OpenAttack
version for datasets

文档•功能和用途•用法示例•攻击模型•工具包设计
OpenAttack是一个基于开源Python的文本对抗攻击工具包,它处理了整个文本对抗攻击的过程,包括预处理文本,访问受害者模型,生成对抗性示例和评估。
配进所有攻击类型的支持。 OpenATTACK支持所有类型的攻击,包括句子/word-/cartar-level扰动和梯度 - /得分/基于决策/盲攻击模型;
多语言。 OpenAttack现在支持英语和中文。它的可扩展设计可快速支持更多语言。
并行处理。 OpenAttack为攻击模型的多进程运行提供了支持,以提高攻击效率;
配立?拥抱脸。 OpenAttack完全集成了?变压器和数据集库;
️巨大的可扩展性。您可以在任何自定义数据集上轻松攻击定制的受害者模型,或开发和评估定制的攻击模型。
✅为攻击模型提供各种方便的基线;
✅使用其彻底评估指标全面评估攻击模型;
✅在其共同攻击组件的帮助下,协助快速开发新的攻击模型;
✅评估机器学习模型对各种对抗性攻击的鲁棒性;
✅通过用产生的对抗性示例丰富训练数据,进行对抗训练以提高机器学习模型的鲁棒性。
pip (推荐) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install安装后,您可以尝试运行demo.py以检查OpenAttack是否效果很好:
python demo.py
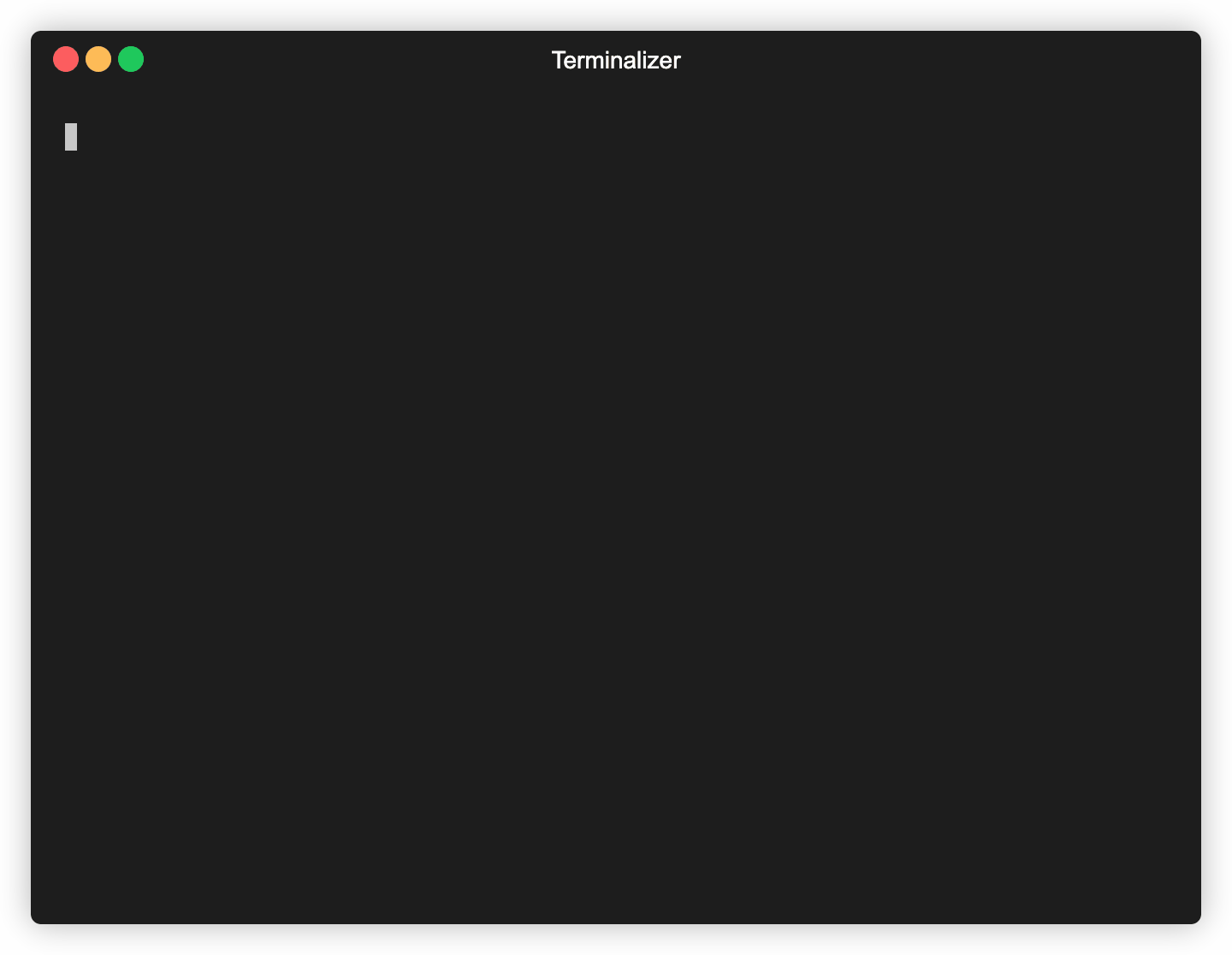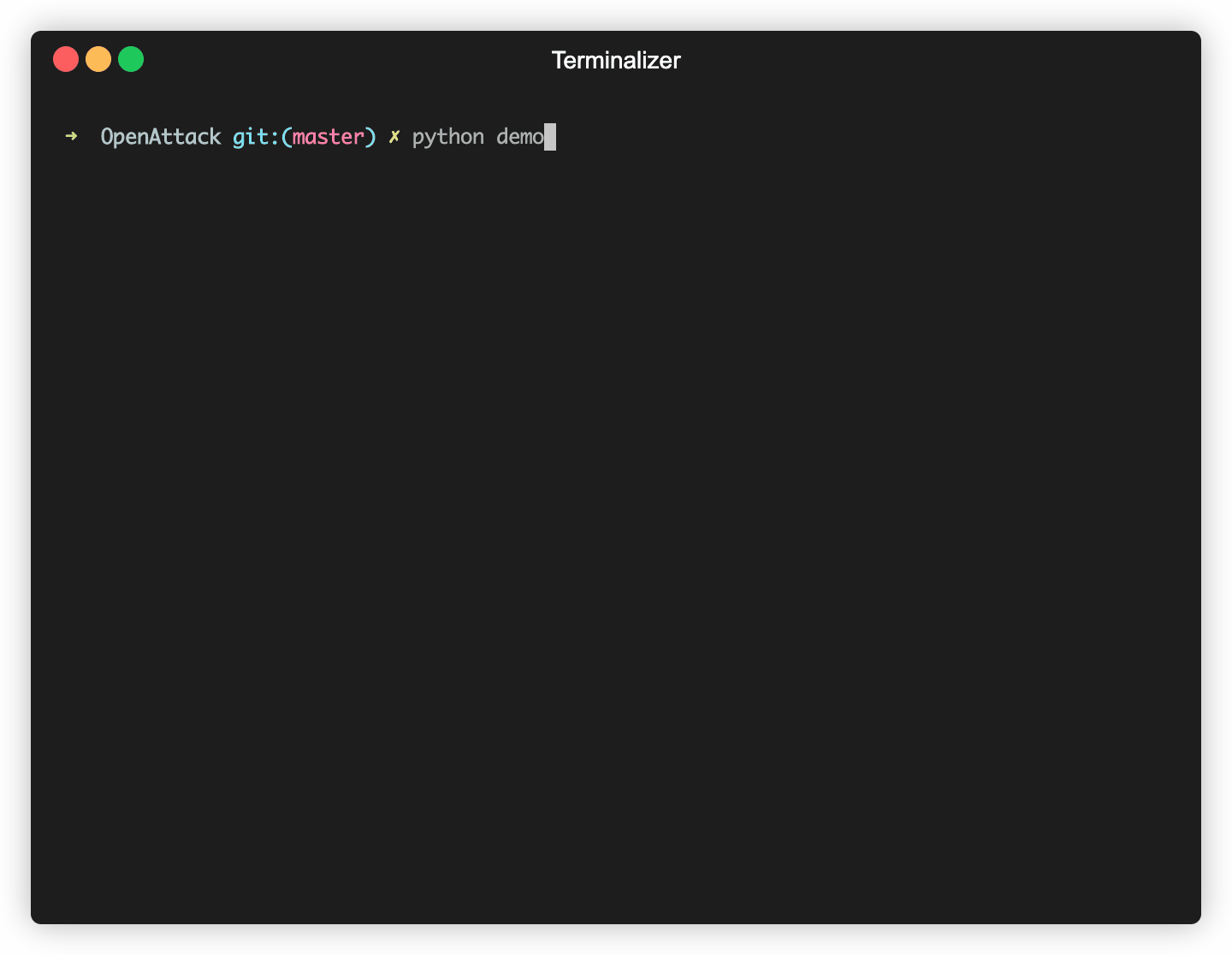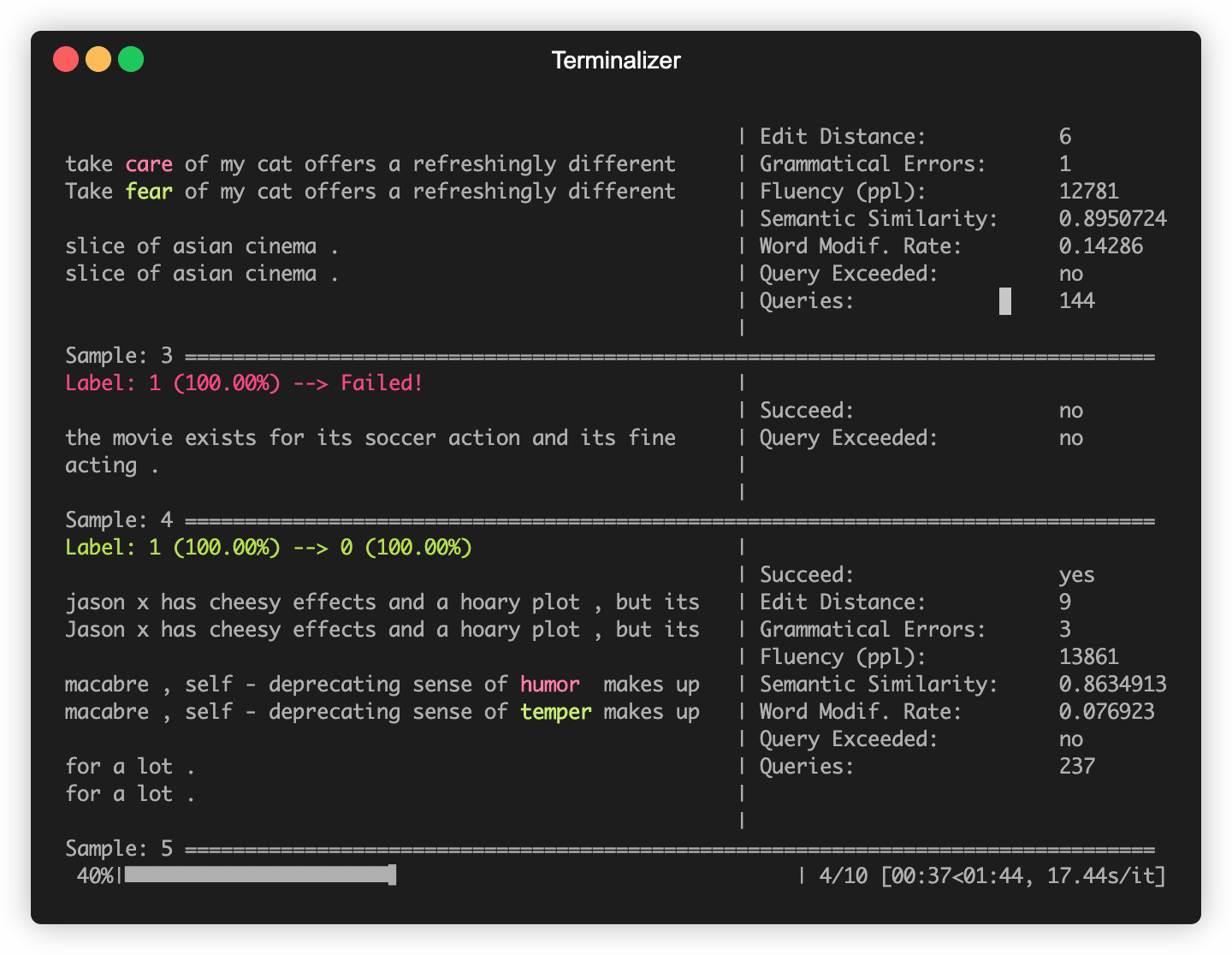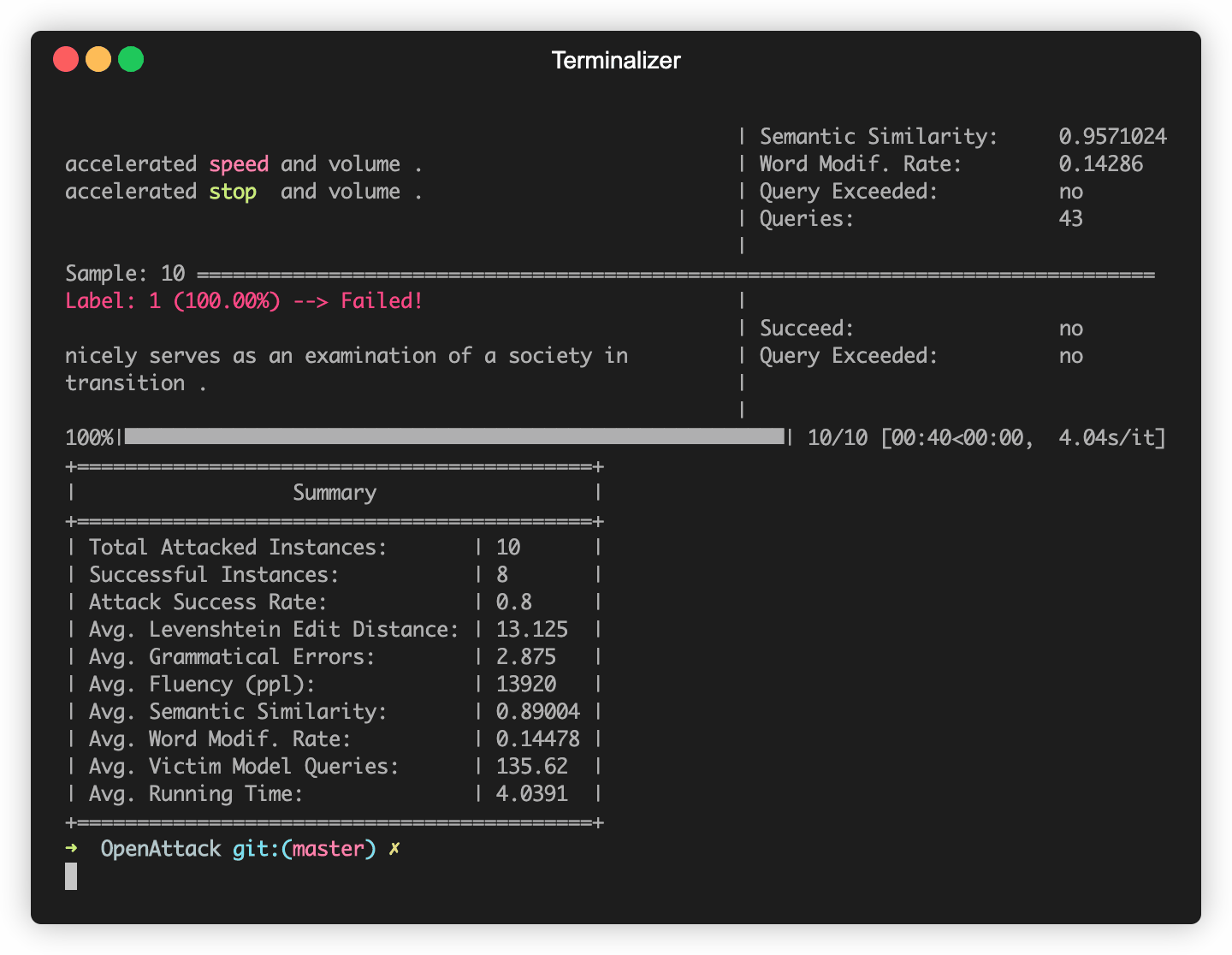
OpenAttack在一些常用的NLP模型中构建,例如Bert(Devlin等人,2018年)和Roberta(Liu等人,2019年),它们在一些常用的数据集(例如SST-2)上进行了微调。您可以轻松地针对这些内置受害者模型进行对抗性攻击。
以下代码片段显示了如何使用PWWS,这是一种基于贪婪算法的攻击模型(Ren等,2019),以攻击SST-2数据集中的BERT(完整的可执行代码在此处)。
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )以下代码片段显示了如何使用PWW在SST-2上攻击自定义的情感分析模型(NLTK内置的统计模型)(完整的可执行代码在此处)。
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )以下代码段显示了如何使用PWW在自定义数据集上攻击现有的微调情感分析模型(完整的可执行代码在此处)。
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )OpenAttack支持方便的多处理,以加速对抗攻击的过程。以下代码段显示了如何在具有遗传的对抗攻击中使用多处理(Alzantot等人,2018),这是一种基于遗传算法的攻击模型(完整的可执行代码在这里)。
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )OpenAttack现在支持对英国和中国受害者模型的对抗性攻击。这是使用PWWS对中国评论分类模型进行对抗性攻击的示例守则。
OpenAttack结合了许多方便的组件,这些组件可以轻松组装到新的攻击模型中。这里给出了一个示例,说明如何设计一个简单的攻击模型,该模型在原始句子中调整了令牌。
OpenATTACK可以通过攻击训练集中的实例轻松地产生对抗性示例,该实例可以添加到原始培训数据集中,以重新训练更强大的受害者模型,即对对抗性培训。这里举例说明了如何使用OpenAttack进行对抗训练。
攻击句子对分类模型。除了单句分类模型外,OpenAttack还支持针对句子对分类模型的攻击。这是对使用OpenAttack进行NLI模型进行对抗性攻击的示例代码。
定制评估指标。 OpenAttack支持设计定制的对抗攻击评估度量。这里举了一个示例,说明如何添加自定义评估度量标准并使用它来评估对抗性攻击。
根据对原始输入施加的扰动水平,文本对抗攻击模型可以归类为句子级别,单词级,字符级攻击模型。
根据对受害者模型的可访问性,文本对抗攻击模型可以分为基于gradient的,基于score ,基于decision和blind攻击模型。
Taadpapers是一个纸质清单,总结了几乎所有有关文本对抗攻击和防御的论文。您可以查看此列表以查找更多攻击模型。
当前,OpenAttack包括15个针对涵盖所有攻击类型的文本分类模型的典型攻击模型。
这是当前涉及的攻击模型的列表。
decision [PDF] [代码]blind [PDF] [代码和数据]decision [PDF] [代码]score [PDF] [代码]score [PDF] [代码]score [PDF] [代码]score [PDF] [代码]score [PDF] [代码]score [PDF] [代码]gradient [PDF]gradient score [PDF]gradient [PDF] [代码] [网站]gradient [PDF] [代码]score [PDF] [代码和数据]score [PDF] [代码]下表说明了攻击模型的比较。
| 模型 | 可访问性 | 扰动 | 大意 |
|---|---|---|---|
| 海 | 决定 | 句子 | 基于规则的释义 |
| SCPN | 瞎的 | 句子 | 释义 |
| 甘 | 决定 | 句子 | 通过编码器编码器的文本生成 |
| TextFooler | 分数 | 单词 | 贪婪的词替代 |
| pwws | 分数 | 单词 | 贪婪的词替代 |
| 遗传 | 分数 | 单词 | 基于遗传算法的单词替代 |
| 半疾病 | 分数 | 单词 | 基于粒子群优化的单词替代 |
| 伯特攻击 | 分数 | 单词 | 贪婪的情境化词替代 |
| 贝 | 分数 | 单词 | 贪婪的上下文化词替代和插入 |
| fd | 坡度 | 单词 | 基于梯度的单词替代 |
| Textbugger | 渐变,得分 | word+char | 贪婪的单词替代和性格操纵 |
| UAT | 坡度 | 字,char | 基于梯度的单词或角色操纵 |
| 热弹 | 坡度 | 字,char | 基于梯度的单词或角色替代 |
| 毒蛇 | 瞎的 | char | 视觉上相似的角色替代 |
| DeepWordbug | 分数 | char | 贪婪的角色操纵 |
考虑到不同攻击模型之间的显着区别,我们为攻击模型的骨架设计留下了相当大的自由,并专注于简化对抗性攻击的一般处理以及攻击模型中使用的常见组件。
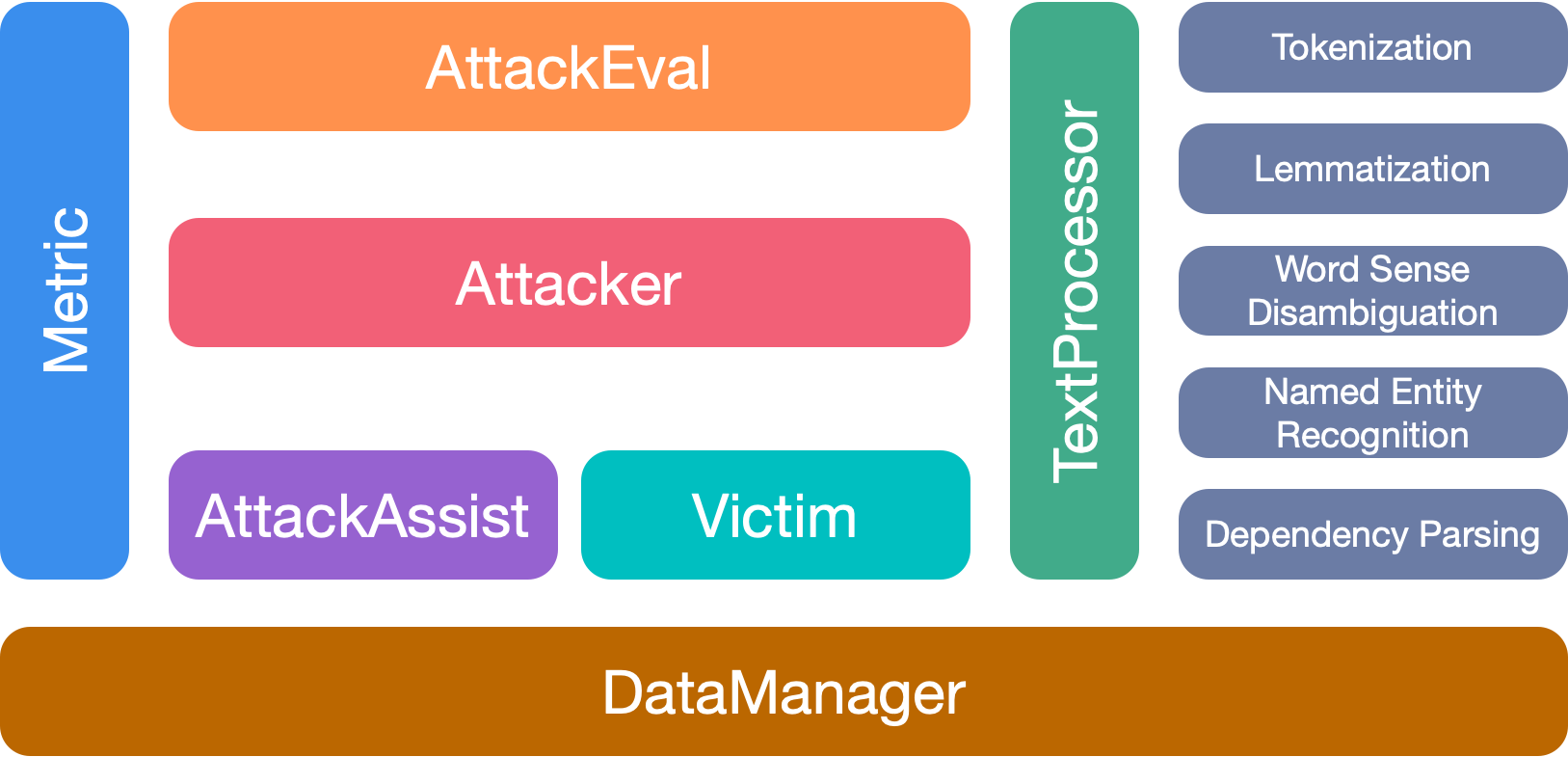
OpenAttack有7个主要模块:
如果您使用此工具包,请引用我们的论文:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
我们感谢该项目的所有贡献者。非常欢迎更多的贡献。


