OpenAttack
version for datasets

Documentation • Caractéristiques et utilisations • Exemples d'utilisation • Modèles d'attaque • Conception de la boîte à outils
OpenAttack est une boîte à outils d'attaque adversaire textuelle à base de python open source, qui gère l'ensemble du processus d'attaque adversaire textuelle, y compris le prétraitement du texte, l'accès au modèle de victime, générant des exemples adversaires et l'évaluation.
Çons Support pour tous les types d'attaque . OpenAttack prend en charge tous les types d'attaques, y compris les perturbations au niveau de la phrase / mot / des caractères et des modèles d'attaque de gradient / score / décision / aveugle;
️ multilinalité . Openattack soutient l'anglais et le chinois maintenant. Sa conception extensible permet une prise en charge rapide de plus de langues;
️ Traitement parallèle . OpenAttack prend en charge le fonctionnement multiproce des modèles d'attaque pour améliorer l'efficacité des attaques;
Çons compatibilité avec? Visage étreint . OpenAttack est entièrement intégré? Bibliothèques de transformateurs et de données;
️ Grande extensibilité . Vous pouvez facilement attaquer un modèle de victime personnalisé sur tout ensemble de données personnalisé ou développer et évaluer un modèle d'attaque personnalisé.
✅ Fournir diverses lignes de base pratiques pour les modèles d'attaque;
✅ évaluer de manière approfondie les modèles d'attaque en utilisant ses mesures d'évaluation approfondies;
✅ Aider au développement rapide de nouveaux modèles d'attaque à l'aide de ses composants d'attaque communs;
✅ Évaluer la robustesse d'un modèle d'apprentissage automatique contre diverses attaques contradictoires;
✅ Conclusion de formation contradictoire pour améliorer la robustesse d'un modèle d'apprentissage automatique en enrichissant les données de formation avec des exemples adversaires générés.
pip (recommandé) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install Après l'installation, vous pouvez essayer d'exécuter demo.py pour vérifier si OpenAttack fonctionne bien:
python demo.py
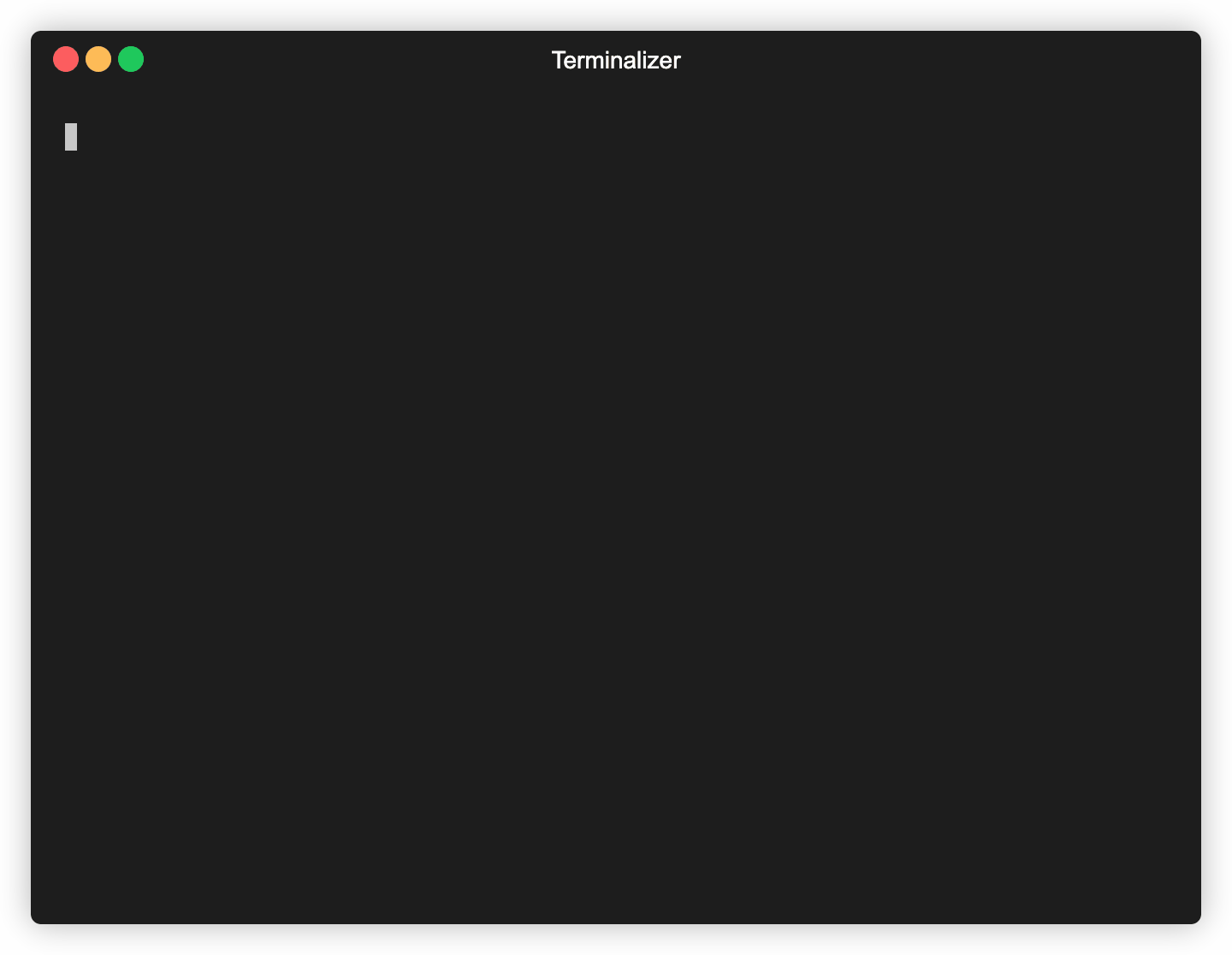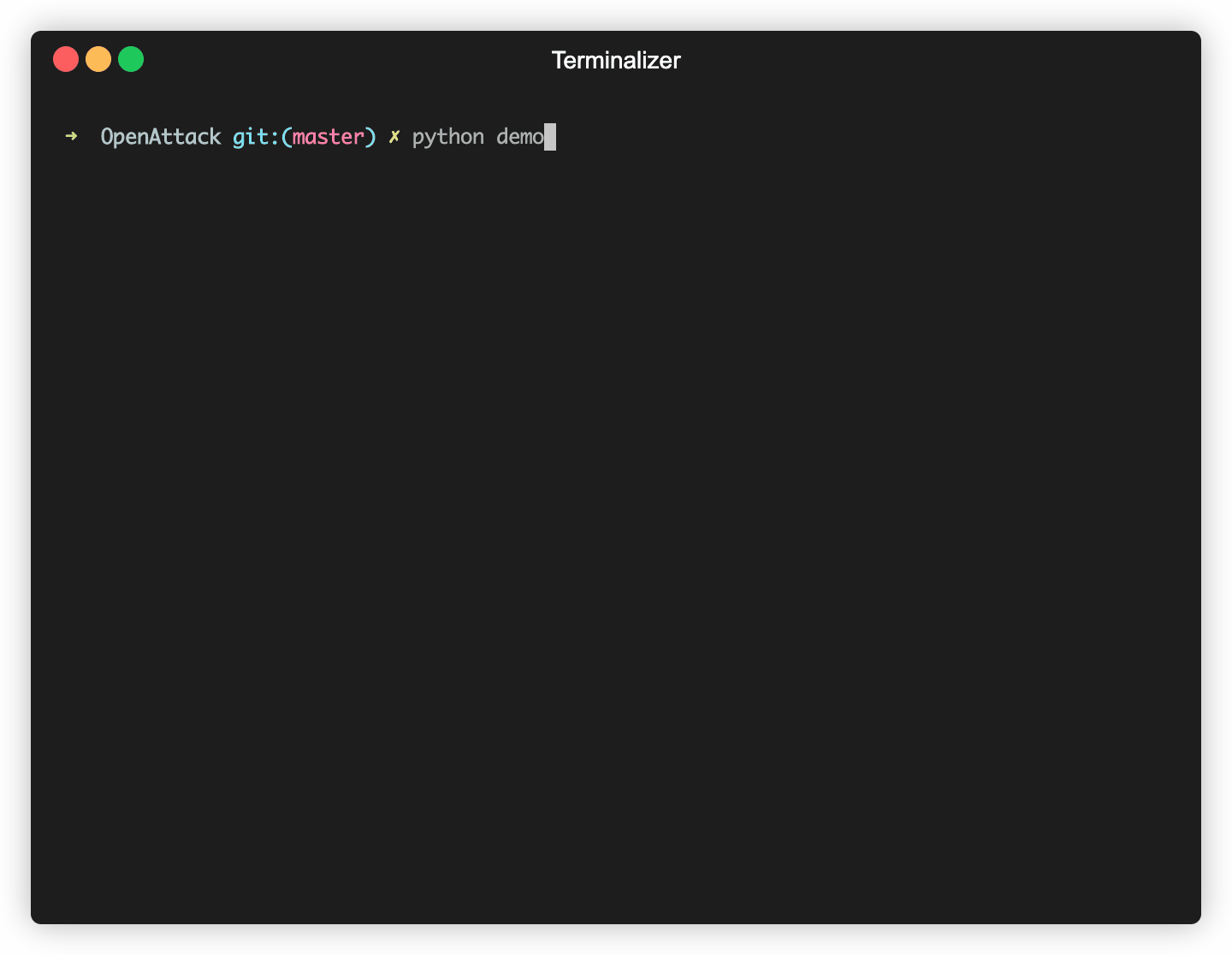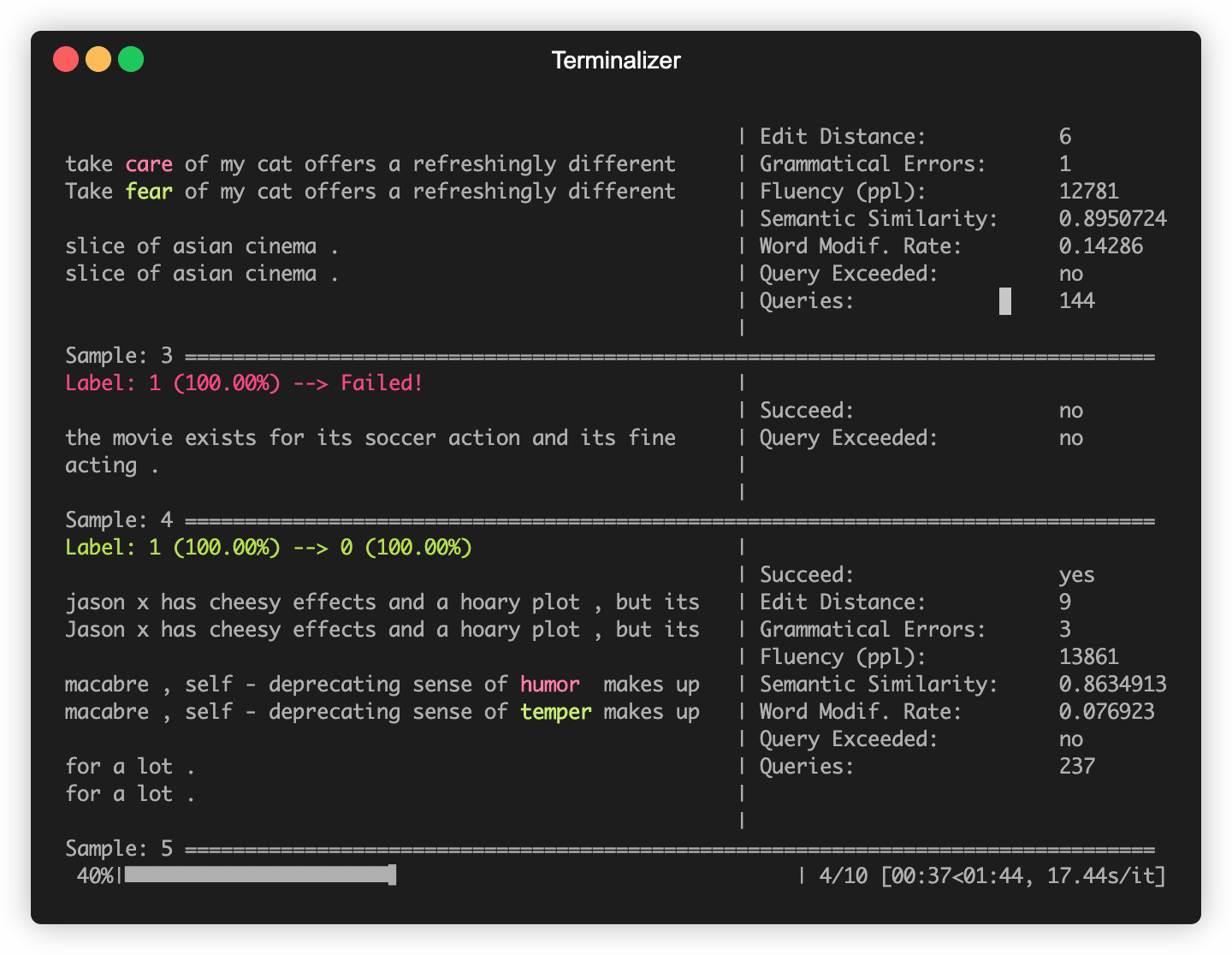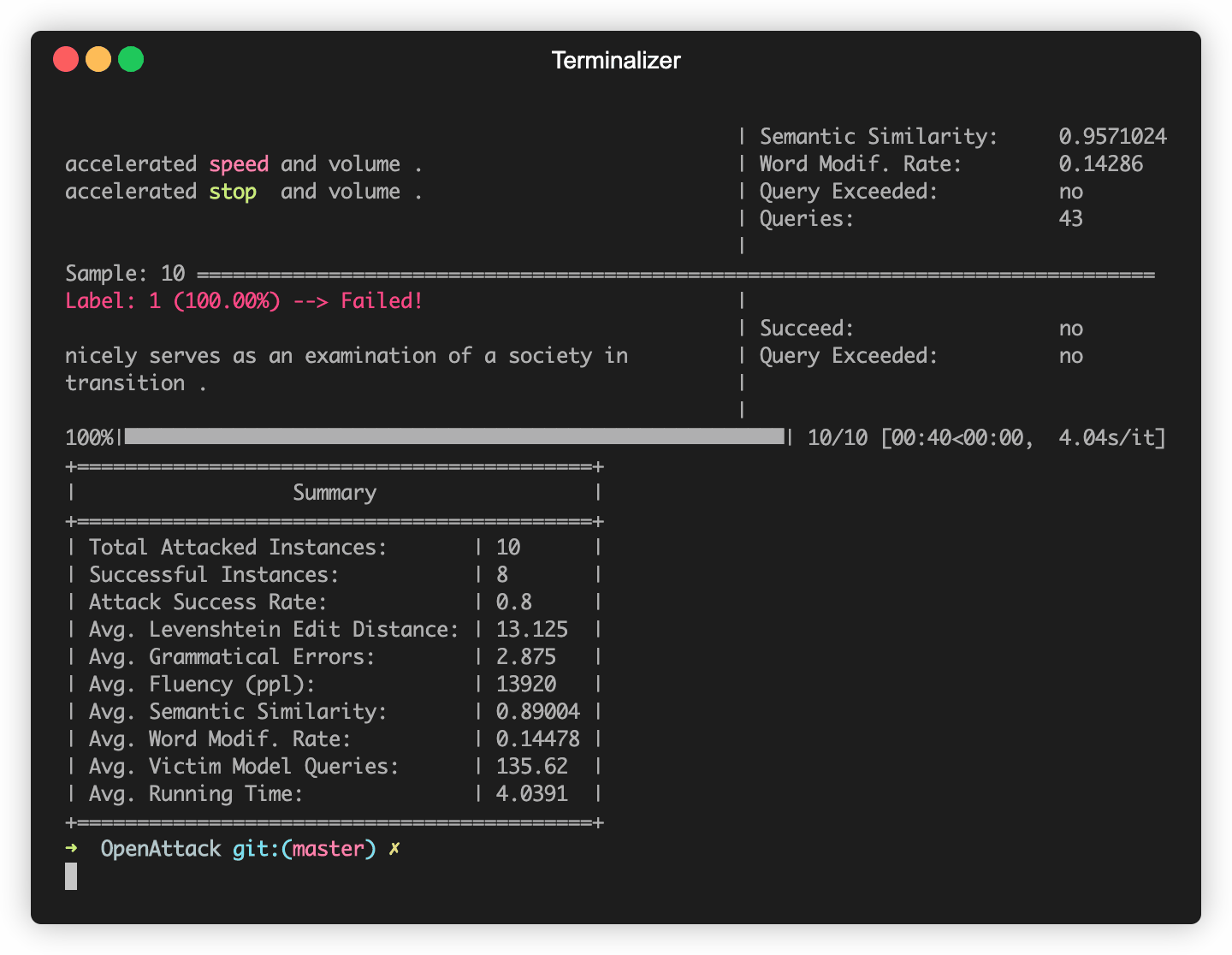
OpenAttack se construit dans certains modèles de PNL couramment utilisés comme Bert (Devlin et al. 2018) et Roberta (Liu et al. 2019) qui ont été affinés sur certains ensembles de données couramment utilisés (tels que SST-2). Vous pouvez mener sans effort des attaques contradictoires contre ces modèles de victime intégrés.
L'extrait de code suivant montre comment utiliser PWWS, un modèle d'attaque basé sur l'algorithme gourmand (Ren et al., 2019), pour attaquer Bert sur l'ensemble de données SST-2 (le code exécutable complet est ici).
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )L'extrait de code suivant montre comment utiliser les PWW pour attaquer un modèle d'analyse de sentiment personnalisé (un modèle statistique construit dans NLTK) sur SST-2 (le code exécutable complet est ici).
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )L'extrait de code suivant montre comment utiliser les PWW pour attaquer un modèle d'analyse de sentiment affinés existant sur un ensemble de données personnalisé (le code exécutable complet est ici).
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )OpenAttack prend en charge le multiprocessement pratique pour accélérer le processus d'attaques contradictoires. L'extrait de code suivant montre comment utiliser le multiprocessement dans les attaques adversaires avec génétique (Alzantot et al. 2018), un modèle d'attaque basé sur l'algorithme génétique (le code exécutable complet est ici).
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )Openattack soutient désormais les attaques contradictoires contre les modèles de victimes anglaises et chinoises. Voici un exemple de code de conduite d'attaques contradictoires contre un modèle de classification de la revue chinoise utilisant des PWW.
OpenAttack intègre de nombreux composants pratiques qui peuvent être facilement assemblés dans de nouveaux modèles d'attaque. Ici donne un exemple de la façon de concevoir un modèle d'attaque simple qui mélange les jetons dans la phrase d'origine.
OpenAttack peut facilement générer des exemples contradictoires en attaquant des cas dans l'ensemble de formation, qui peut être ajouté à l'ensemble de données de formation original pour recycler un modèle de victime plus robuste, c'est-à-dire une formation adversaire. Ici donne un exemple de la façon de mener une formation contradictoire avec OpenAttack.
Attaquez les modèles de classification des paires de phrases. En plus des modèles de classification des phrases uniques, OpenAttack Support les attaques contre les modèles de classification des paires de phrases. Voici un exemple de code de conduite d'attaques contradictoires contre un modèle NLI avec OpenAttack.
Métrique d'évaluation personnalisée. OpenAttack prend en charge la conception d'une métrique d'évaluation d'attaque adversaire personnalisée. Ici donne un exemple de la façon d'ajouter une métrique d'évaluation personnalisée et de l'utiliser pour évaluer les attaques contradictoires.
Selon le niveau de perturbations imposé à l'entrée d'origine, les modèles d'attaque adversaire textuel peuvent être classés en modèles d'attaque au niveau de la phrase, au niveau du mot et au niveau des caractères.
Selon l'accessibilité au modèle de victime, les modèles d'attaque contradictoire textuel peuvent être classés en modèles d'attaque basés sur gradient , basés sur score , basés sur decision et blind .
TaadPapers est une liste de papier qui résume presque tous les articles concernant l'attaque et la défense adversariale textuelle. Vous pouvez consulter cette liste pour trouver plus de modèles d'attaque.
Actuellement, OpenAttack comprend 15 modèles d'attaque typiques contre des modèles de classification de texte qui couvrent tous les types d'attaque.
Voici la liste des modèles d'attaque actuellement impliqués.
decision [PDF] [Code]blind [PDF] [Code et données]decision [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]score [PDF] [Code]gradient [PDF]score gradient [PDF]gradient [PDF] [Code] [Site Web]gradient [PDF] [Code]score [PDF] [Code et données]score [PDF] [Code]Le tableau suivant illustre la comparaison des modèles d'attaque.
| Modèle | Accessibilité | Perturbation | Idée principale |
|---|---|---|---|
| MER | Décision | Phrase | Paraphrasage basé sur les règles |
| SCPN | Aveugle | Phrase | Paraphrasant |
| Gan | Décision | Phrase | Génération de texte par coder-décodeur |
| Textfooleur | Score | Mot | Substitution de mots gourmands |
| PWW | Score | Mot | Substitution de mots gourmands |
| Génétique | Score | Mot | Substitution de mots basés sur l'algorithme génétique |
| Sememepso | Score | Mot | Substitution de mots basée sur l'optimisation des essaims de particules |
| Attaque Bert | Score | Mot | Substitution de mots contextualisés gourmands |
| BÉBÉ | Score | Mot | Substitution et insertion des mots contextualisés gourmands |
| FD | Pente | Mot | Substitution de mots basée sur le gradient |
| Texto | Gradient, score | Mot + char | Substitution de mots gourmands et manipulation du caractère |
| Uat | Pente | Mot, char | Manipulation de mots ou de personnages basés sur le gradient |
| Hotflip | Pente | Mot, char | Substitution de mot ou de caractère basé sur le gradient |
| VIPÈRE | Aveugle | Carboniser | Substitution de caractère visuellement similaire |
| Deepwordbug | Score | Carboniser | Manipulation de caractère gourmand |
Compte tenu des distinctions importantes entre les différents modèles d'attaque, nous laissons une liberté considérable à la conception squelette des modèles d'attaque et nous nous concentrons davantage sur la rationalisation du traitement général de l'attaque adversaire et des composants communs utilisés dans les modèles d'attaque.
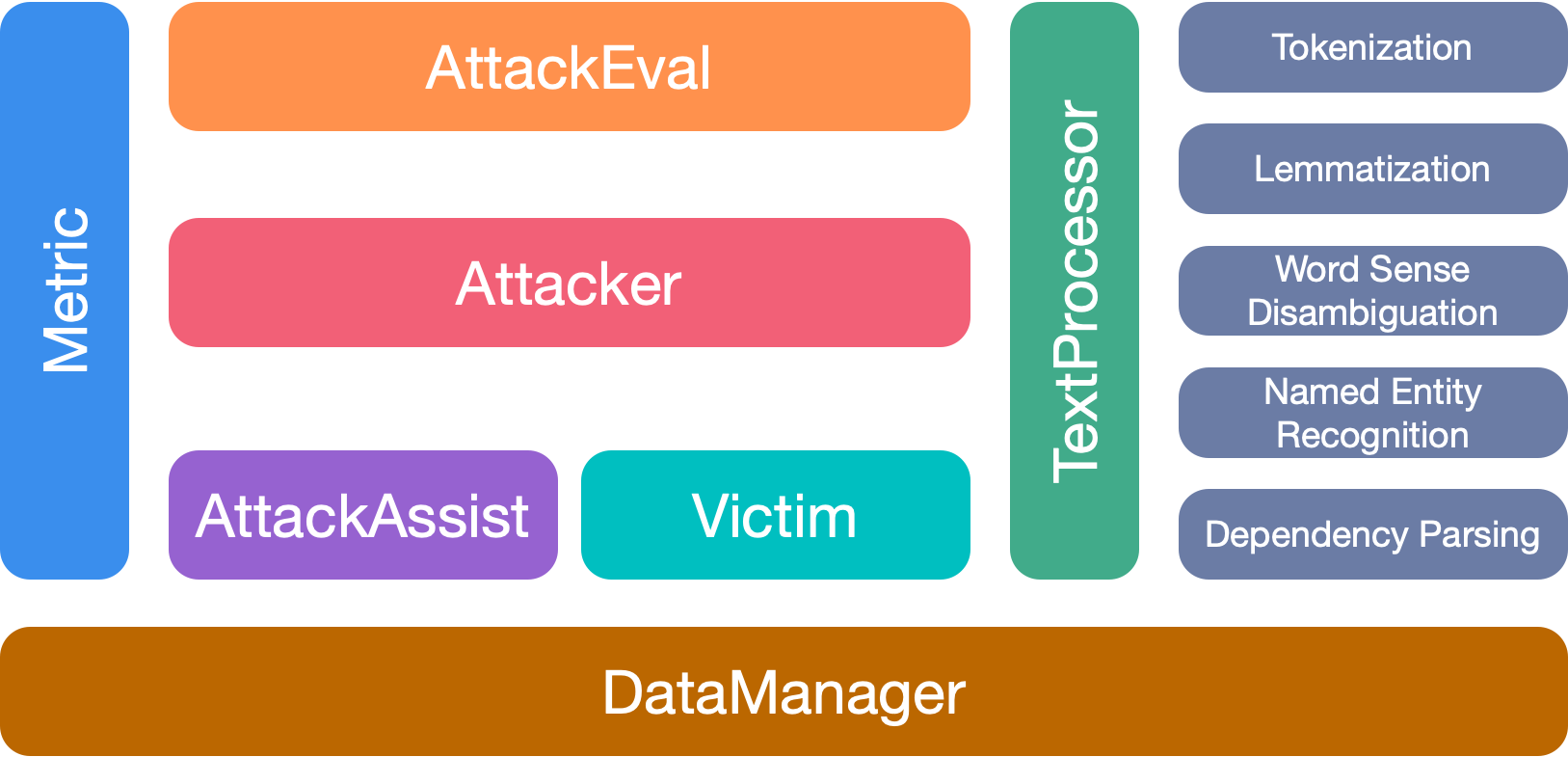
OpenAttack a 7 modules principaux:
Veuillez citer notre papier si vous utilisez cette boîte à outils:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
Nous remercions tous les contributeurs de ce projet. Et d'autres contributions sont les bienvenues.


