similarity search kit
0.0.15

相似性SearchKit是一個Swift軟件包,僅在幾行中啟用了iOS和MACOS應用程序的iOS和MACOS應用程序的語義搜索功能。強調速度,可擴展性和隱私性,它支持各種內置的最先進的NLP模型和相似性指標,此外,除了無縫的集成以供您實現自己的選擇。
相似性搜索kit的一些潛在用例包括:
以隱私為重點的文檔搜索引擎:創建一個在本地處理敏感文檔的搜索引擎,而無需將用戶數據暴露於外部服務。 (請參閱示例目錄中的示例項目“ chatwithfilesexample”。)
離線問題撤離系統:實施一個問題避開系統,該系統在本地數據集中找到了用戶查詢的最相關答案。
文檔群集和建議引擎:根據其邊緣上的文本內容自動組織和組織文檔。
通過利用相似性SearchKit ,開發人員可以輕鬆地創建強大的應用程序,以使數據保持在不在家裡的情況下,而無需在功能或性能方面進行重大折衷。
要安裝相似之處,只需使用Swift Package Manager將其添加為Swift項目的依賴項。我建議通過以下方式親自使用Xcode方法:
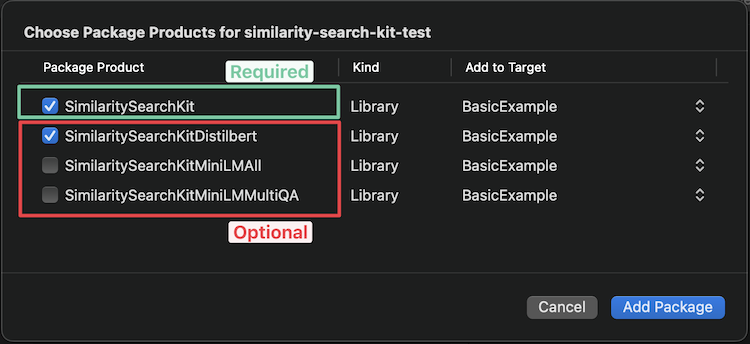
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode應該為您提供以下選項,以選擇要添加的模型(請參見下面的可用模型以獲取幫助選擇):
如果要通過Package.swift添加它,請在依賴項數組中添加以下行:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )然後,將適當的目標依賴性添加到所需的目標:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )如果您只想使用可用模型的子集,則可以省略相應的依賴關係。這將減少您最終二進制的大小。
要在您的項目中使用相似性搜索Kit,請首先導入框架:
import SimilaritySearchKit接下來,使用所需的距離度量和嵌入模型創建一個相似Index的實例(有關選項,請參見下文):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)然後,添加您要在索引中搜索的文本:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)最後,查詢與給定查詢最相似項目的索引:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results )輸出一個搜索量數組: [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
這些Examples目錄包含多個樣本iOS和MACOS應用程序,這些應用程序演示瞭如何最大程度地使用相似之處。
| 例子 | 描述 | 要求 |
|---|---|---|
BasicExample | 一個基本的乘法應用程序,該應用程序索引並比較了一組硬編碼字符串的相似性。 | iOS 16.0+,macOS 13.0+ |
PDFExample | MAC-Catalyst應用程序,可在單個PDF文件的內容上進行語義搜索。 | iOS 16.0+ |
ChatWithFilesExample | 高級MACOS應用程序,該應用程序索引計算機上的任何/所有文本文件。 | MacOS 13.0+ |
| 模型 | 用例 | 尺寸 | 來源 |
|---|---|---|---|
NaturalLanguage | 文字相似性,更快的推斷 | 內建 | 蘋果 |
MiniLMAll | 文字相似性,最快的推斷 | 46 MB | 擁抱面 |
Distilbert | 問答搜索,準確性最高 | 86 MB(量化) | 擁抱面 |
MiniLMMultiQA | 問答搜索,最快的推理 | 46 MB | 擁抱面 |
模型符合EmbeddingProtocol ,並且可以與SimilarityIndex類互換使用。
在Huggingface上,可以在此存儲庫中找到一個少量但不斷增長的預製模型列表。如果您有一個希望添加到列表中的模型,請打開問題或提交拉動請求。
| 公制 | 描述 |
|---|---|
DotProduct | 測量兩個向量之間的相似性作為其幅度的乘積 |
CosineSimilarity | 通過測量兩個向量之間的角度的餘弦來計算相似性 |
EuclideanDistance | 計算歐幾里得空間中兩個點之間的直線距離 |
指標符合DistanceMetricProtocol ,並且可以與SimilarityIndex類別互換使用。
SimilarityIndex Index的所有主要部分都可以通過符合以下協議的自定義實現來覆蓋:
接受一個字符串並返回代表輸入文本嵌入的浮子數組。
func encode ( sentence : String ) async -> [ Float ] ?接受查詢嵌入向量和嵌入量矢量列表,並返回距離度量評分的元組和最近鄰居的索引。
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]將一根字符串分成給定尺寸的塊,並具有給定的重疊。這對於將長文檔分成較小的塊以嵌入很有用。它返回了每個塊的塊列表和可選的tokensids列表。
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )令牌和陳詞濫調。將其用於使用與當前列表中可用的不同令牌的自定義模型。
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> String保存和加載索引項目。默認實現使用JSON文件,但是可以使用任何存儲機制。
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] 該項目的許多部分均來自現有代碼(已經在迅速中,要么都轉化為Swift,因此得益於Chatgpt。這些是引用的一些主要項目:
該項目的靈感來自於Chatgpt出現的自然語言服務和應用程序中令人難以置信的進步。儘管這些服務已經解鎖了一個全新的基於文本的應用程序的全新世界,但它們通常依靠雲服務。具體而言,許多“與數據聊天”服務需要用戶將數據上傳到遠程服務器進行處理和存儲。儘管這對某些人有用,但它可能並不適合低連通性環境中的人們,也不適合處理機密或敏感信息。儘管Apple確實捆綁了庫的NaturalLanguage ,但Coreml模型轉換過程開闢了許多模型和用例。考慮到這一點, SeplitySearchKit旨在提供一個可靠的,設備的解決方案,使開發人員能夠在Apple生態系統中創建最新的NLP應用程序。
這是計劃發布的一些功能的簡短列表:
我很想知道人們如何使用此庫以及其他哪些功能將是有用的,因此請隨時通過Twitter @zachnagengast或電子郵件Znagengast(at)Gmail(dot)com伸出援手。


