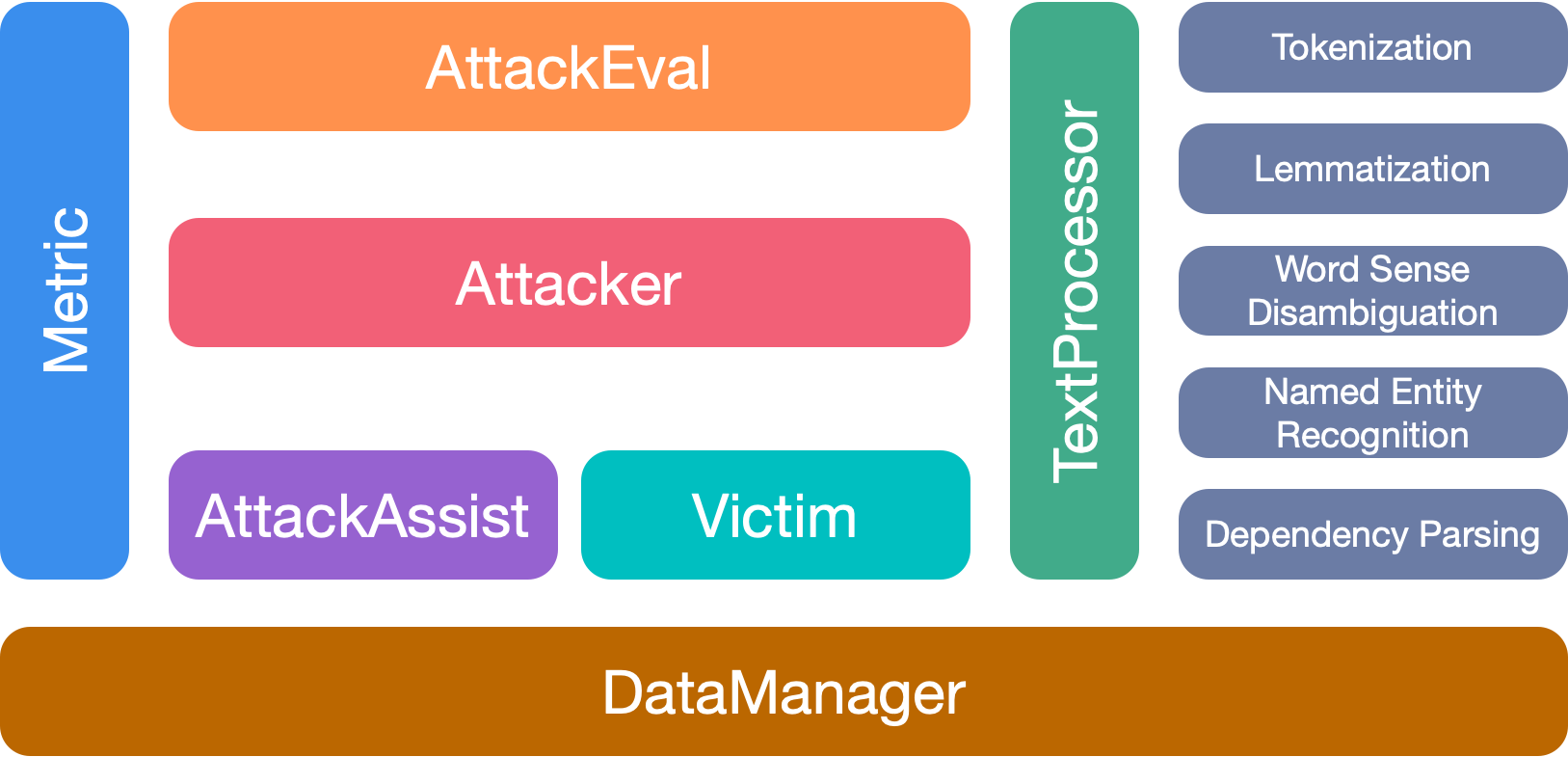
O OpenAttack possui 7 módulos principais:
Cite nosso papel se você usar este kit de ferramentas:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
Agradecemos a todos os colaboradores deste projeto. E mais contribuições são muito bem -vindas.


