OpenAttack
version for datasets

الوثائق • الميزات والاستخدامات • أمثلة الاستخدام • نماذج الهجوم • تصميم مجموعة الأدوات
OpenAttack هي مجموعة أدوات هجوم نصي مفتوح المصدر ، والتي تتولى عملية الهجوم العددي الكامل ، بما في ذلك النص المسبق للمعالجة ، والوصول إلى نموذج الضحية ، وتوليد أمثلة وتقييم عدائي.
️ دعم لجميع أنواع الهجوم . يدعم OpenAttack جميع أنواع الهجمات بما في ذلك الاضطرابات على مستوى الجملة/الكلمات/الأحرف ونماذج الهجوم القائمة على الدقة/النتيجة/النتيجة/القرار ؛
️ متعدد اللغات . يدعم OpenAttack اللغة الإنجليزية والصينية الآن. يتيح تصميمه القابل للتمديد الدعم السريع لمزيد من اللغات ؛
️ المعالجة الموازية . يوفر OpenStack دعمًا للتشغيل متعدد العمليات لنماذج الهجوم لتحسين كفاءة الهجوم ؛
️ التوافق مع؟ الوجه المعانقة . OpenAttack مدمج بالكامل؟ المحولات ومكتبات مجموعات البيانات ؛
️ قابلية التوسيع الكبيرة . يمكنك بسهولة مهاجمة نموذج ضحية مخصص على أي مجموعة بيانات مخصصة أو تطوير وتقييم نموذج هجوم مخصص.
✅ توفير مختلف خطوط الأساس المفيدة لنماذج الهجوم ؛
✅ تقييم نماذج الهجوم بشكل شامل باستخدام مقاييس التقييم الشاملة ؛
✅ المساعدة في التطوير السريع لنماذج الهجوم الجديدة بمساعدة مكونات الهجوم المشتركة ؛
✅ تقييم متانة نموذج التعلم الآلي ضد مختلف هجمات العدواني ؛
✅ إجراء التدريب المكافآت لتحسين متانة نموذج التعلم الآلي من خلال إثراء بيانات التدريب بأمثلة عدوانية تم إنشاؤها.
pip (موصى به) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install بعد التثبيت ، يمكنك محاولة تشغيل demo.py للتحقق مما إذا كان OpenAttack يعمل بشكل جيد:
python demo.py
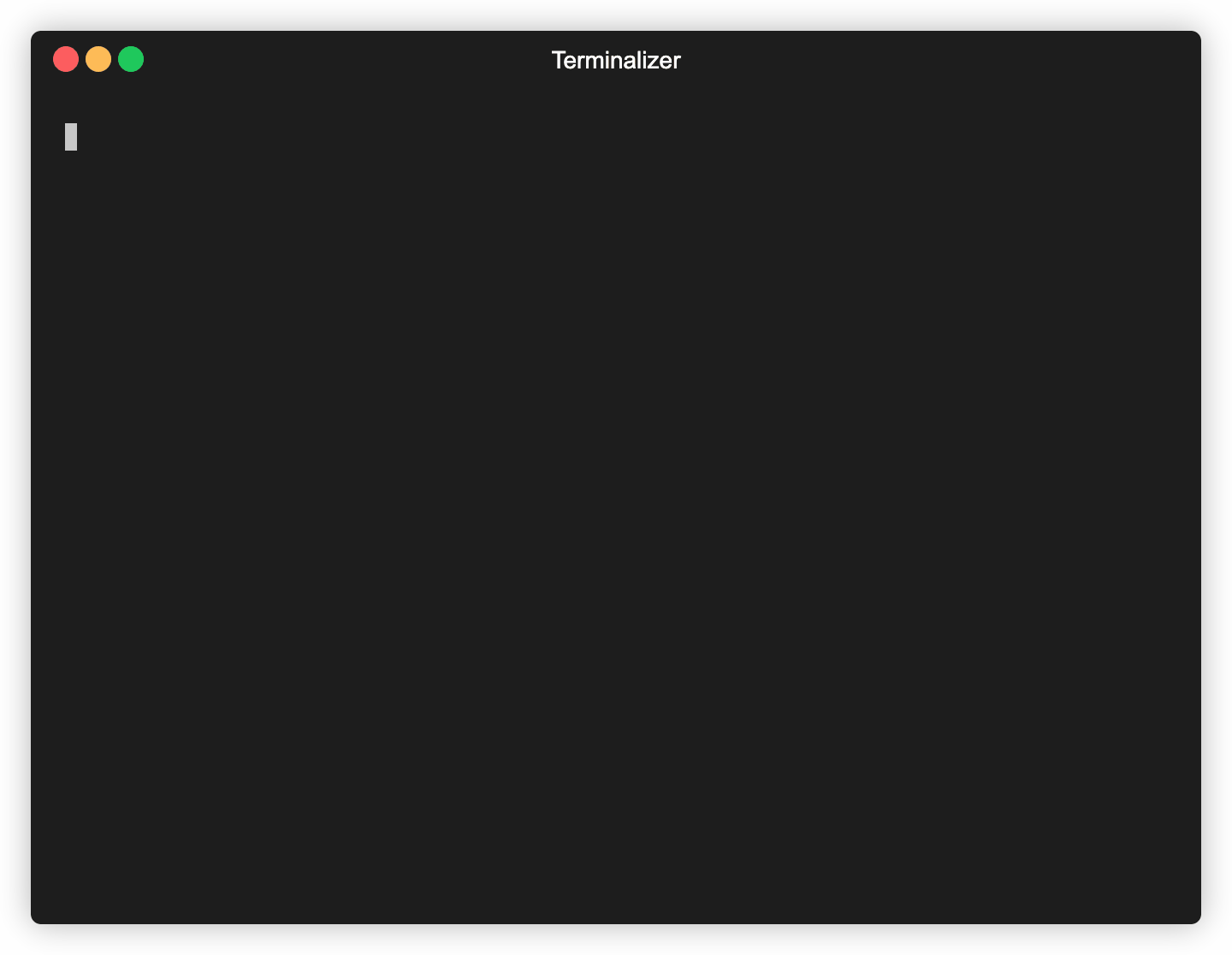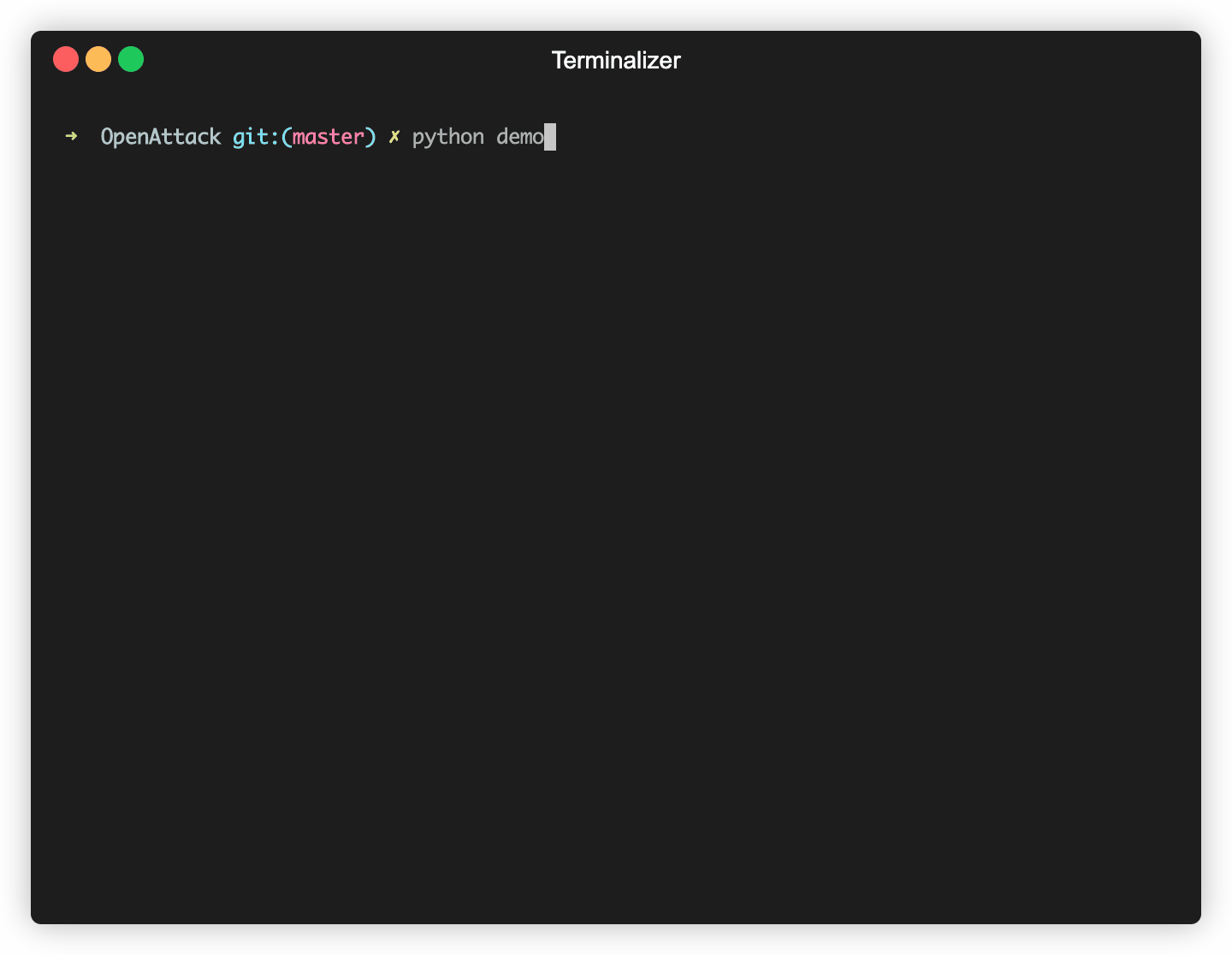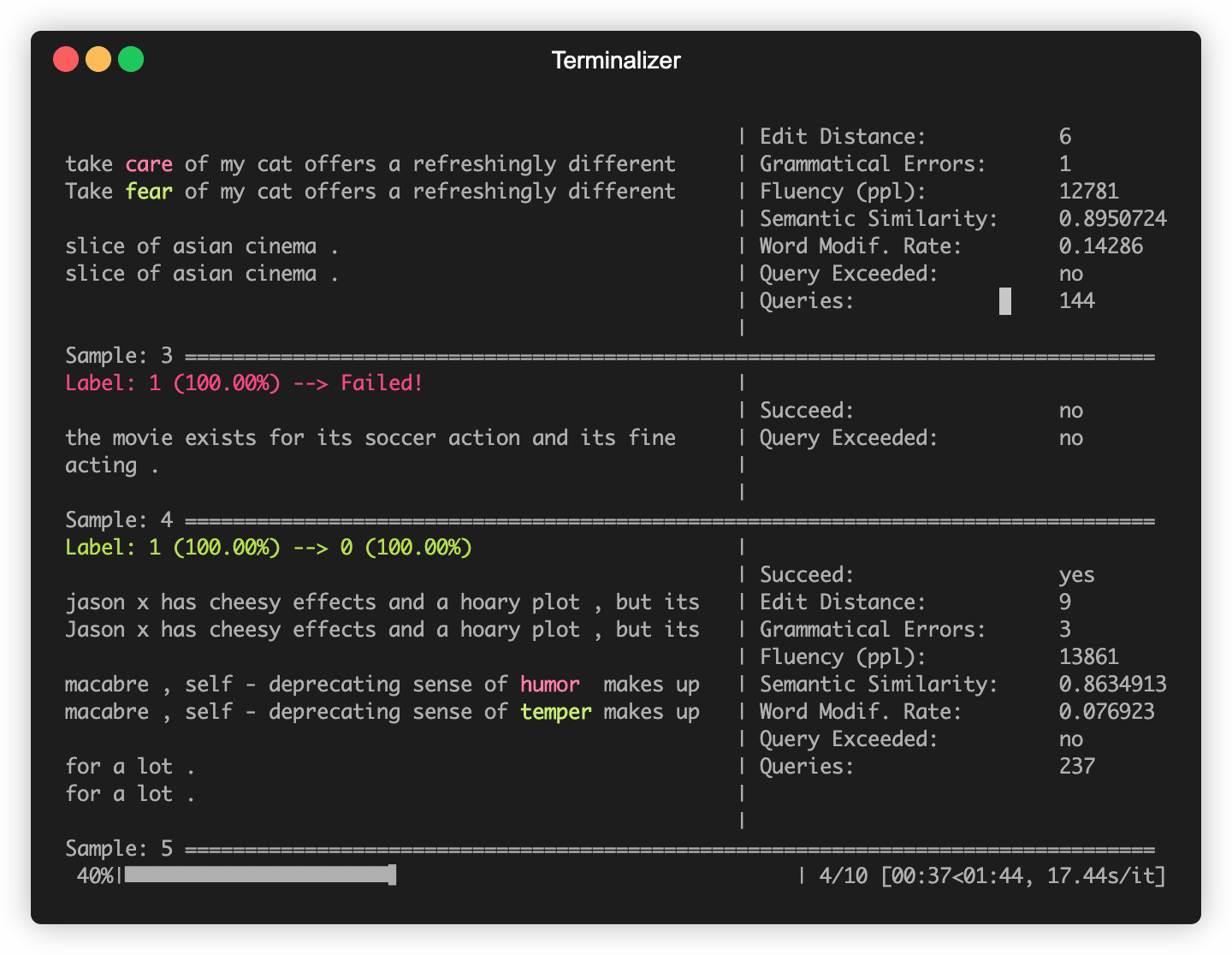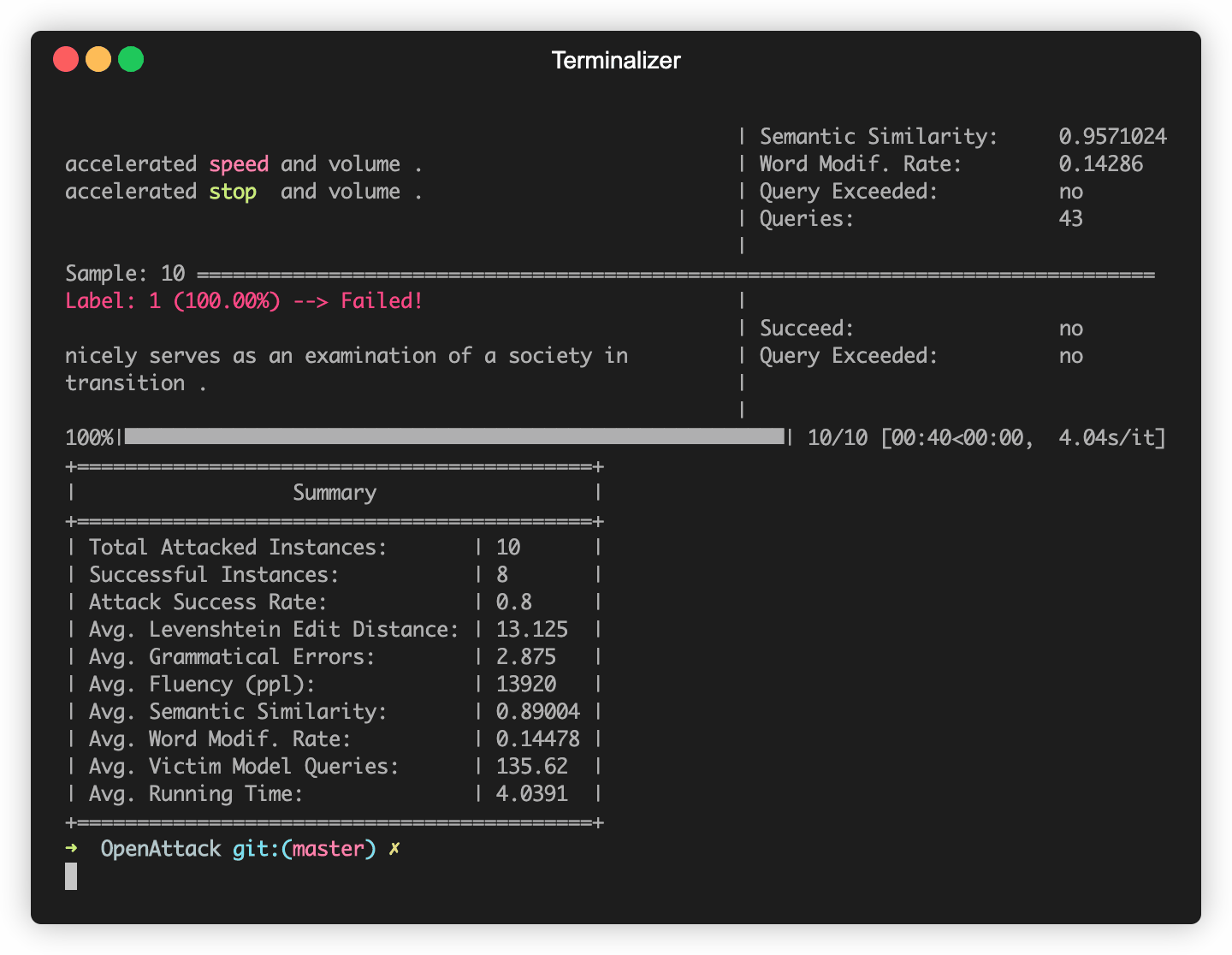
يبني OpenAttack في بعض نماذج NLP شائعة الاستخدام مثل Bert (Devlin et al. 2018) وروبرتا (Liu et al. 2019) التي تم ضبطها على بعض مجموعات البيانات الشائعة الاستخدام (مثل SST-2). يمكنك إجراء هجمات عدوانية ضد نماذج الضحايا المدمجة هذه.
يوضح مقتطف الكود التالي كيفية استخدام PWWS ، وهو نموذج هجوم قائم على الخوارزمية الجشع (Ren et al. ، 2019) ، لمهاجمة Bert على مجموعة بيانات SST-2 (الرمز القابل للتنفيذ الكامل هنا).
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )يوضح مقتطف الكود التالي كيفية استخدام PWWS لمهاجمة نموذج تحليل المشاعر المخصص (نموذج إحصائي مدمج في NLTK) على SST-2 (الرمز القابل للتنفيذ الكامل هنا).
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )يوضح مقتطف الكود التالي كيفية استخدام PWWS لمهاجمة نموذج تحليل المعنويات الذي تم ضبطه بشكل جيد على مجموعة بيانات مخصصة (الرمز القابل للتنفيذ الكامل هنا).
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )يدعم OpenAttack المعالجة المتعددة المريحة لتسريع عملية الهجمات العدائية. يوضح مقتطف الكود التالي كيفية استخدام المعالجة المتعددة في هجمات الخصومة مع الوراثة (Alzantot et al. 2018) ، وهو نموذج هجوم قائم على الخوارزمية الوراثية (الرمز القابل للتنفيذ الكامل هنا).
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )يدعم OpenAttack الآن هجمات الخصومة ضد نماذج الضحايا الإنجليزية والصينية. فيما يلي مثال على ذلك رمز لإجراء هجمات خصودية ضد نموذج تصنيف المراجعة الصينية باستخدام PWWS.
يشتمل OpenStack على العديد من المكونات المفيدة التي يمكن تجميعها بسهولة في نماذج هجوم جديدة. هنا يعطي مثالاً على كيفية تصميم نموذج هجوم بسيط يختلط الرموز في الجملة الأصلية.
يمكن لـ OpenAttack بسهولة إنشاء أمثلة عدوانية من خلال مهاجمة الحالات في مجموعة التدريب ، والتي يمكن إضافتها إلى مجموعة بيانات التدريب الأصلية لإعادة تدريب نموذج ضحية أكثر قوة ، أي تدريب عدواني. هنا يعطي مثالا على كيفية إجراء التدريب العدواني مع OpenStack.
نماذج تصنيف زوج الجملة الهجوم. بالإضافة إلى نماذج تصنيف الجملة الفردية ، فإن OpenAttack دعم الهجمات ضد نماذج تصنيف زوج الجملة. فيما يلي مثال رمز لإجراء هجمات خصودية ضد نموذج NLI مع OpenTatk.
مقياس التقييم المخصص. يدعم OpenAttack تصميم مقياس تقييم هجوم الخصومة المخصص. هنا يعطي مثالًا على كيفية إضافة مقياس تقييم مخصص واستخدامه لتقييم هجمات العدوانية.
وفقًا لمستوى الاضطرابات المفروضة على المدخلات الأصلية ، يمكن تصنيف نماذج الهجوم العدائية النصي إلى نماذج هجوم على مستوى الجملة ومستوى الكلمات.
وفقًا لنموذج الوصول إلى نموذج الضحية ، يمكن تصنيف نماذج هجوم الخصومة النصي إلى نماذج الهجوم القائمة على gradient ، والمستندة إلى score ، والقائمة على decision blind .
Taadpapers هي قائمة ورقية تلخص تقريبًا جميع الأوراق المتعلقة بالهجوم والدفاع العددي النصي. يمكنك إلقاء نظرة على هذه القائمة للعثور على المزيد من نماذج الهجوم.
يتضمن OpenTatch حاليًا 15 نموذجًا للهجوم النموذجي مقابل نماذج تصنيف النص التي تغطي جميع أنواع الهجوم.
فيما يلي قائمة نماذج الهجوم المشاركة حاليًا.
decision [PDF] [رمز]blind [PDF] [الكود والبيانات]decision [PDF] [رمز]score [PDF] [رمز]score [PDF] [رمز]score [PDF] [CODE]score [PDF] [رمز]score [PDF] [رمز]score [PDF] [رمز]gradient [PDF]score gradient [PDF]gradient [PDF] [رمز] [موقع ويب]gradient [PDF] [رمز]score [PDF] [الكود والبيانات]score [PDF] [CODE]يوضح الجدول التالي مقارنة نماذج الهجوم.
| نموذج | إمكانية الوصول | اضطراب | الفكرة الرئيسية |
|---|---|---|---|
| بحر | قرار | جملة | إعادة الصياغة القائمة على القواعد |
| SCPN | أعمى | جملة | إعادة صياغة |
| جان | قرار | جملة | توليد النص بواسطة ترميز التشفير |
| TextFooler | نتيجة | كلمة | استبدال الكلمات الجشع |
| PWWS | نتيجة | كلمة | استبدال الكلمات الجشع |
| وراثي | نتيجة | كلمة | استبدال الكلمات القائم على الخوارزمية الجينية |
| sememepso | نتيجة | كلمة | استبدال الكلمات القائم على سرب الجسيمات |
| هجوم بيرت | نتيجة | كلمة | استبدال الكلمات الجشعية السياقية |
| يا صديقي | نتيجة | كلمة | استبدال الكلمات الجشع والإدراج |
| FD | التدرج | كلمة | استبدال الكلمات القائم على التدرج |
| TextBugger | التدرج ، النتيجة | كلمة+شار | استبدال الكلمات الجشع والتلاعب بالشخصيات |
| uat | التدرج | كلمة ، شار | الكلمة القائمة على التدرج أو معالجة الأحرف |
| Hotflip | التدرج | كلمة ، شار | كلمة قائمة على التدرج أو استبدال الشخصية |
| أفعى | أعمى | شار | استبدال الشخصية المشابهة بصريًا |
| DeepWordBug | نتيجة | شار | معالجة الشخصية الجشع |
بالنظر إلى الفروق الكبيرة بين نماذج الهجوم المختلفة ، نترك حرية كبيرة لتصميم الهيكل العظمي لنماذج الهجوم ، والتركيز بشكل أكبر على تبسيط المعالجة العامة للهجوم العدائي والمكونات الشائعة المستخدمة في نماذج الهجوم.
OpenAttack يحتوي على 7 وحدات رئيسية:
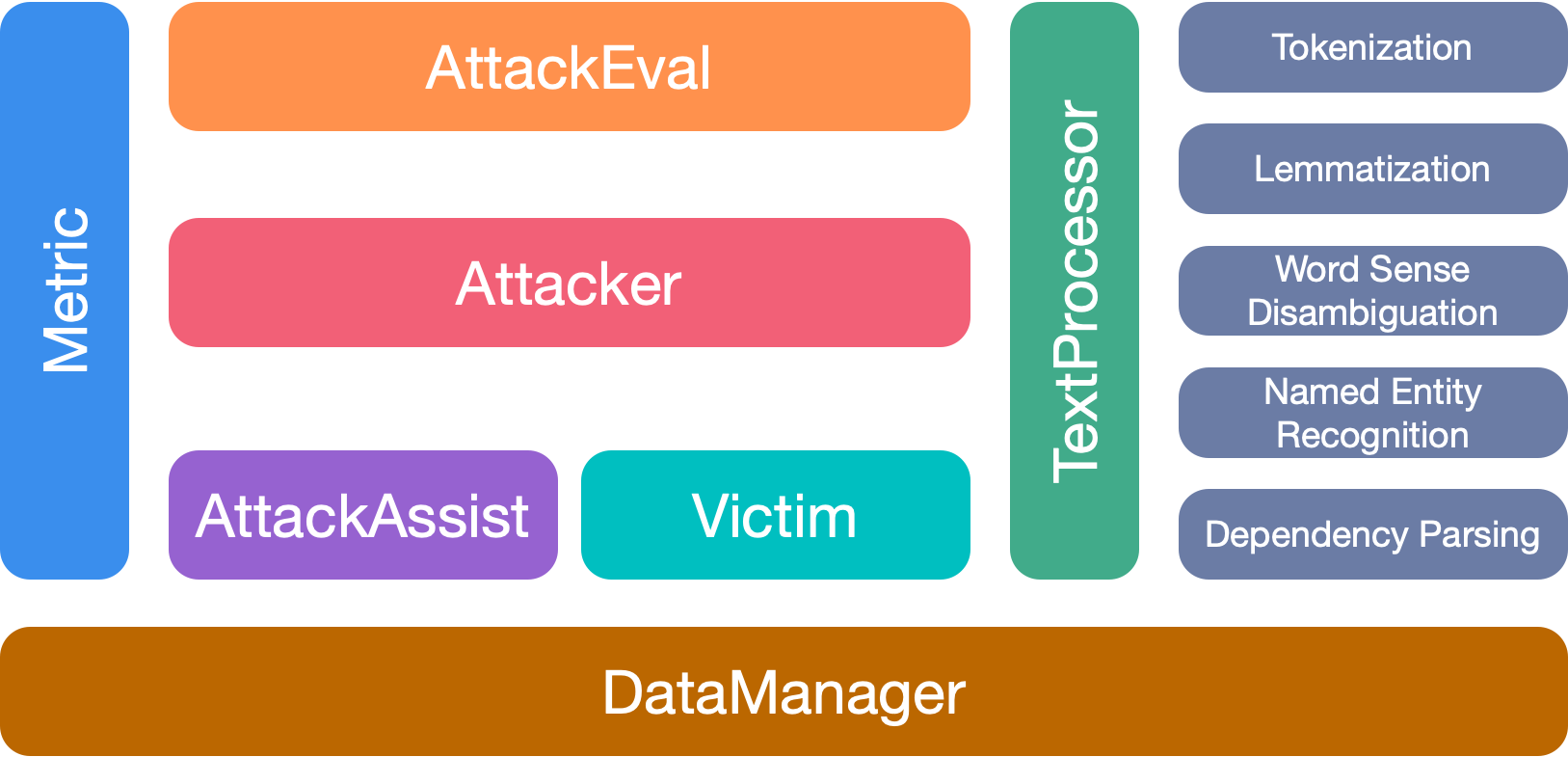
يرجى الاستشهاد بالورقة إذا كنت تستخدم مجموعة الأدوات هذه:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
نشكر جميع المساهمين في هذا المشروع. والمزيد من المساهمات موضع ترحيب للغاية.


