OpenAttack
version for datasets

ドキュメント•機能と使用•使用例•攻撃モデル•ツールキット設計
OpenAttackは、オープンソースベースのテキスト敵対的な攻撃ツールキットであり、前処理テキスト、被害者モデルへのアクセス、敵対例の生成、評価など、テキストの敵対的攻撃のプロセス全体を処理します。
§すべての攻撃タイプのサポート。 OpenAttackは、文 - /単語/文字レベルの摂動や勾配/スコア/決定ベース/ブラインド攻撃モデルを含むあらゆる種類の攻撃をサポートします。
§多言語性。 OpenAttackは現在、英語と中国語をサポートしています。その拡張可能な設計により、より多くの言語を迅速にサポートできます。
§並列処理。 OpenAttackは、攻撃効率を改善するための攻撃モデルのマルチプロセスランニングをサポートしています。
§との互換性?顔を抱き締める。 OpenAttackは完全に統合されていますか?トランスとデータセットライブラリ。
§大きな拡張性。カスタマイズされたデータセットでカスタマイズされた被害者モデルを簡単に攻撃したり、カスタマイズされた攻撃モデルを開発および評価できます。
attack攻撃モデルにさまざまな便利なベースラインを提供します。
cortion徹底的な評価メトリックを使用して、攻撃モデルを包括的に評価します。
common共通攻撃コンポーネントの助けを借りて、新しい攻撃モデルの迅速な開発を支援する。
andさまざまな敵対的攻撃に対する機械学習モデルの堅牢性を評価する。
condual敵の例でトレーニングデータを豊かにすることにより、機械学習モデルの堅牢性を改善するために敵対的なトレーニングを実施します。
pipの使用(推奨) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py installインストール後、 demo.pyを実行してOpenTackがうまく機能するかどうかを確認してみてください。
python demo.py
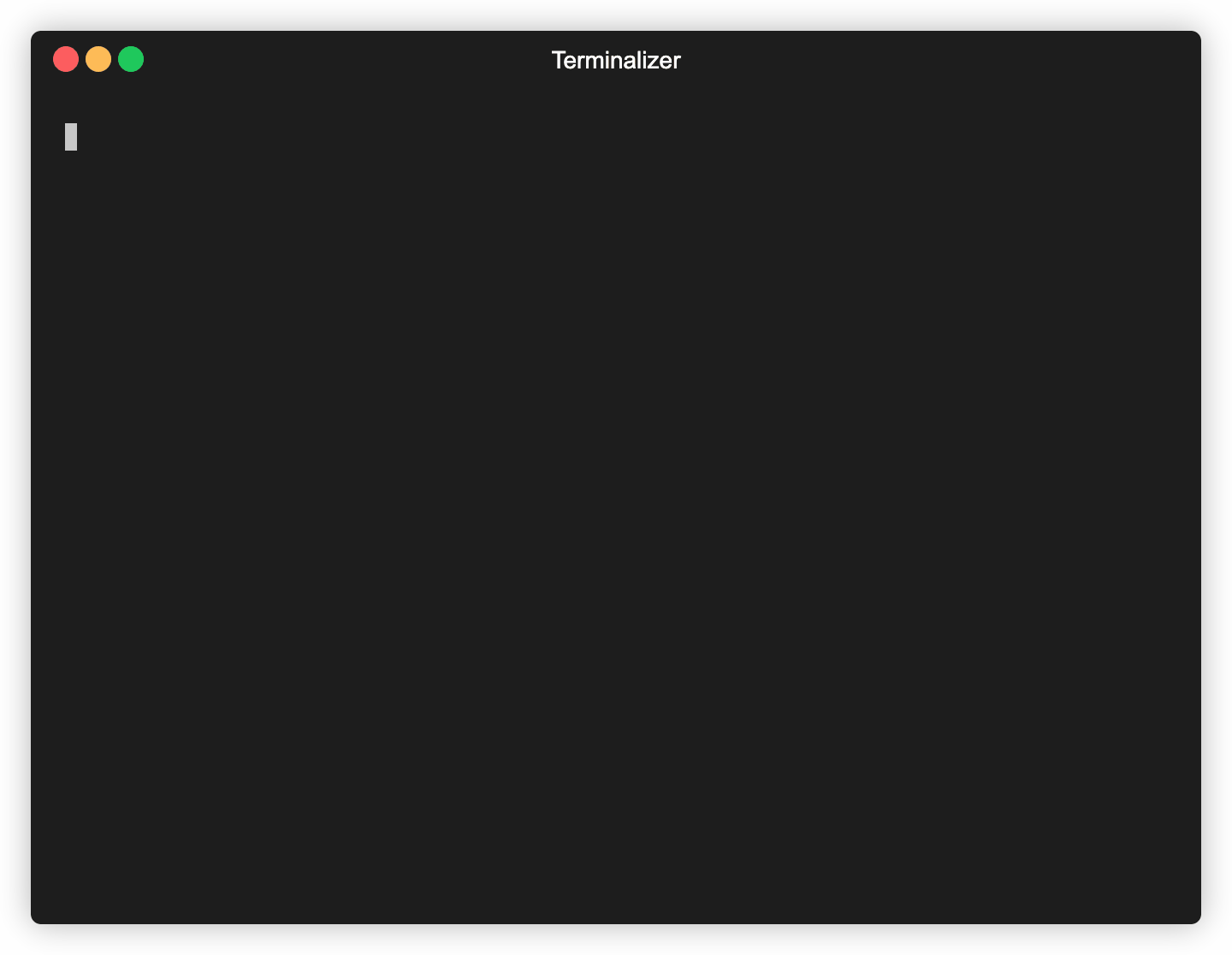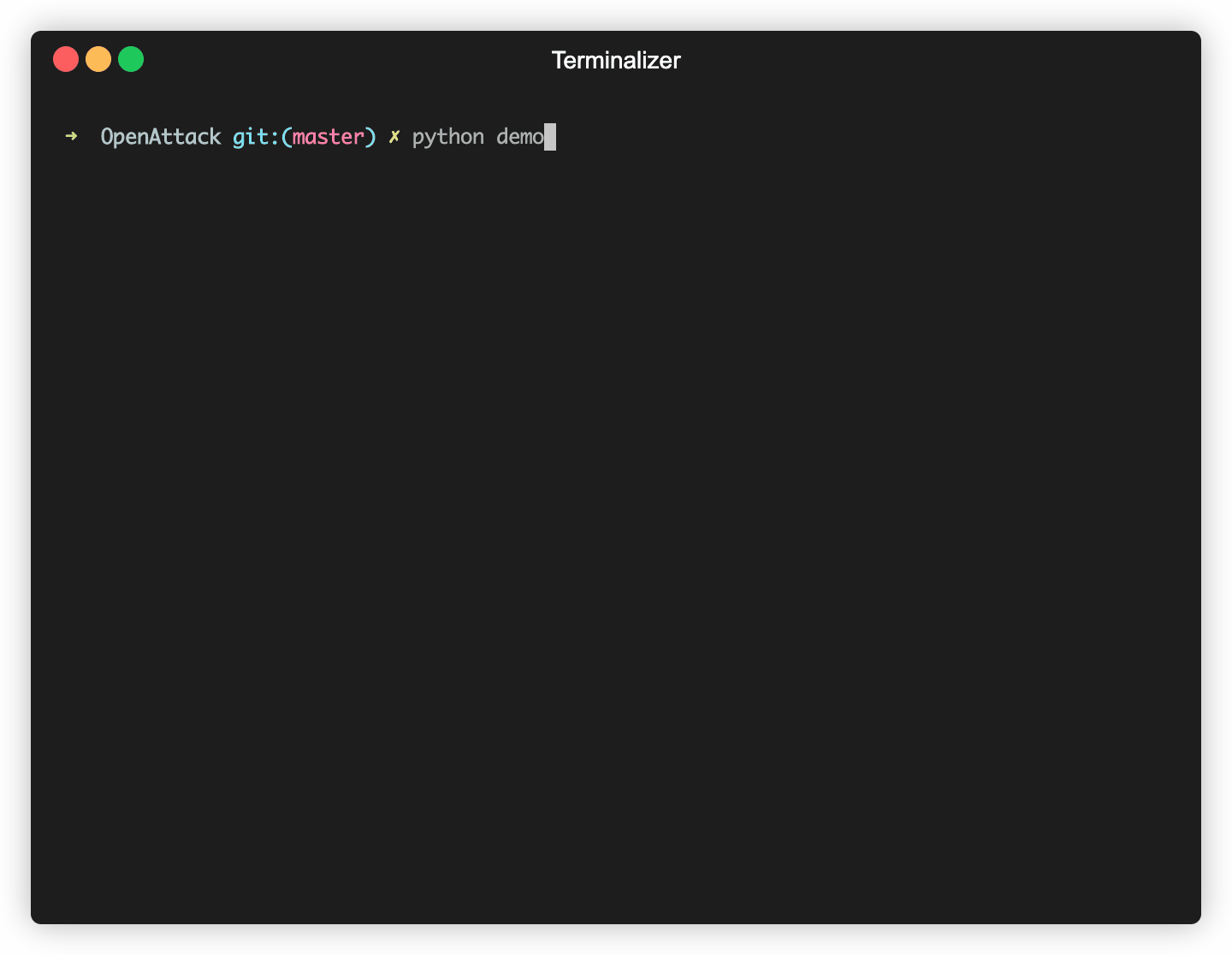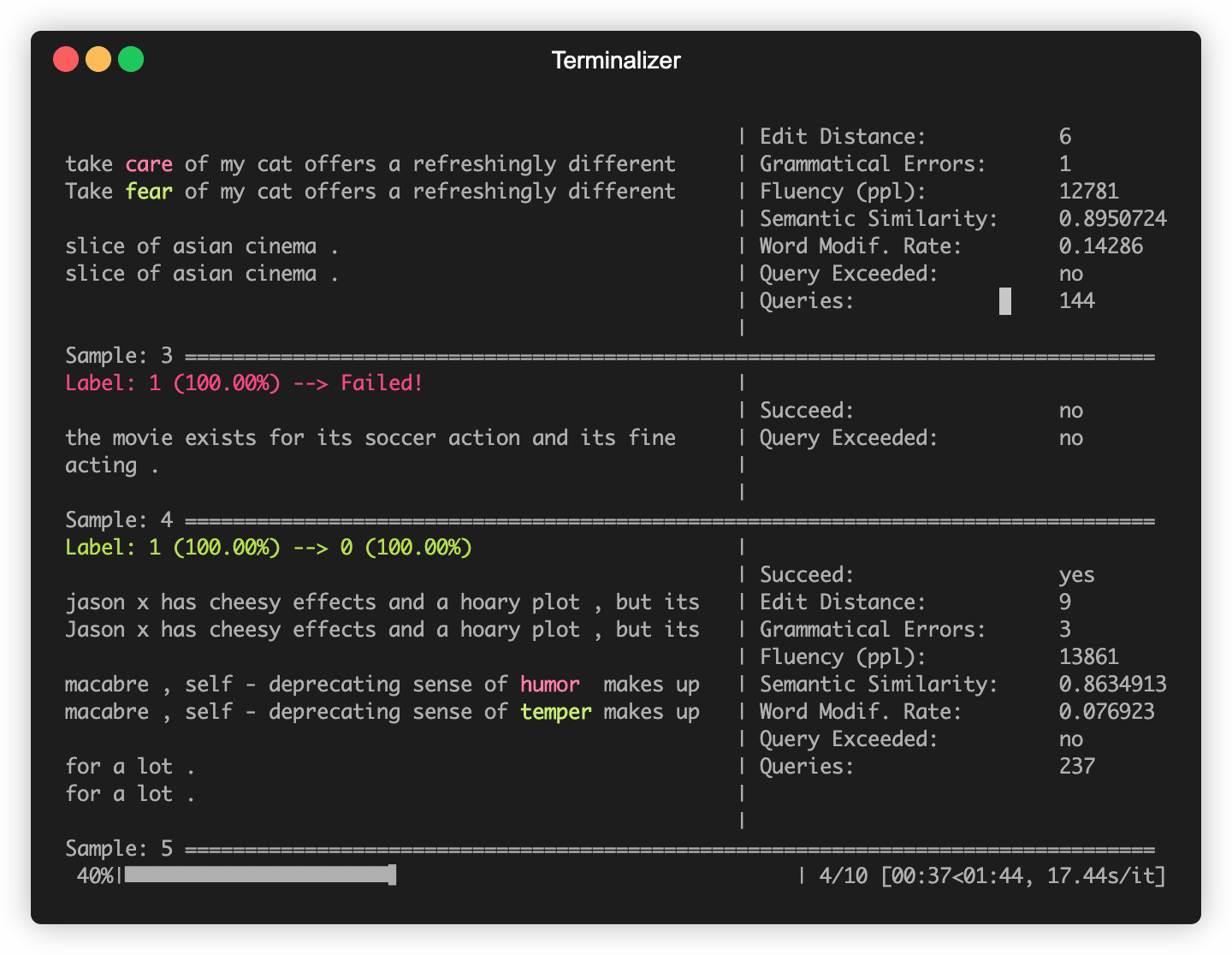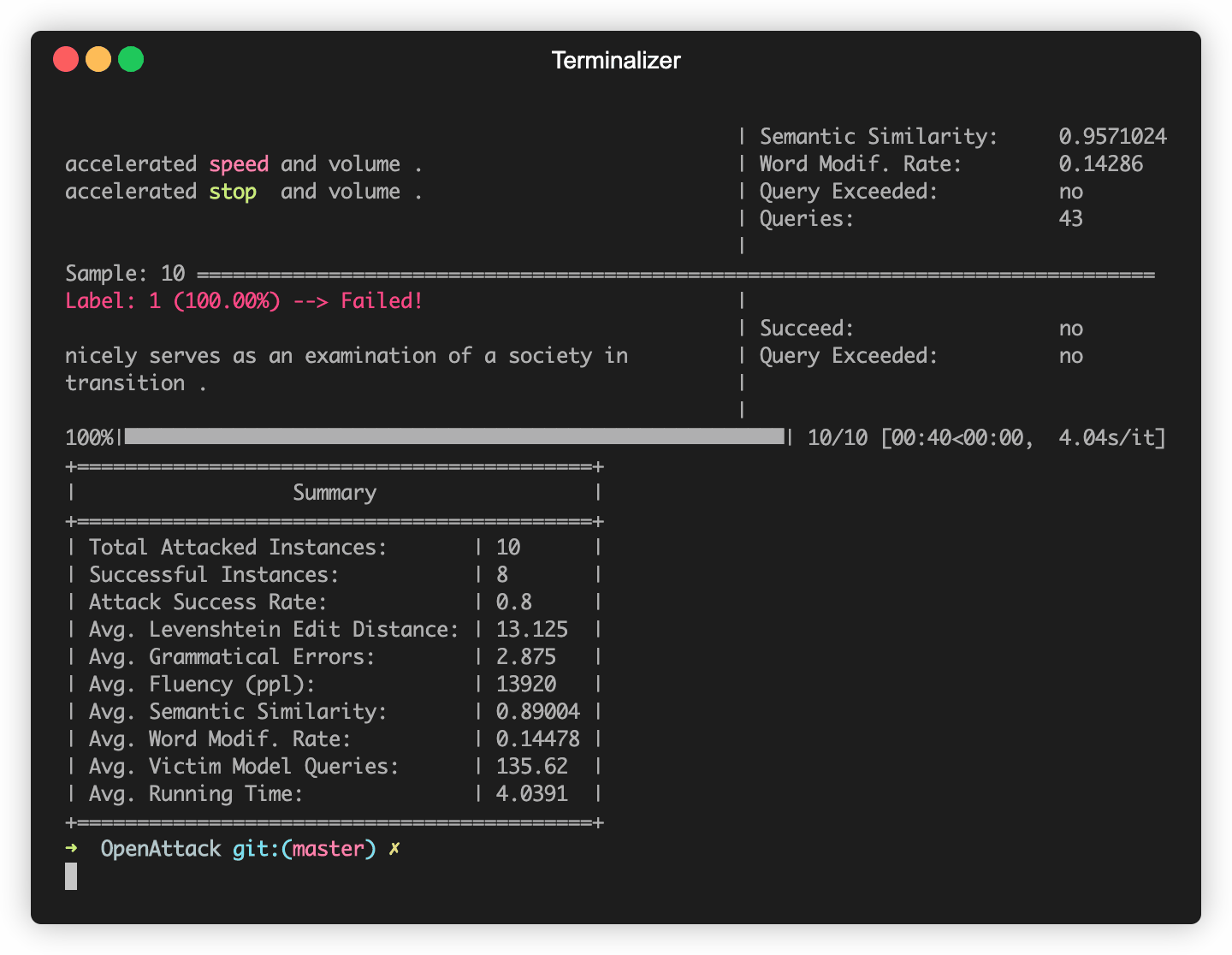
OpenAttackは、一般的に使用されるデータセット(SST-2など)で微調整されているBert(Devlin etal。2018)やRoberta(Liu etal。2019)などの一般的に使用されるNLPモデルで構築されています。これらの組み込みの犠牲者モデルに対して敵対的な攻撃を楽に行うことができます。
次のコードスニペットは、貪欲なアルゴリズムベースの攻撃モデル(Ren et al。、2019)であるPWWSの使用方法を示しており、SST-2データセットでBERTを攻撃します(完全な実行可能性コードはこちら)。
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )次のコードスニペットは、PWWSを使用して、SST-2のカスタマイズされたセンチメント分析モデル(NLTKに構築された統計モデル)を攻撃する方法を示しています(完全な実行可能可能性コードはこちら)。
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )次のコードスニペットは、PWWを使用してカスタマイズされたデータセットで既存の微調整されたセンチメント分析モデルを攻撃する方法を示しています(完全な実行可能性コードはこちらです)。
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )OpenAttackは、敵対的な攻撃のプロセスを加速するための便利なマルチプロセシングをサポートします。次のコードスニペットは、遺伝的アルゴリズムベースの攻撃モデルである遺伝的攻撃(Alzantot etal。2018)を使用した敵対的攻撃でマルチプロセスを使用する方法を示しています(完全な実行可能性コードはこちら)。
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )OpenAttackは現在、英語と中国の被害者モデルに対する敵対的な攻撃をサポートしています。 PWWを使用した中国のレビュー分類モデルに対して敵対的攻撃を実施するコードの例です。
OpenAttackには、新しい攻撃モデルに簡単に組み立てることができる多くの便利なコンポーネントが組み込まれています。ここでは、元の文のトークンをシャッフルする単純な攻撃モデルを設計する方法の例を示します。
OpenAttackは、トレーニングセットのインスタンスを攻撃することで敵対例を簡単に生成できます。これを元のトレーニングデータセットに追加して、より堅牢な犠牲者モデル、つまり敵対的なトレーニングを再訓練できます。ここでは、OpenAttackで敵対的なトレーニングを行う方法の例を示します。
攻撃文のペア分類モデル。単一文の分類モデルに加えて、OpenAttackは文ペア分類モデルに対する攻撃をサポートします。以下は、OpenAttackを使用してNLIモデルに対して敵対的な攻撃を実施するコードの例です。
カスタマイズされた評価メトリック。 OpenAttackは、カスタマイズされた敵対攻撃評価メトリックの設計をサポートしています。ここでは、カスタマイズされた評価メトリックを追加し、それを使用して敵対的な攻撃を評価する方法の例を示します。
元の入力に課された摂動のレベルによれば、テキストの敵対的攻撃モデルは、文レベルの単語レベルの文字レベルの攻撃モデルに分類できます。
被害者モデルへのアクセシビリティによれば、テキストの敵対的攻撃モデルは、 scoreベースのgradientベース、 decisionベース、 blind攻撃モデルに分類できます。
Taadpapersは、テキストの敵対的攻撃と防御に関するほぼすべての論文をまとめたペーパーリストです。このリストを見て、より多くの攻撃モデルを見つけることができます。
現在、OpenTackには、すべての攻撃タイプをカバーするテキスト分類モデルに対する15の典型的な攻撃モデルが含まれています。
現在関与している攻撃モデルのリストは次のとおりです。
decision [PDF] [コード]blind [PDF] [コードとデータ]decision [PDF] [コード]score [PDF] [コード]score [PDF] [コード]score [PDF] [コード]score [PDF] [コード]score [PDF] [コード]score [PDF] [コード]gradient [PDF]gradient score [PDF]gradient -ijcnlp2019。gradient[pdf] [code] [webサイト]gradient [PDF] [コード]score [PDF] [コードとデータ]score [PDF] [コード]次の表は、攻撃モデルの比較を示しています。
| モデル | アクセシビリティ | 摂動 | 本旨 |
|---|---|---|---|
| 海 | 決断 | 文 | ルールベースの言い換え |
| scpn | 盲目 | 文 | 言い換え |
| ガン | 決断 | 文 | エンコーダデコーダーによるテキスト生成 |
| TextFooler | スコア | 言葉 | 貪欲な言葉代替 |
| PWWS | スコア | 言葉 | 貪欲な言葉代替 |
| 遺伝的 | スコア | 言葉 | 遺伝的アルゴリズムベースの単語代替 |
| sememepso | スコア | 言葉 | 粒子群群最適化ベースの単語代替 |
| バート攻撃 | スコア | 言葉 | 貪欲な文脈化された単語代替 |
| bae | スコア | 言葉 | 貪欲な文脈化された単語の置換と挿入 |
| FD | 勾配 | 言葉 | 勾配ベースの単語代替 |
| TextBugger | グラデーション、スコア | Word+Char | 貪欲な言葉の代替とキャラクターの操作 |
| uat | 勾配 | 単語、char | 勾配ベースの単語または文字操作 |
| ホットフリップ | 勾配 | 単語、char | 勾配ベースの単語またはキャラクターの代替 |
| ヴァイパー | 盲目 | char | 視覚的に類似した特性置換 |
| deepwordbug | スコア | char | 貪欲な性格の操作 |
異なる攻撃モデル間の重要な違いを考慮すると、攻撃モデルのスケルトン設計にかなりの自由を残し、攻撃モデルで使用される敵対的な攻撃の一般的な処理と共通のコンポーネントの合理化にさらに焦点を当てます。
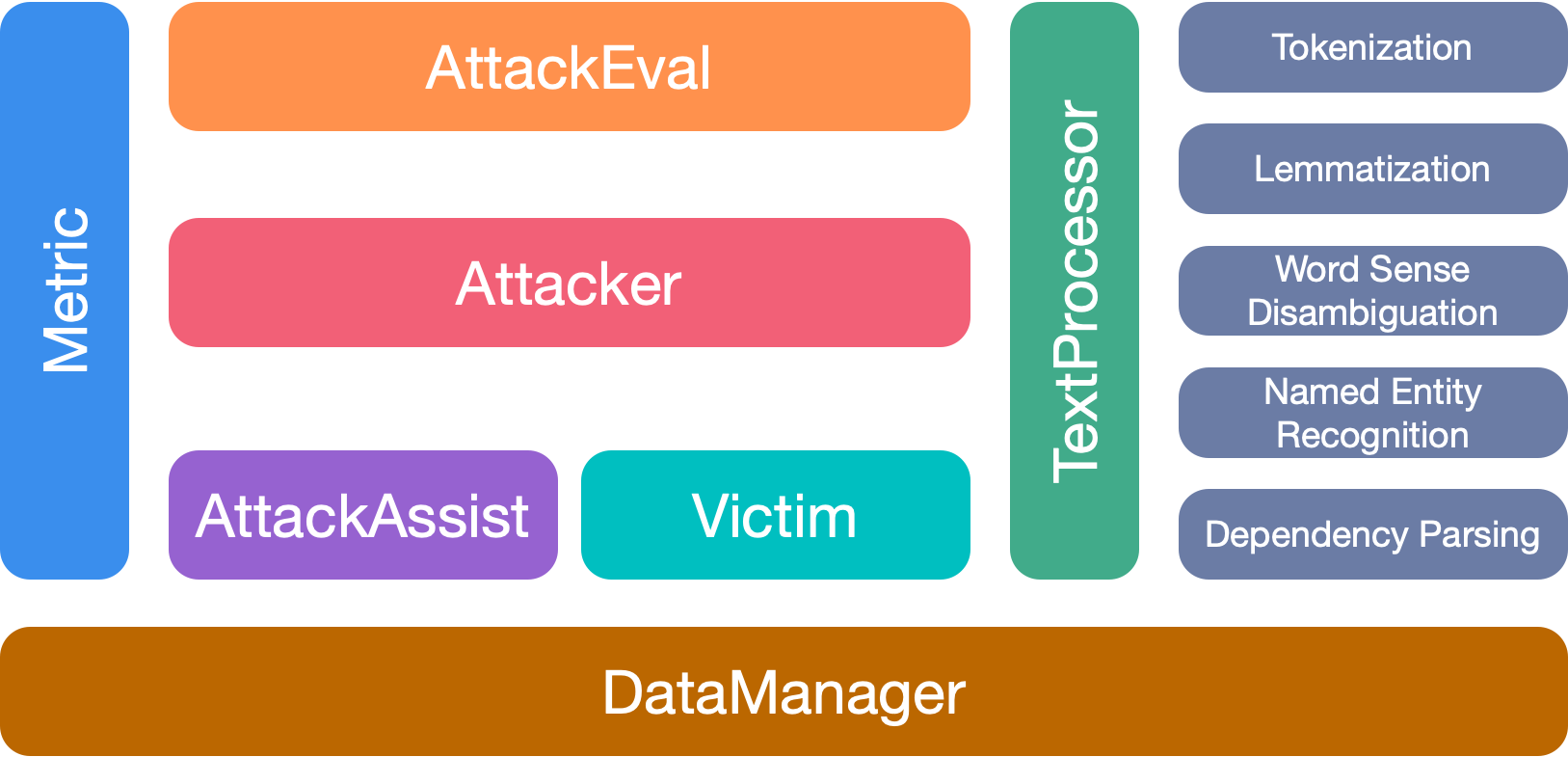
OpenAttackには7つの主要なモジュールがあります。
このツールキットを使用する場合は、私たちの論文を引用してください。
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
このプロジェクトへのすべての貢献者に感謝します。そして、より多くの貢献は大歓迎です。


