OpenAttack
version for datasets

문서 • 기능 및 용도 • 사용 예제 • 공격 모델 • 툴킷 디자인
OpenAttack은 오픈 소스 파이썬 기반 텍스트 적대적 공격 툴킷으로, 전처리 텍스트, 피해자 모델에 액세스, 적대 예제 및 평가를 포함한 텍스트 적대 공격의 전체 프로세스를 처리합니다.
모든 공격 유형에 대한 지원 . Openattack은 문장/단어/문자 수준의 섭동 및 그라디언트/점수/의사 결정 기반/블라인드 공격 모델을 포함한 모든 유형의 공격을 지원합니다.
닐 다국어 . Openattack은 현재 영어와 중국어를 지원합니다. 확장 가능한 디자인을 사용하면 더 많은 언어를 빠르게 지원할 수 있습니다.
바 병렬 처리 . Openattack은 공격 효율성을 향상시키기 위해 공격 모델의 다중 프로세스 실행을 지원합니다.
️ 와 호환성? 포옹 얼굴 . Openattack이 완전히 통합되어 있습니까? 변압기 및 데이터 세트 라이브러리;
Ø 큰 확장 성 . 맞춤형 데이터 세트에서 맞춤형 피해자 모델을 쉽게 공격하거나 맞춤형 공격 모델을 개발하고 평가할 수 있습니다.
Attack 공격 모델에 대한 다양한 편리한 기준을 제공합니다.
respong 철저한 평가 지표를 사용하여 공격 모델을 종합적으로 평가합니다 .
∎ 일반적인 공격 구성 요소의 도움으로 새로운 공격 모델 의 빠른 개발을 지원합니다.
✅ 다양한 적대적 공격에 대한 기계 학습 모델의 견고성 평가;
producearial 트레이닝 데이터를 생성 된 적대적 예제로 풍부하게함으로써 기계 학습 모델의 견고성을 향상시키기 위해 적대 훈련을 수행합니다.
pip 사용 (권장) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install 설치 후 demo.py 실행하여 OpenAttack이 제대로 작동하는지 확인할 수 있습니다.
python demo.py
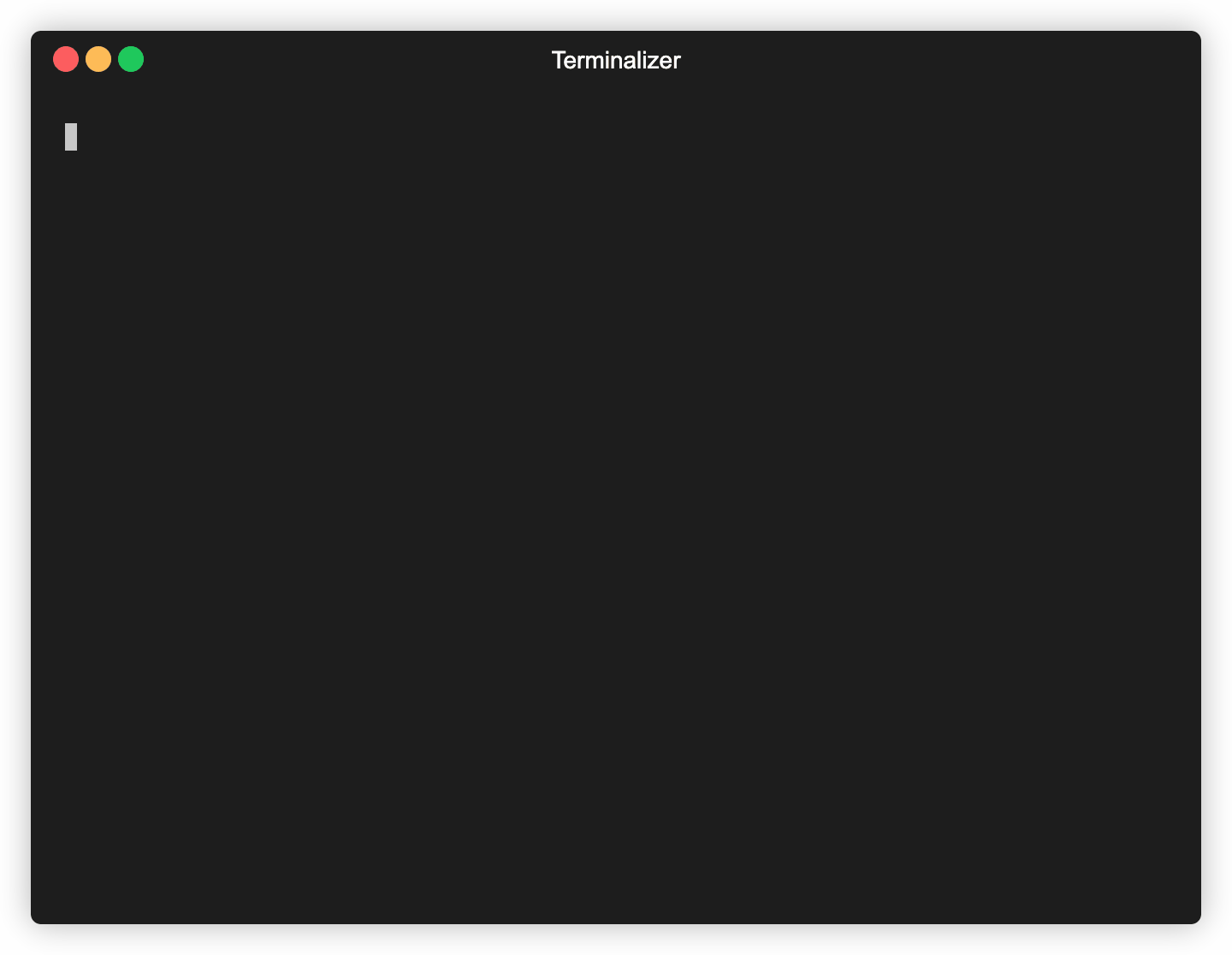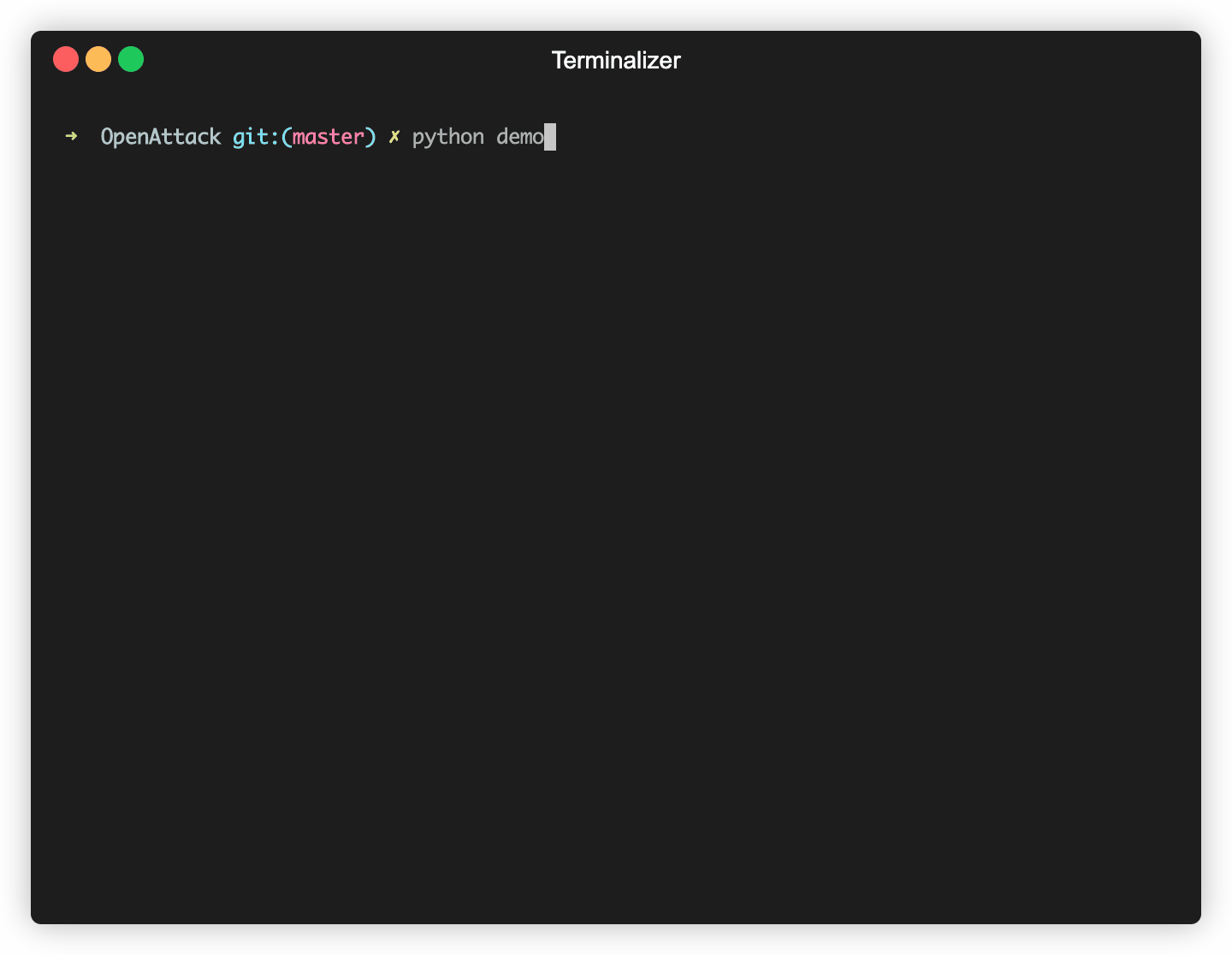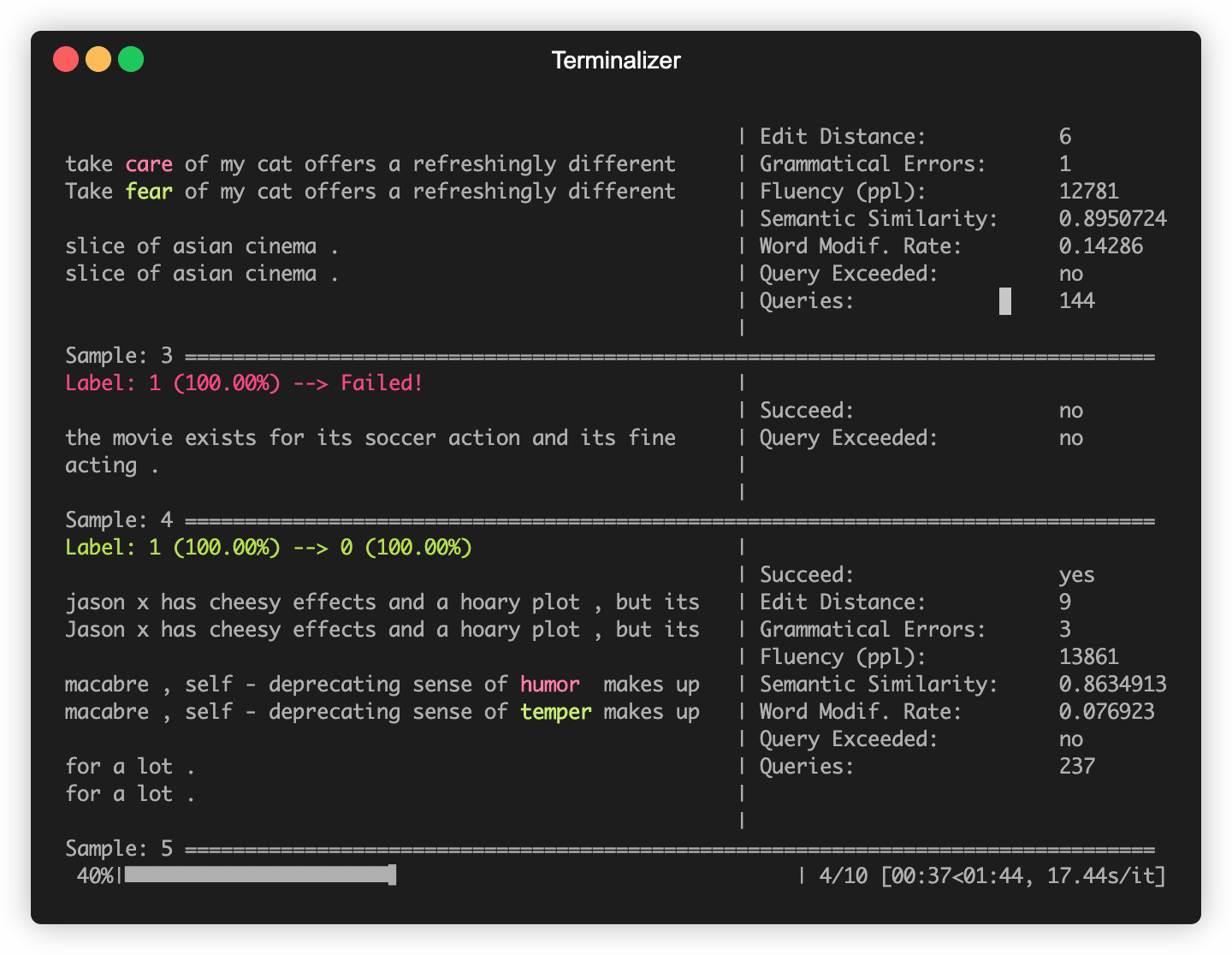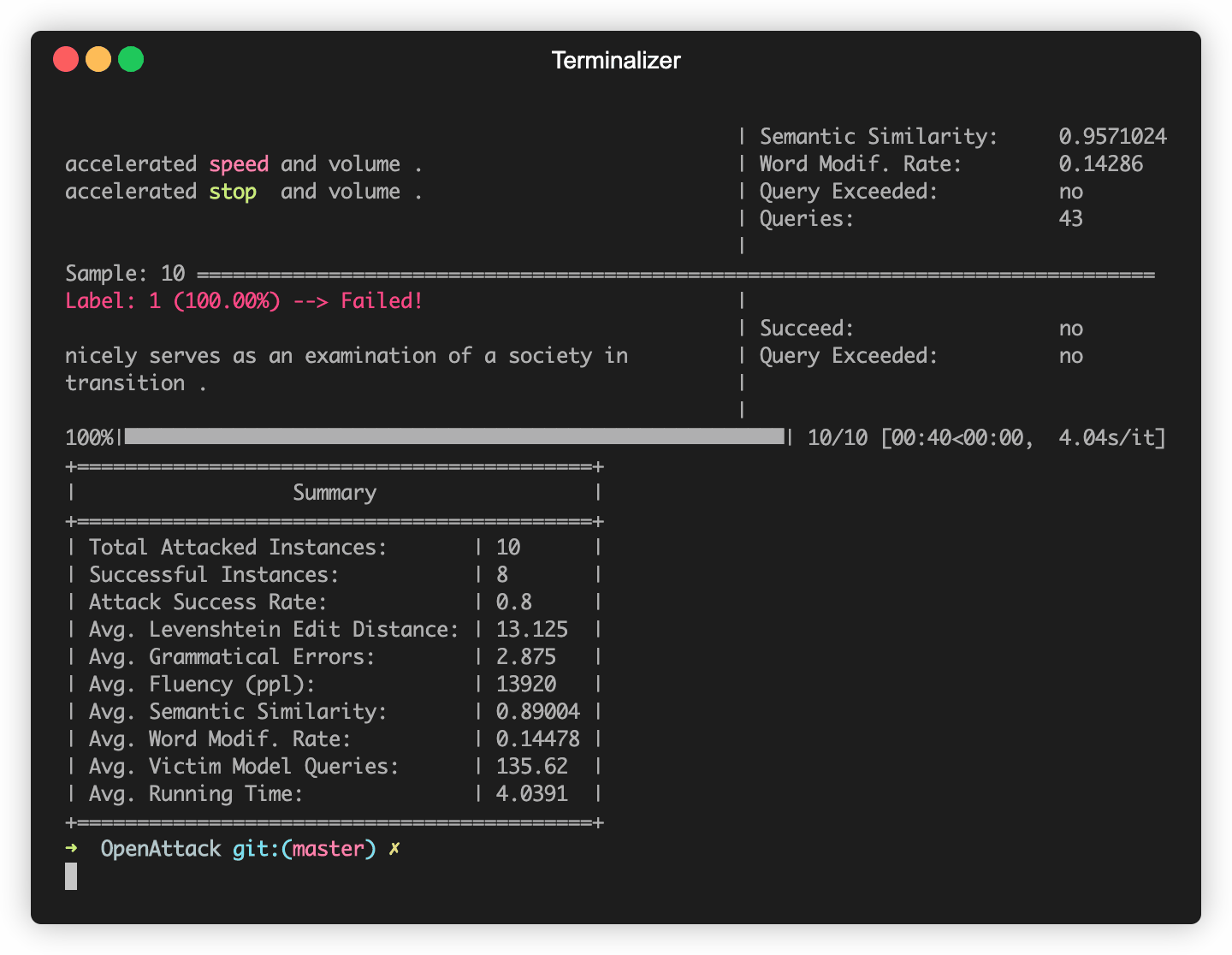
Openattack은 일반적으로 사용되는 일부 데이터 세트 (예 : SST-2)에서 미세 조정 된 Bert (Devlin et al. 2018) 및 Roberta (Liu et al. 2019)와 같은 일부 NLP 모델을 구축합니다. 이러한 내장 피해자 모델에 대한 적대적인 공격을 쉽게 수행 할 수 있습니다.
다음 코드 스 니펫은 탐욕스러운 알고리즘 기반 공격 모델 (Ren et al., 2019) 인 PWW를 사용하여 SST-2 데이터 세트에서 BERT를 공격하는 방법을 보여줍니다 (전체 실행 코드는 여기에 있습니다).
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )다음 코드 스 니펫은 PWWS를 사용하여 SST-2에서 사용자 정의 감정 분석 모델 (NLTK에 내장 된 통계 모델)을 공격하는 방법을 보여줍니다 (전체 실행 가능한 코드는 여기에 있습니다).
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )다음 코드 스 니펫은 PWW를 사용하여 사용자 정의 데이터 세트에서 기존 미세 조정 감정 분석 모델을 공격하는 방법을 보여줍니다 (전체 실행 코드는 여기에 있습니다).
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )Openattack은 편리한 다중 프로세싱을 지원하여 적대적 공격 과정을 가속화합니다. 다음 코드 스 니펫은 유전자 알고리즘 기반 공격 모델 인 유전자 (Alzantot et al. 2018)와의 대적 공격에서 멀티 프로세싱을 사용하는 방법을 보여줍니다 (전체 실행 코드는 여기에 있습니다).
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )Openattack은 이제 영어 및 중국 피해자 모델에 대한 대적 공격을 지원합니다. 다음은 PWWS를 사용하여 중국 검토 분류 모델에 대한 적대적 공격을 수행하는 예제입니다.
Openattack에는 새로운 공격 모델로 쉽게 조립할 수있는 많은 편리한 구성 요소가 통합되어 있습니다. 여기에서는 원래 문장에서 토큰을 섞는 간단한 공격 모델을 설계하는 방법의 예를 제시합니다.
OpenAttack은 교육 세트의 인스턴스를 공격하여 적대적인 예제를 쉽게 생성 할 수 있으며, 이는 원래 교육 데이터 세트에 추가하여보다 강력한 희생자 모델, 즉 적대적인 훈련을 재교육 할 수 있습니다. 다음은 Openattack을 사용하여 대적 훈련을 수행하는 방법의 예를 제시합니다.
공격 문장 쌍 분류 모델. 단일 문장 분류 모델 외에도 Openattack은 문장 쌍 분류 모델에 대한 공격을 지원합니다. 다음은 Openattack을 사용한 NLI 모델에 대한 대적 공격을 수행하는 예제입니다.
맞춤형 평가 메트릭. Openattack은 맞춤형 적대 공격 평가 메트릭 설계를 지원합니다. 여기에는 맞춤형 평가 메트릭을 추가하고 적대 공격을 평가하는 데 사용하는 방법에 대한 예가 제공됩니다.
원래 입력에 부과 된 섭동 수준에 따르면, 텍스트 적대적 공격 모델은 문장 수준, 단어 수준, 문자 수준의 공격 모델로 분류 될 수 있습니다.
피해자 모델에 대한 접근성에 따르면, 텍스트 적대적 공격 모델은 gradient 기반, score 기반, decision 기반 및 blind 공격 모델로 분류 될 수 있습니다.
Taadpapers는 텍스트 적대적 공격 및 방어에 관한 거의 모든 논문을 요약하는 종이 목록입니다. 이 목록을 살펴보고 더 많은 공격 모델을 찾을 수 있습니다.
현재 Openattack에는 모든 공격 유형을 포괄하는 텍스트 분류 모델에 대한 15 가지 일반적인 공격 모델이 포함되어 있습니다.
다음은 현재 관련된 공격 모델 목록입니다.
decision [PDF] [코드]blind [PDF] [코드 및 데이터]decision [PDF] [코드]score [PDF] [코드]score [PDF] [코드]score [PDF] [코드]score [PDF] [코드]score [PDF] [코드]score [PDF] [코드]gradient [PDF]gradient score [PDF]gradient [PDF] [코드] [웹 사이트]gradient [PDF] [코드]score [PDF] [코드 및 데이터]score [PDF] [코드]다음 표는 공격 모델의 비교를 보여줍니다.
| 모델 | 접근성 | 섭동 | 주요 아이디어 |
|---|---|---|---|
| 바다 | 결정 | 문장 | 규칙 기반의 역설 |
| scpn | 눈이 먼 | 문장 | 역설 |
| 간 | 결정 | 문장 | 인코더 디코더에 의한 텍스트 생성 |
| TextFooler | 점수 | 단어 | 욕심 많은 단어 대체 |
| PWWS | 점수 | 단어 | 욕심 많은 단어 대체 |
| 유전자 | 점수 | 단어 | 유전자 알고리즘 기반 단어 대체 |
| Sememepso | 점수 | 단어 | 입자 떼 최적화 기반 단어 대체 |
| 버트-공격 | 점수 | 단어 | 탐욕스러운 맥락화 된 단어 대체 |
| 배 | 점수 | 단어 | 탐욕스러운 맥락화 된 단어 대체 및 삽입 |
| FD | 구배 | 단어 | 그라디언트 기반 단어 대체 |
| TextBugger | 그라디언트, 점수 | Word+char | 탐욕스러운 단어 대체 및 캐릭터 조작 |
| uat | 구배 | 단어, 숯 | 그라디언트 기반 단어 또는 문자 조작 |
| Hotflip | 구배 | 단어, 숯 | 그라디언트 기반 단어 또는 문자 대체 |
| 독사 같은 사람 | 눈이 먼 | 숯 | 시각적으로 유사한 문자 대체 |
| Deepwordbug | 점수 | 숯 | 탐욕스러운 캐릭터 조작 |
다양한 공격 모델 간의 중요한 차이점을 고려할 때, 우리는 공격 모델의 골격 설계에 상당한 자유를 남기고, 적대적 공격의 일반적인 처리 및 공격 모델에 사용되는 일반적인 구성 요소를 간소화하는 데 더 집중합니다.
Openattack에는 7 개의 주요 모듈이 있습니다.
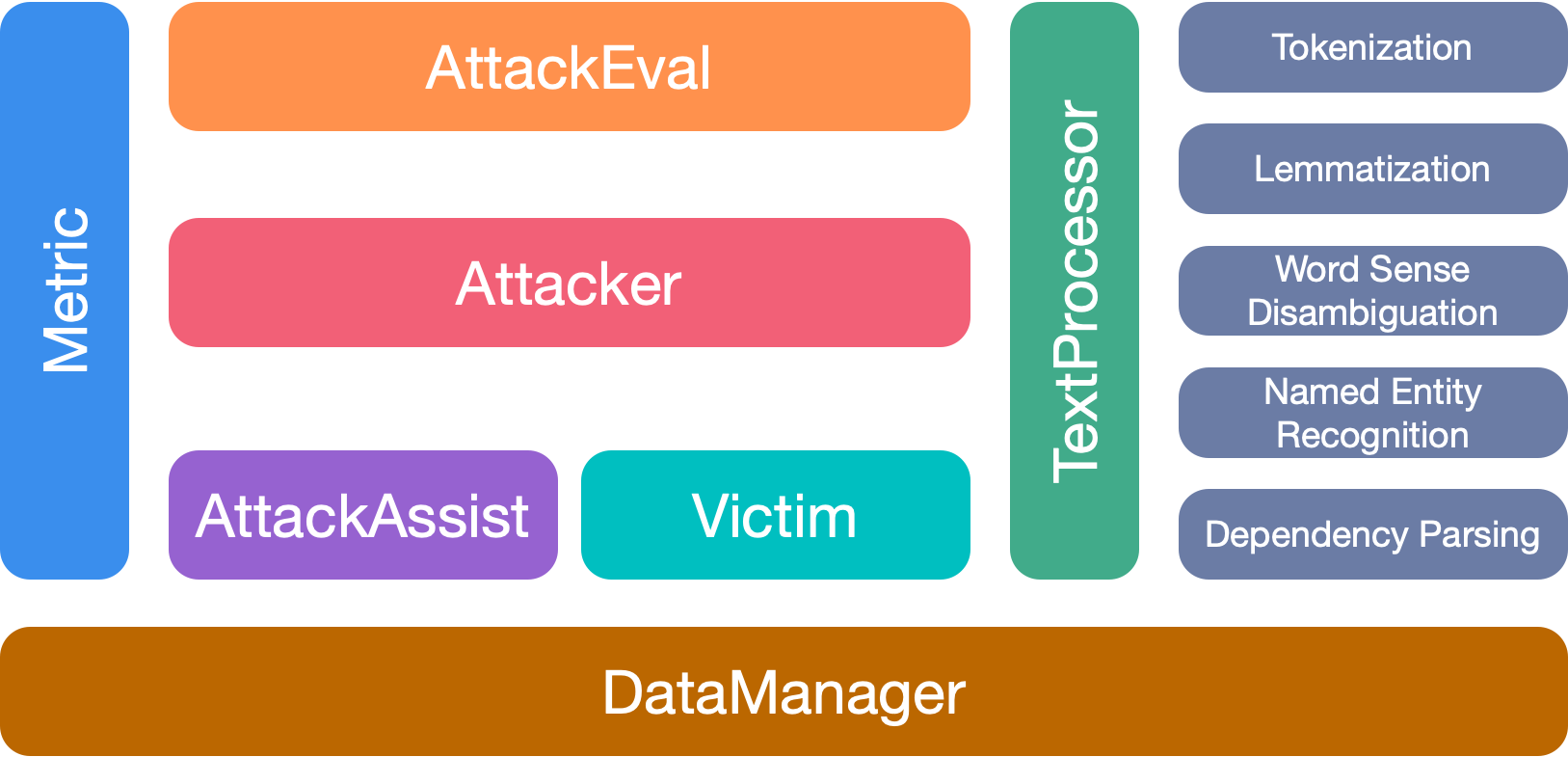
이 툴킷을 사용하면 다음과 같은 경우 논문을 인용하십시오.
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
우리는이 프로젝트에 대한 모든 기여자들에게 감사합니다. 그리고 더 많은 기여는 매우 환영합니다.


