OpenAttack
version for datasets

Документация • Особенности и использование • Примеры использования • Модели атак • Дизайн инструментария
OpenAttack-это инструментарий текстовой атаки на основе Python с открытым исходным питоном, который обрабатывает весь процесс текстового состязательного атаки, включая текст предварительной обработки, доступ к модели жертвы, генерируя состязательные примеры и оценку.
️ Поддержка всех типов атак . OpenAttack поддерживает все типы атак, включая предложение-/Word-//модели на уровне символов и модели градиента-/баллы/на основе решений/слепая атака;
️ многоязычность . OpenAttack поддерживает английский и китайский сейчас. Его расширяемый дизайн обеспечивает быструю поддержку для большего количества языков;
️ Параллельная обработка . OpenAttack обеспечивает поддержку для многопроцессного запуска моделей атаки для повышения эффективности атаки;
️ Совместимость с? Обнимающееся лицо . OpenAttack полностью интегрирована? Библиотеки трансформаторов и наборов данных;
️ Отличная расширяемость . Вы можете легко атаковать индивидуальную модель жертвы на любом настраиваемом наборе данных или разработать и оценить индивидуальную модель атаки.
✅ Предоставление различных удобных базовых показателей для моделей атаки;
✅ Полноспешенная оценка моделей атак с использованием его тщательных показателей оценки;
✅ Помощь в быстрой разработке новых моделей атаки с помощью его общих компонентов атаки;
✅ Оценка надежности модели машинного обучения против различных состязательных атак;
✅ Проведение тренировки состязания для повышения надежности модели машинного обучения путем обогащения данных обучения сгенерированными примерами состязания.
pip (рекомендуется) pip install OpenAttackgit clone https://github.com/thunlp/OpenAttack.git
cd OpenAttack
python setup.py install После установки вы можете попробовать запустить demo.py , чтобы проверить, хорошо ли работает OpenAttack:
python demo.py
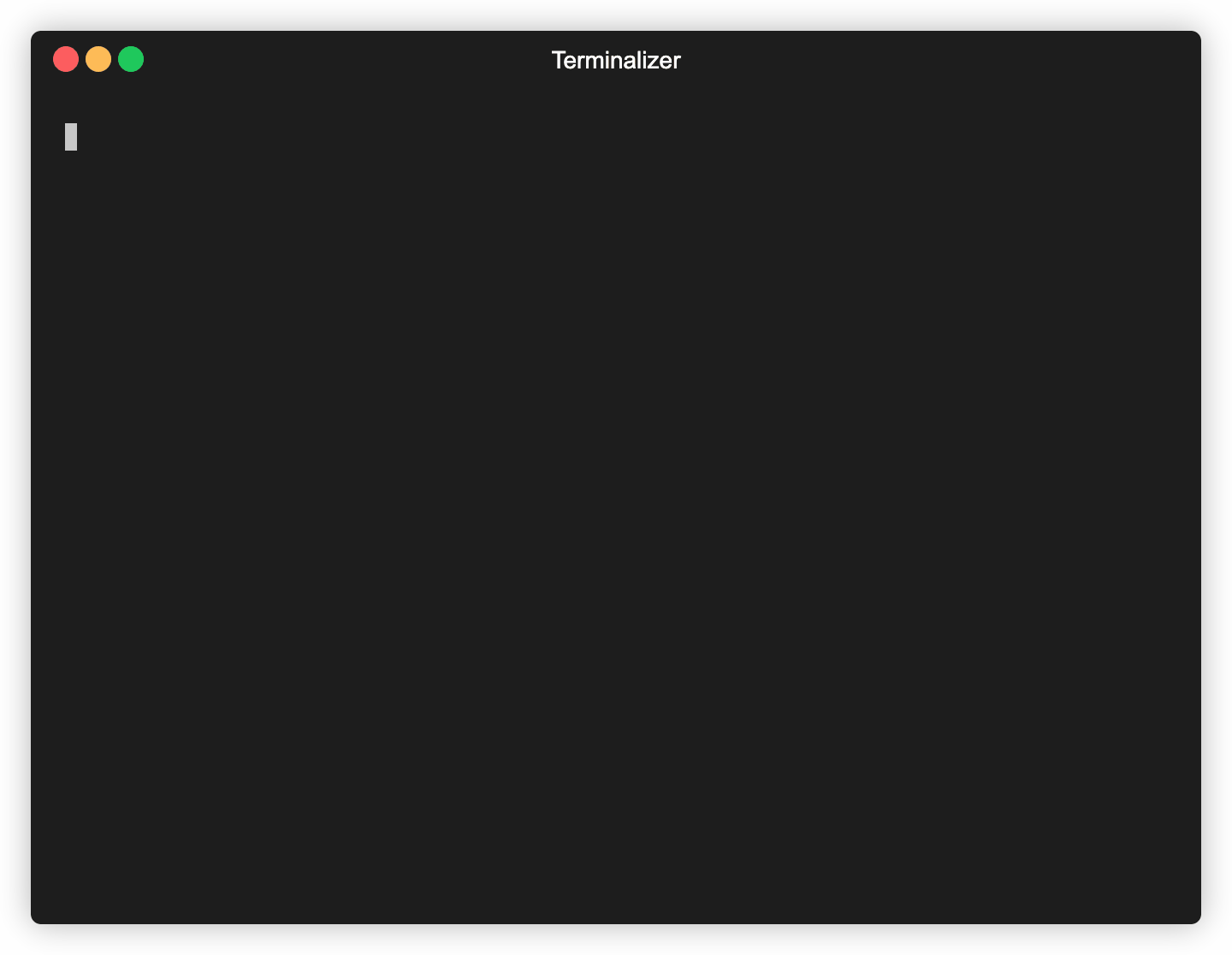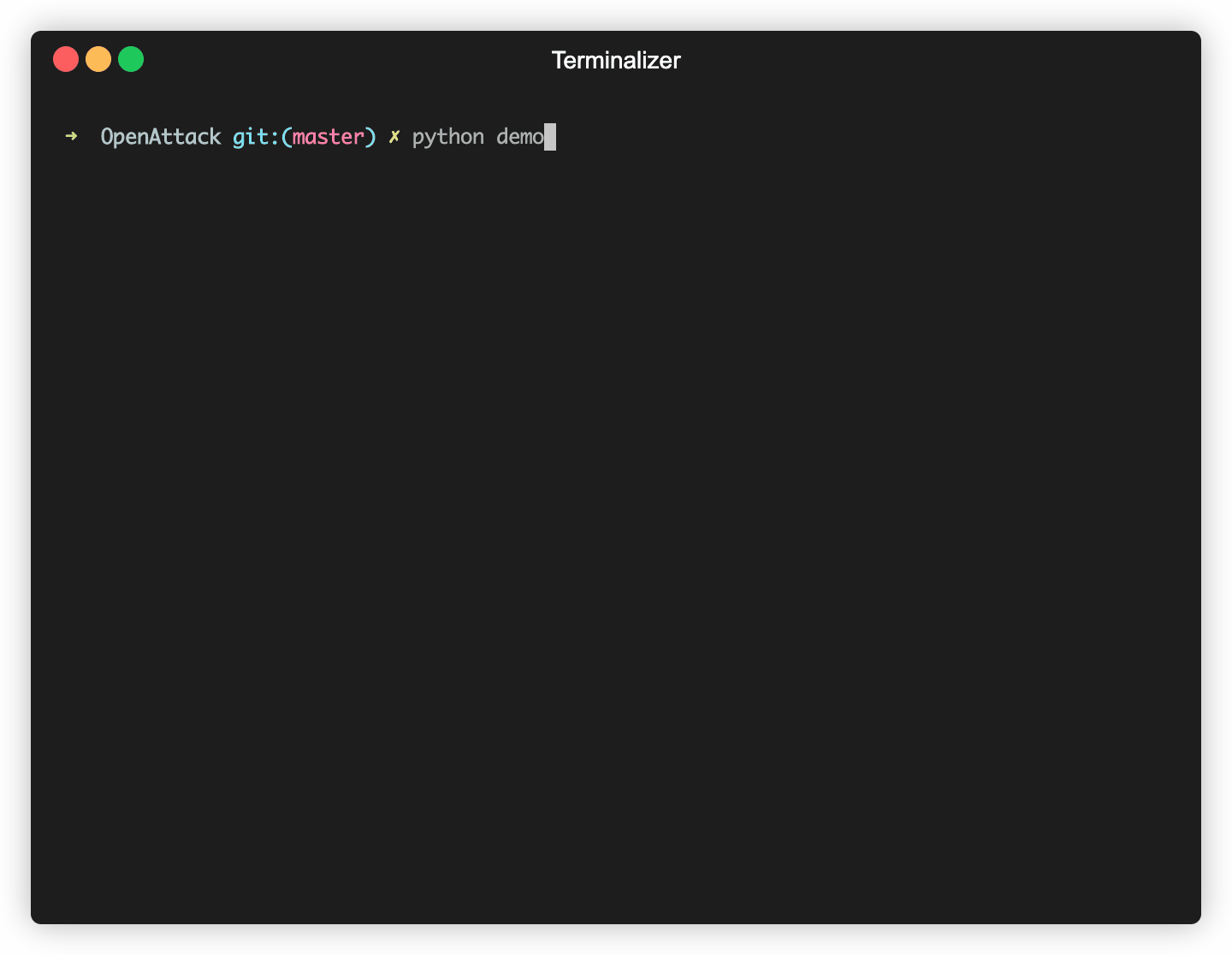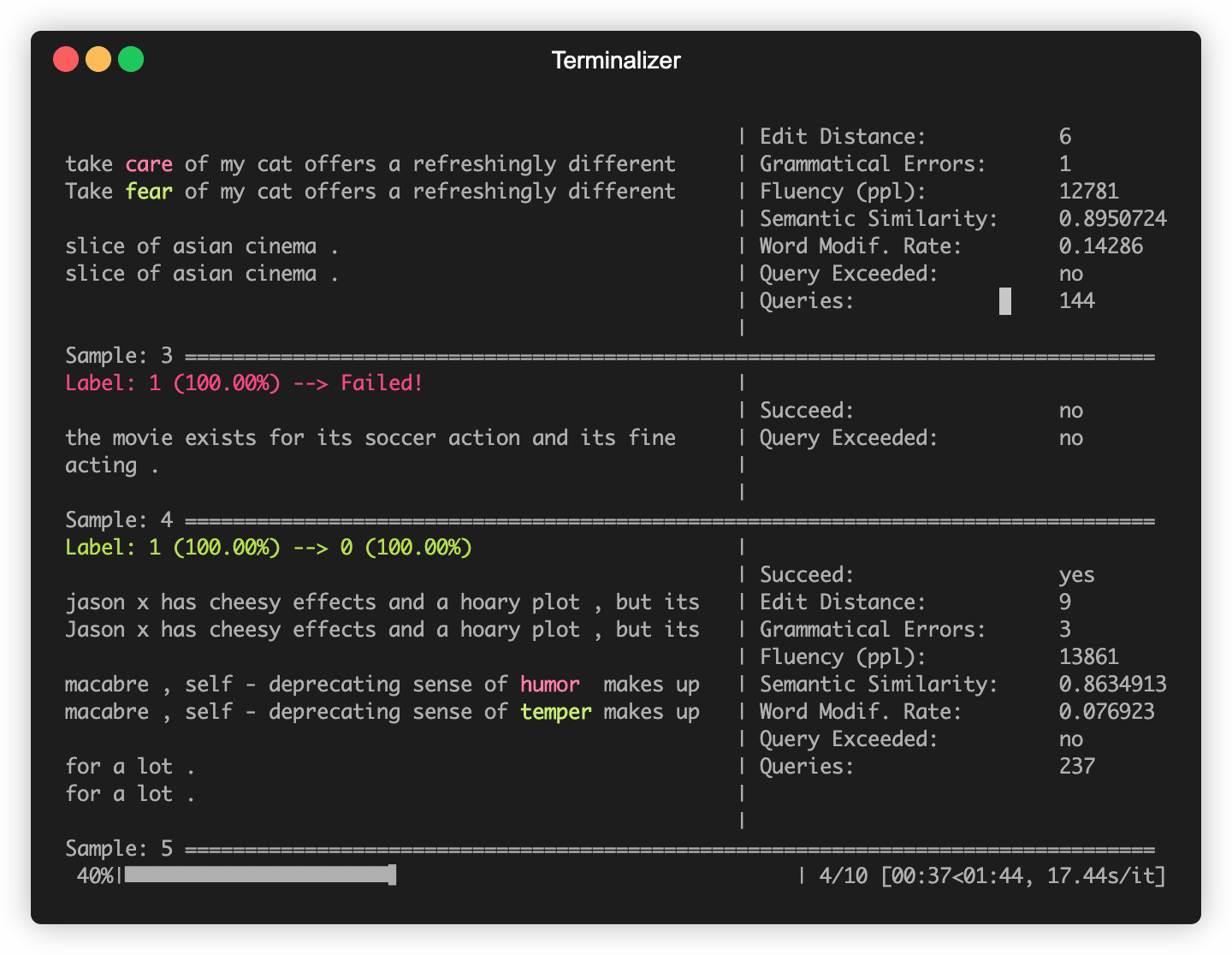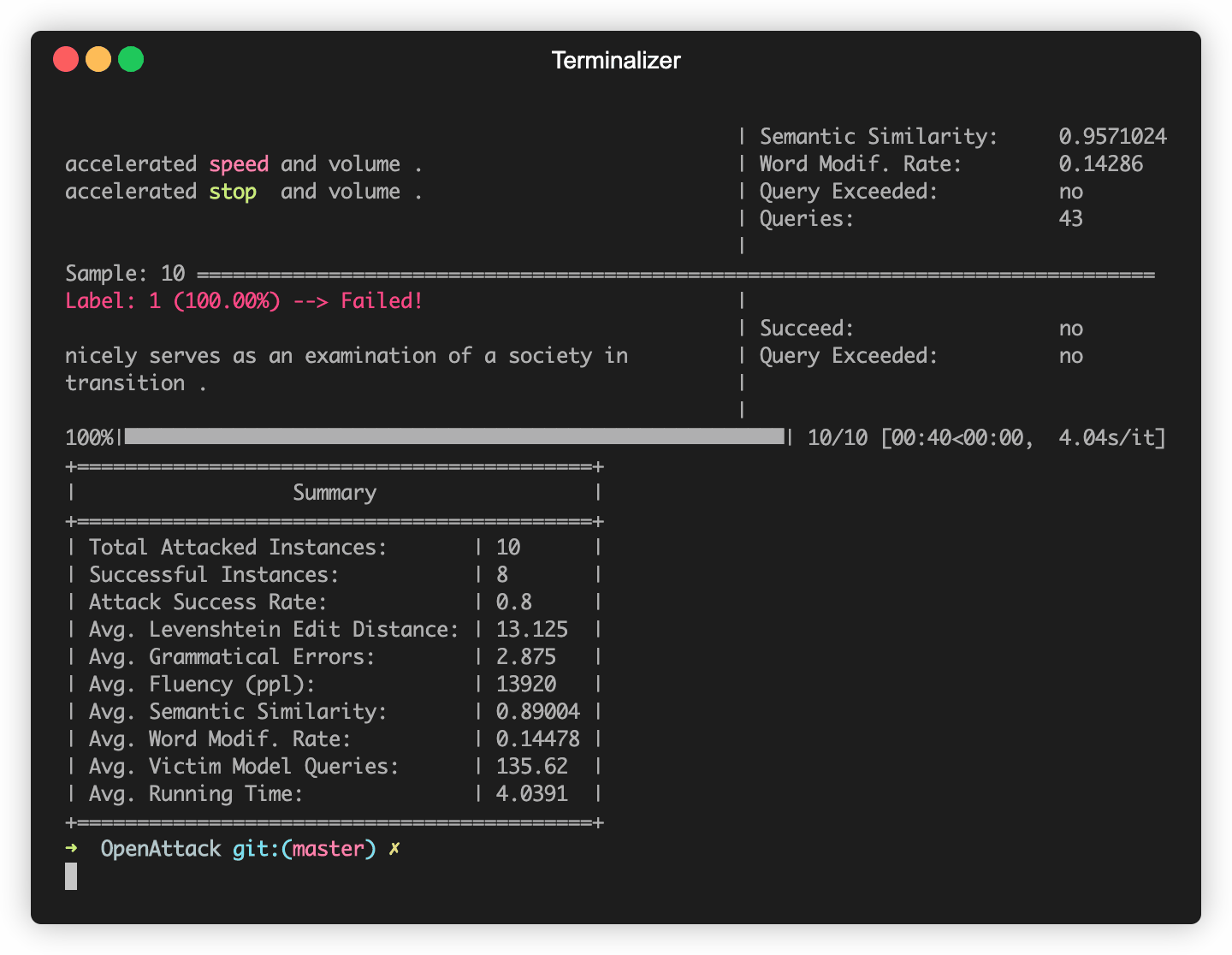
OpenAttack строит в некоторых часто используемых моделях NLP, таких как Bert (Devlin et al. 2018) и Roberta (Liu et al. 2019), которые были точно настроены на некоторых часто используемых наборах данных (таких как SST-2). Вы можете без усилий проводить состязательные атаки на эти встроенные модели жертв.
Следующий фрагмент кода показывает, как использовать PWWS, жадную модель атаки на основе алгоритма (Ren et al., 2019), для атаки BERT на набор данных SST-2 (полный исполняемый код здесь).
import OpenAttack as oa
import datasets # use the Hugging Face's datasets library
# change the SST dataset into 2-class
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# choose a trained victim classification model
victim = oa . DataManager . loadVictim ( "BERT.SST" )
# choose 20 examples from SST-2 as the evaluation data
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = OpenAttack . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )Следующий фрагмент кода показывает, как использовать PWWS для атаки модели настраиваемого анализа настроений (статистическая модель, встроенная в NLTK) на SST-2 (здесь есть полный исполняемый код).
import OpenAttack as oa
import numpy as np
import datasets
import nltk
from nltk . sentiment . vader import SentimentIntensityAnalyzer
# configure access interface of the customized victim model by extending OpenAttack.Classifier.
class MyClassifier ( oa . Classifier ):
def __init__ ( self ):
# nltk.sentiment.vader.SentimentIntensityAnalyzer is a traditional sentiment classification model.
nltk . download ( 'vader_lexicon' )
self . model = SentimentIntensityAnalyzer ()
def get_pred ( self , input_ ):
return self . get_prob ( input_ ). argmax ( axis = 1 )
# access to the classification probability scores with respect input sentences
def get_prob ( self , input_ ):
ret = []
for sent in input_ :
# SentimentIntensityAnalyzer calculates scores of “neg” and “pos” for each instance
res = self . model . polarity_scores ( sent )
# we use ?????_??? / (?????_??? + ?????_???) to represent the probability of positive sentiment
# Adding 10^−6 is a trick to avoid dividing by zero.
prob = ( res [ "pos" ] + 1e-6 ) / ( res [ "neg" ] + res [ "pos" ] + 2e-6 )
ret . append ( np . array ([ 1 - prob , prob ]))
# The get_prob method finally returns a np.ndarray of shape (len(input_), 2). See Classifier for detail.
return np . array ( ret )
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
# load some examples of SST-2 for evaluation
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
# choose the costomized classifier as the victim model
victim = MyClassifier ()
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim )
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )Следующий фрагмент кода показывает, как использовать PWWS для атаки существующей тонкой модели анализа настроений на настраиваемом наборе данных (полный исполняемый код здесь).
import OpenAttack as oa
import transformers
import datasets
# load a fine-tuned sentiment analysis model from Transformers (you can also use our fine-tuned Victim.BERT.SST)
tokenizer = transformers . AutoTokenizer . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" )
model = transformers . AutoModelForSequenceClassification . from_pretrained ( "echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid" , num_labels = 2 , output_hidden_states = False )
victim = oa . classifiers . TransformersClassifier ( model , tokenizer , model . bert . embeddings . word_embeddings )
# choose PWWS as the attacker and initialize it with default parameters
attacker = oa . attackers . PWWSAttacker ()
# create your customized dataset
dataset = datasets . Dataset . from_dict ({
"x" : [
"I hate this movie." ,
"I like this apple."
],
"y" : [
0 , # 0 for negative
1 , # 1 for positive
]
})
# prepare for attacking
attack_eval = oa . AttackEval ( attacker , victim , metrics = [ oa . metric . EditDistance (), oa . metric . ModificationRate ()])
# launch attacks and print attack results
attack_eval . eval ( dataset , visualize = True )OpenAttack поддерживает удобную многопроцессорную работу, чтобы ускорить процесс состязательных атак. Следующий фрагмент кода показывает, как использовать многопроцессорную передачу в состязательных атаках с генетическими (Alzantot et al. 2018), модели атаки на основе генетического алгоритма (полный исполняемый код здесь).
import OpenAttack as oa
import datasets
def dataset_mapping ( x ):
return {
"x" : x [ "sentence" ],
"y" : 1 if x [ "label" ] > 0.5 else 0 ,
}
victim = oa . loadVictim ( "BERT.SST" )
dataset = datasets . load_dataset ( "sst" , split = "train[:20]" ). map ( function = dataset_mapping )
attacker = oa . attackers . GeneticAttacker ()
attack_eval = oa . AttackEval ( attacker , victim )
# Using multiprocessing simply by specify num_workers
attack_eval . eval ( dataset , visualize = True , num_workers = 4 )OpenAttack теперь поддерживает состязательные атаки на модели английского и китайского жертвы. Вот пример кода проведения состязательных атак против китайской модели классификации обзоров с использованием PWWS.
OpenAttack включает в себя множество удобных компонентов, которые можно легко собрать в новые модели атак. Здесь приведен пример того, как разработать простую модель атаки, которая перетасовает токены в исходном предложении.
OpenAttack может легко генерировать состязательные примеры, атакуя экземпляры в учебном наборе, который можно добавить в оригинальный набор учебных данных для переподготовки более надежной модели жертв, т.е. Здесь приводит пример того, как провести состязательное обучение с OpenAttack.
Атака предложения Пары классификации. В дополнение к моделям классификации отдельных предложений атаки поддержки OpenAttack Attacks против моделей классификации пары предложений. Вот пример кода проведения состязательных атак против модели NLI с OpenAttack.
Индивидуальная оценка метрика. OpenAttack поддерживает проектирование индивидуальной метрики оценки атаки. Здесь приведен пример того, как добавить индивидуальный показатель оценки и использовать его для оценки состязательных атак.
В соответствии с уровнем возмущений, наложенных на исходный ввод, модели текстовых состязательных атак могут быть классифицированы на модели атаки на уровне слов, уровня, уровня символов.
В соответствии с доступностью к модели жертвы, модели текстовых состязательных атак могут быть классифицированы на модели на основе gradient , на основе score , на основе decision и blind атаки.
Taadpapers - это бумажный список, который суммирует почти все документы, касающиеся текстовой атаки состязания и защиты. Вы можете взглянуть на этот список, чтобы найти больше моделей атаки.
В настоящее время OpenAttack включает в себя 15 типичных моделей атаки против моделей классификации текста, которые охватывают все типы атак.
Вот список вовлеченных в настоящее время моделей атак.
decision [PDF] [Код]blind [PDF] [CODE & DATA]decision [PDF] [Код]score [PDF] [Код]score [PDF] [Код]score [PDF] [Код]score [PDF] [Код]score [PDF] [Код]score [PDF] [Код]gradient [PDF]gradient score [PDF]gradient [PDF] [CODE] [Веб-сайт]gradient [PDF] [Код]score [PDF] [CODE & DATA]score [PDF] [Код]Следующая таблица иллюстрирует сравнение моделей атаки.
| Модель | Доступность | Возмущение | Основная идея |
|---|---|---|---|
| МОРЕ | Решение | Предложение | Основанный на правилах перефразирование |
| SCPN | Слепой | Предложение | Перефразирование |
| Ган | Решение | Предложение | Генерация текста от Encoder-Decoder |
| Textfooler | Счет | Слово | Жадное слово замены |
| Pwws | Счет | Слово | Жадное слово замены |
| Генетический | Счет | Слово | Замена слов на основе генетического алгоритма |
| Sememepso | Счет | Слово | Замена слов на основе оптимизации на основе оптимизации частиц |
| Берт-Атака | Счет | Слово | Жадная контекстуализированная замена слова |
| Бей | Счет | Слово | Жадная контекстуализированная замена и вставка слова |
| Фт | Градиент | Слово | Градиент, основанная на замене слова |
| TextBugger | Градиент, счет | Слово+Чар | Жизное замена слова и манипуляция с персонажами |
| Uat | Градиент | Слово, Чар | Слово или манипуляция с градиентом или манипулирование персонажами |
| Привязки | Градиент | Слово, Чар | Слово или замену характера, основанное на градиенте |
| Гадюка | Слепой | Девчонка | Визуально сходная замена персонажа |
| DeepWordBug | Счет | Девчонка | Жадный манипуляция с персонажем |
Учитывая значительные различия между различными моделями атаки, мы оставляем значительную свободу для дизайна скелета моделей атаки и больше сосредоточимся на оптимизации общей обработки состязательного атаки и общих компонентов, используемых в моделях атаки.
OpenAttack имеет 7 основных модулей:
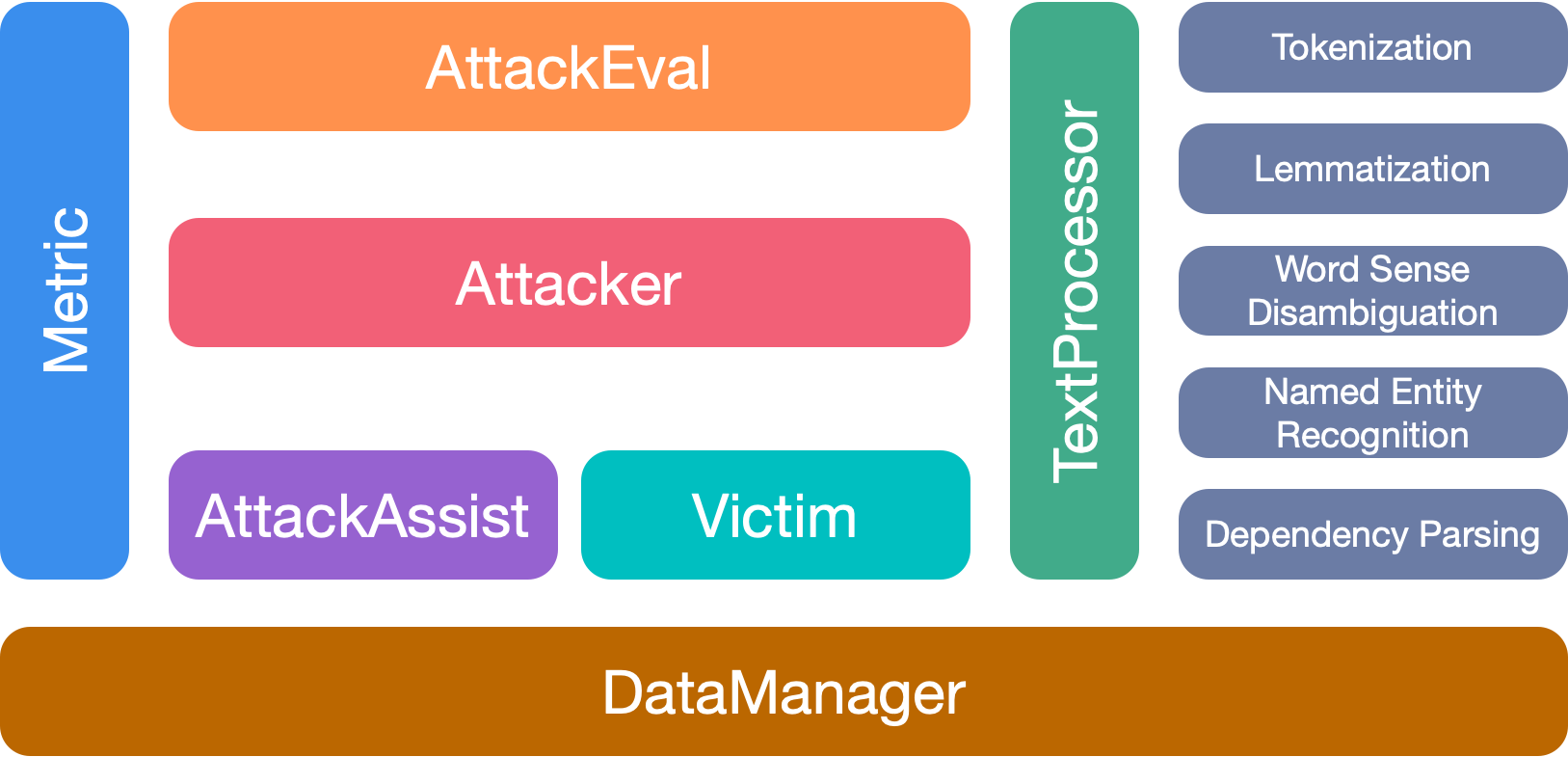
Пожалуйста, процитируйте нашу бумагу, если вы используете этот инструментарий:
@inproceedings{zeng2020openattack,
title={{Openattack: An open-source textual adversarial attack toolkit}},
author={Zeng, Guoyang and Qi, Fanchao and Zhou, Qianrui and Zhang, Tingji and Hou, Bairu and Zang, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations},
pages={363--371},
year={2021},
url={https://aclanthology.org/2021.acl-demo.43},
doi={10.18653/v1/2021.acl-demo.43}
}
Мы благодарим всех участников этого проекта. И больше вкладов очень приветствуются.


