OpenAttack
version for datasets

Dokumentation • Funktionen und Verwendungen • Verwendungsbeispiele • Angriffsmodelle • Toolkit -Design
OpenAttack ist ein Open-Source-Basis von Python-basiertem textuellem kontroversen Angriffs-Toolkit, das den gesamten Prozess des textlichen kontroversen Angriffs abwickelt, einschließlich Vorverarbeitungstext, Zugriff auf das Opfermodell, das Erzeugen von kont um und bewertet.
️ Unterstützung für alle Angriffstypen . OpenAttack unterstützt alle Arten von Angriffen, einschließlich Störungen auf Satz-/Wort-/Charakterebene und Gradienten-/Score-/Entscheidungs-/Blind-Angriffsmodelle;
️ Mehrheit . OpenAtChtack unterstützt jetzt Englisch und Chinesisch. Das erweiterbare Design ermöglicht eine schnelle Unterstützung für mehr Sprachen.
️ parallele Verarbeitung . OpenAttack bietet Unterstützung für den Multi-Process-Betrieb von Angriffsmodellen zur Verbesserung der Angriffeffizienz.
️ Kompatibilität mit? Umarmtes Gesicht . OpenAtChtack ist voll integriert in? Transformatoren und Datensätze Bibliotheken;
️ große Erweiterbarkeit . Sie können ein maßgeschneidertes Opfermodell auf jedem angepassten Datensatz problemlos angreifen oder ein maßgeschneidertes Angriffsmodell entwickeln und bewerten.
✅ Bereitstellung verschiedener praktischer Baselines für Angriffsmodelle;
✅ Umfangliche Bewertung von Angriffsmodellen mithilfe seiner gründlichen Bewertungsmetriken;
✅ Unterstützung bei der schnellen Entwicklung neuer Angriffsmodelle mit Hilfe seiner gemeinsamen Angriffskomponenten;
✅ Bewertung der Robustheit eines maschinellen Lernmodells an verschiedenen kontroversen Angriffen;
✅ Durchführung von kontroversem Training zur Verbesserung der Robustheit eines maschinellen Lernmodells durch Anreicherung der Trainingsdaten mit generierten kontroversen Beispielen.
pip (empfohlen) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install Nach der Installation können Sie versuchen, demo.py auszuführen, um zu überprüfen, ob OpenAttack gut funktioniert:
python demo.py
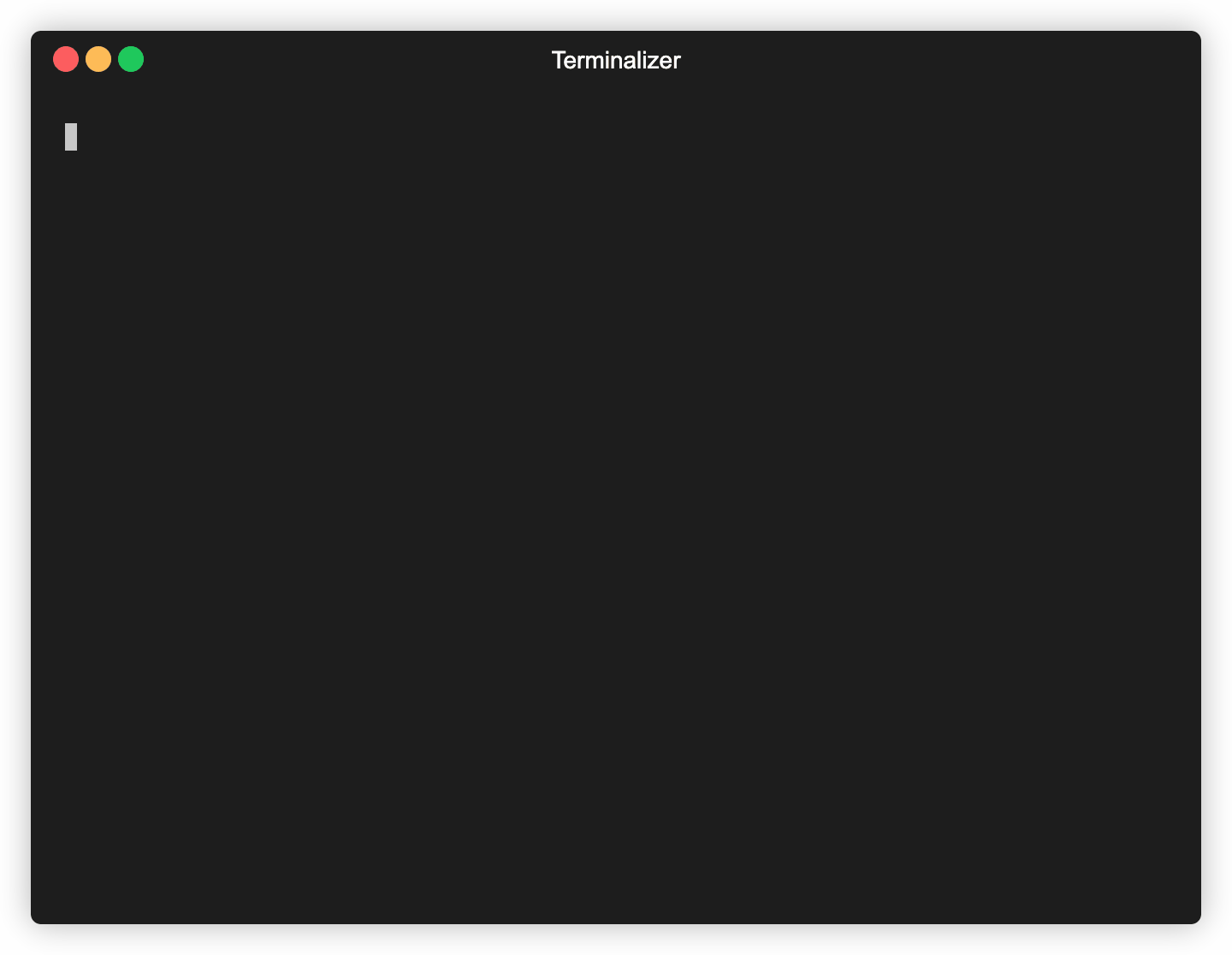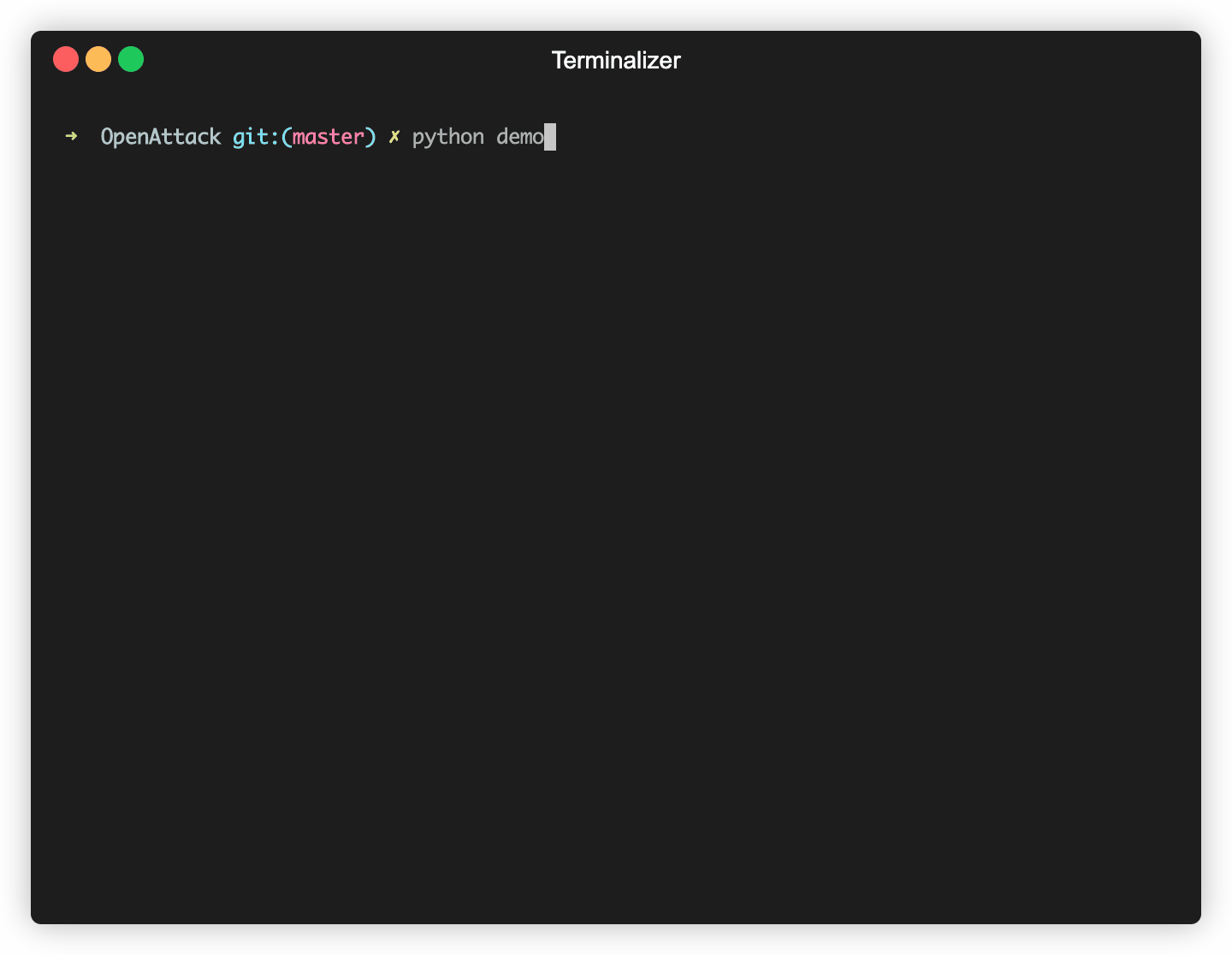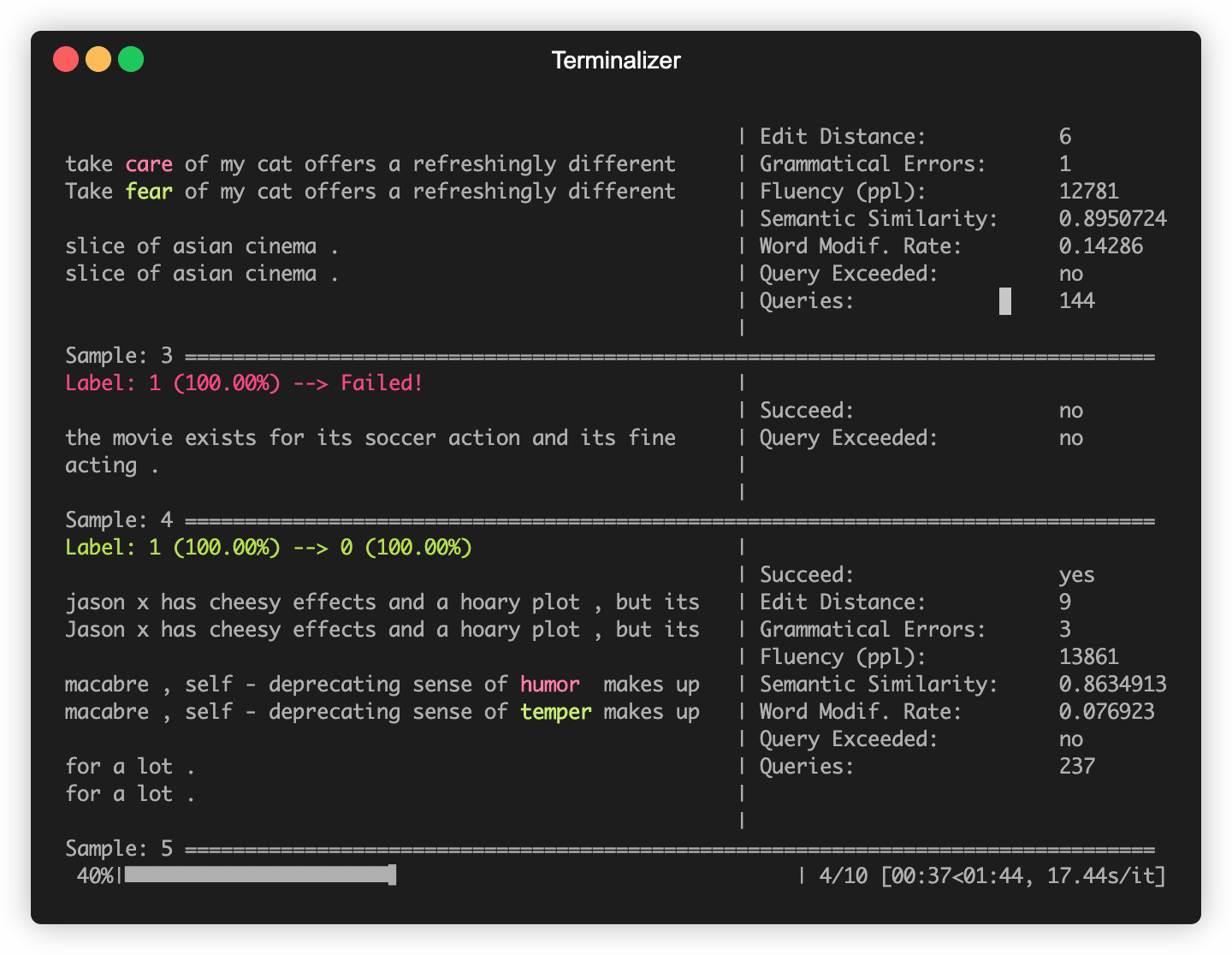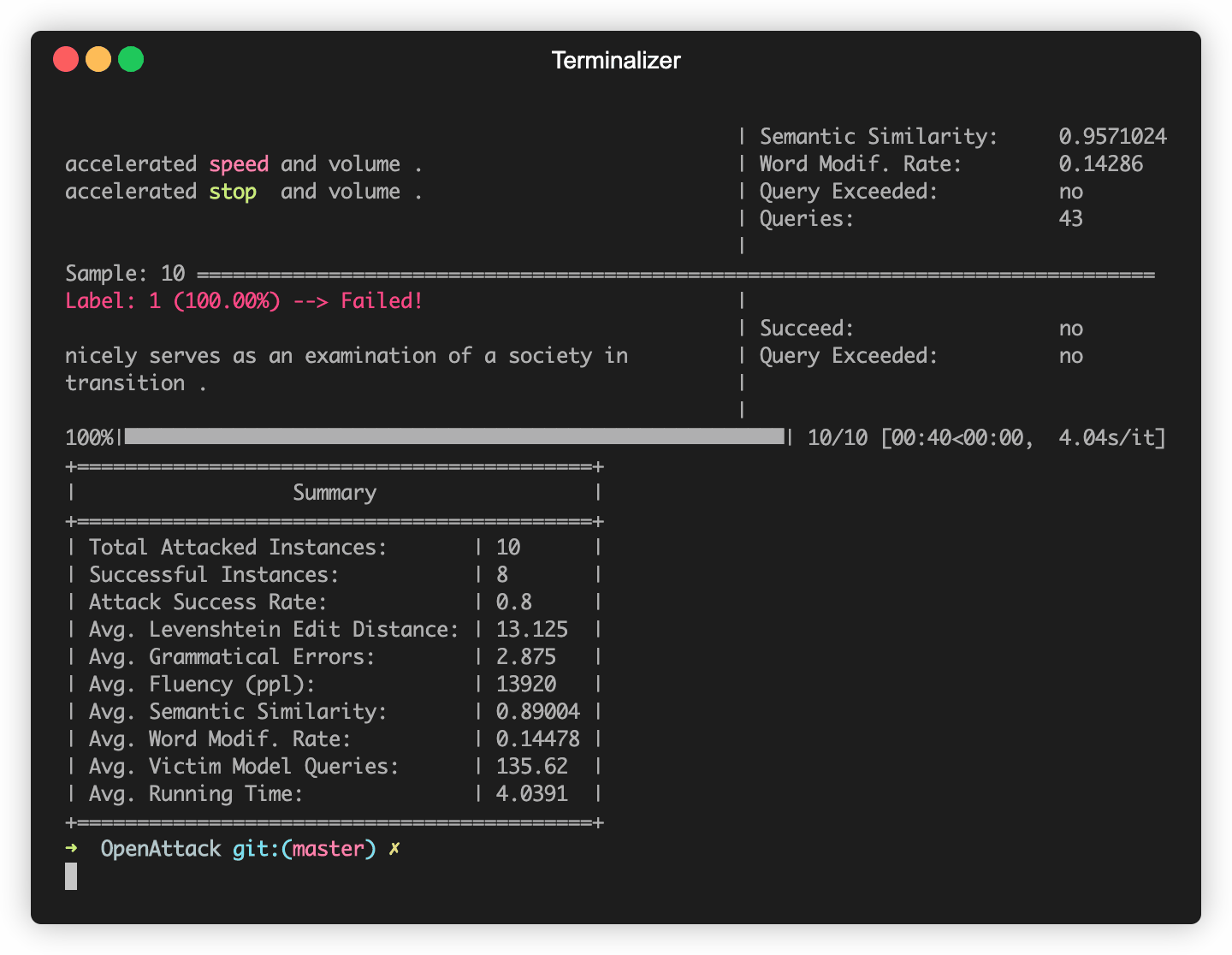
OpenActs-Aufbauten in einigen häufig verwendeten NLP-Modellen wie Bert (Devlin et al. 2018) und Roberta (Liu et al. 2019), die in einigen häufig verwendeten Datensätzen (wie SST-2) fein abgestimmt wurden. Sie können mühelos kontroverse Angriffe gegen diese eingebauten Opfermodelle durchführen.
Das folgende Code-Snippet zeigt, wie PWWS, ein gieriges Algorithmus-basierter Angriffsmodell (Ren et al., 2019), verwendet wird, um Bert auf den SST-2-Datensatz anzugreifen (der vollständige ausführbare Code ist hier).
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )Das folgende Code-Snippet zeigt, wie PWWS verwendet wird, um ein maßgeschneidertes Modellanalysemodell (ein statistisches Modell, das in NLTK eingebaut) auf SST-2 angreift (der vollständige ausführbare Code ist hier).
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )Das folgende Code-Snippet zeigt, wie PWWS verwendet wird, um ein vorhandenes Modell für feine Stimmungsanalyse in einem angepassten Datensatz anzugreifen (der vollständige ausführbare Code ist hier).
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )OpenStack unterstützt eine bequeme Multiprozessierung, um den Prozess der kontroversen Angriffe zu beschleunigen. Das folgende Code-Snippet zeigt, wie die Multiprozessierung bei kontroversen Angriffen mit Genetik verwendet wird (Alzantot et al. 2018), ein genetisches Algorithmus-basierter Angriffsmodell (der vollständige ausführbare Code ist hier).
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )OpenAttack unterstützt nun kontroverse Angriffe gegen englische und chinesische Opfermodelle. Hier finden Sie einen Beispielkodex zur Durchführung von kontroversen Angriffen gegen ein chinesisches Überprüfungsklassifizierungsmodell unter Verwendung von PWWS.
OpenStack umfasst viele praktische Komponenten, die leicht zu neuen Angriffsmodellen zusammengestellt werden können. Hier gibt ein Beispiel dafür, wie man ein einfaches Angriffsmodell entwirft, das die Token im ursprünglichen Satz mischt.
OpenAttack kann problemlos kontroverse Beispiele generieren, indem Instanzen im Trainingssatz angegriffen werden, die zu dem ursprünglichen Trainingsdatensatz hinzugefügt werden können, um ein robusteres Opfermodell, dh über das kontroverse Training, zu senken. Hier gibt es ein Beispiel dafür, wie man mit Openangriff über kontroverses Training durchführt.
Modelle Klassifizierungsmodelle für Satzpaare angreifen. Zusätzlich zu Einzel -Satz -Klassifizierungsmodellen haben OpenAtack -Support -Angriffe gegen Satzpaarklassifizierungsmodelle. Hier ist ein Beispielcode für die Durchführung von kontroversen Angriffen gegen ein NLI -Modell mit OpenPack.
Customized Evaluierungsmetrik. OpenAtChtack unterstützt das Entwerfen einer maßgeschneiderten kontroversen Angriffsbewertungsmetrik. Hier gibt es ein Beispiel dafür, wie Sie eine maßgeschneiderte Bewertungsmetrik hinzufügen und diese zur Bewertung von kontroversen Angriffen verwenden.
Gemäß der Ebene der Störungen, die der ursprünglichen Eingabe auferlegt werden, können textvertretende Angriffsmodelle in Angriffsmodelle auf Satzebene, Wortebene, Charakterebene auf Satzebene eingeteilt werden.
Gemäß der Zugänglichkeit des Opfermodells können textversariale Angriffsmodelle in die Modelle mit gradient , score -Based-, decision und blind -Attack -Modellen eingeteilt werden.
Taadpapers ist eine Papierliste, die fast alle Papiere über den textuellen kontroversen Angriff und die Verteidigung zusammenfasst. Sie können sich diese Liste ansehen, um weitere Angriffsmodelle zu finden.
Derzeit enthält OpenAttack 15 typische Angriffsmodelle gegen Textklassifizierungsmodelle, die alle Angriffstypen abdecken.
Hier ist die Liste der derzeit beteiligten Angriffsmodelle.
decision [PDF] [Code]blind [PDF] [Code & Daten]decision [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]gradient [PDF]gradient score [PDF]gradient [PDF] [Code] [Website]gradient [PDF] [Code]score [PDF] [Code & Daten]score [PDF] [Code]Die folgende Tabelle zeigt den Vergleich der Angriffsmodelle.
| Modell | Zugänglichkeit | Störung | Hauptidee |
|---|---|---|---|
| MEER | Entscheidung | Satz | Regelbasiertes Paraphrasieren |
| Scpn | Blind | Satz | Umschreibung |
| Gan | Entscheidung | Satz | Textgenerierung durch Encoder-Dekododer |
| Textfächer | Punktzahl | Wort | Gierige Wortsubstitution |
| Pwws | Punktzahl | Wort | Gierige Wortsubstitution |
| Genetisch | Punktzahl | Wort | Genetischer Algorithmus-basierter Wortsubstitution |
| Sememepso | Punktzahl | Wort | Partikelschwarmoptimierungsbasierte Wortsubstitution |
| Bert-Angriff | Punktzahl | Wort | Gierig kontextualisierte Wortsubstitution |
| Bae | Punktzahl | Wort | Gierig kontextualisierte Wortsubstitution und Einfügung |
| Fd | Gradient | Wort | Gradientenbasierte Wortsubstitution |
| Textbugger | Gradient, Punktzahl | Wort+Char | Gierige Wortsubstitution und Charaktermanipulation |
| Uat | Gradient | Wort, Char | Gradientenbasierte Wort- oder Charaktermanipulation |
| Hotflip | Gradient | Wort, Char | Gradientenbasierter Wort- oder Charaktersubstitution |
| VIPER | Blind | Verkohlen | Visuell ähnliche Charaktersubstitution |
| Deepwordbug | Punktzahl | Verkohlen | Gierige Charaktermanipulation |
In Anbetracht der erheblichen Unterscheidungen zwischen verschiedenen Angriffsmodellen hinterlassen wir die Skelettdesign von Angriffsmodellen beträchtliche Freiheit und konzentrieren uns mehr auf die allgemeine Verarbeitung von kontroversen Angriffen und die gemeinsamen Komponenten, die in Angriffsmodellen verwendet werden.
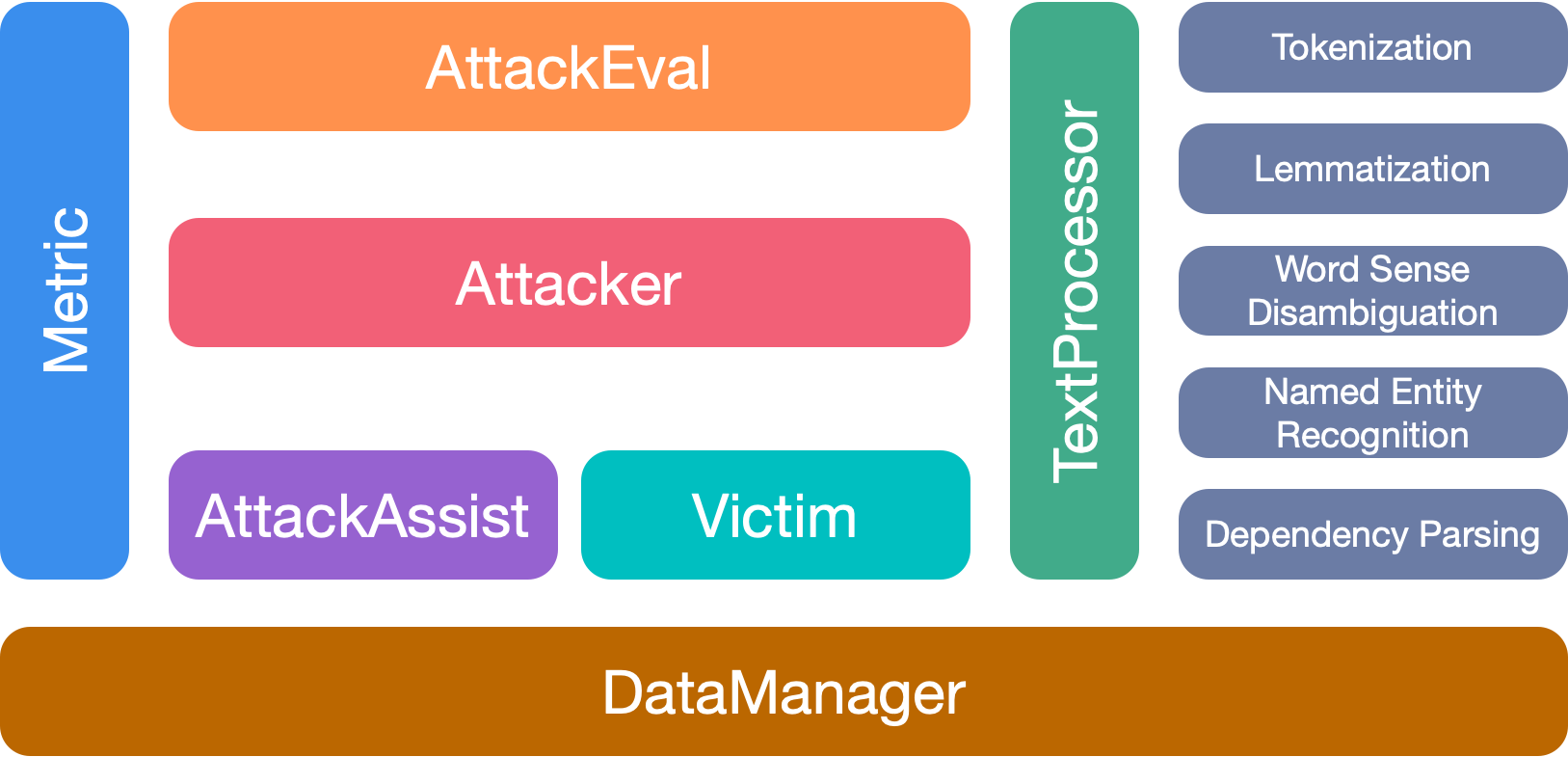
OpenAtChtack hat 7 Hauptmodule:
Bitte zitieren Sie unser Papier, wenn Sie dieses Toolkit verwenden:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
Wir danken allen Mitwirkenden zu diesem Projekt. Und weitere Beiträge sind sehr willkommen.


