similarity search kit
0.0.15

유사한 SearchKit 은 몇 줄로 iOS 및 MACOS 응용 프로그램에 대한 기기 텍스트 임베드 및 시맨틱 검색 기능을 가능하게하는 신속한 패키지입니다. 속도, 확장 성 및 개인 정보를 강조하는이 제품은 다양한 옵션을위한 완벽한 통합 외에도 다양한 최첨단 NLP 모델 및 유사성 측정 항목을 지원합니다.
유사성 검색 의 일부 잠재적 사용 사례는 다음과 같습니다.
개인 정보 집중 문서 검색 엔진 : 사용자 데이터를 외부 서비스에 노출시키지 않고도 민감한 문서를 로컬로 처리하는 검색 엔진을 만듭니다. (예제 디렉토리의 프로젝트 "ChatwithFileSexample"참조.)
오프라인 질문 응답 시스템 : 로컬 데이터 세트 내에서 사용자의 쿼리에 가장 관련성이 높은 답변을 찾는 질문 응답 시스템을 구현합니다.
문서 클러스터링 및 권장 엔진 : 가장자리의 텍스트 내용을 기반으로 문서를 자동으로 그룹화하고 구성합니다.
유사성 검색을 활용하여 개발자는 기능이나 성능의 주요 트레이드 오프없이 데이터를 집에 가깝게 유지하는 강력한 응용 프로그램을 쉽게 만들 수 있습니다.
유사성 SearchKit을 설치하려면 Swift 패키지 관리자를 사용하여 Swift 프로젝트에 종속성으로 추가하십시오. Xcode 메소드를 개인적으로 사용하는 것이 좋습니다.
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode는 추가하려는 모델을 선택할 수있는 다음 옵션을 제공해야합니다 (아래에서 사용 가능한 모델 참조).
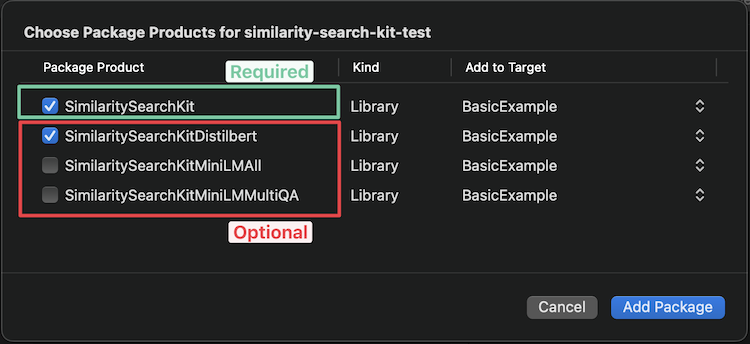
Package.swift 통해 추가하려면 다음 줄을 종속성 배열에 추가하십시오.
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )그런 다음 원하는 대상에 적절한 대상 종속성을 추가하십시오.
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )사용 가능한 모델의 하위 집합 만 사용하려면 해당 종속성을 생략 할 수 있습니다. 이렇게하면 최종 바이너리의 크기가 줄어 듭니다.
프로젝트에서 유사성 검색을 사용하려면 먼저 프레임 워크를 가져옵니다.
import SimilaritySearchKit다음으로 원하는 거리 메트릭 및 임베딩 모델을 사용하여 유사성 인덱스 인스턴스를 만듭니다 (옵션은 아래 참조).
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)그런 다음 색인을 검색 할 수있는 텍스트를 추가하십시오.
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)마지막으로, 주어진 쿼리와 가장 유사한 항목에 대한 색인을 쿼리하십시오.
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) SearchResult 배열을 출력합니다 [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
Examples 디렉토리에는 Multple Sample iOS 및 MACOS 응용 프로그램이 포함되어있어 유사성 검색을 최대한 사용하는 방법을 보여줍니다.
| 예 | 설명 | 요구 사항 |
|---|---|---|
BasicExample | 작은 하드 코드 스트링 세트의 유사성을 색인화하고 비교하는 기본 멀티 플랫폼 응용 프로그램. | iOS 16.0+, MACOS 13.0+ |
PDFExample | 개별 PDF 파일의 내용에서 의미 론적 검색을 가능하게하는 Mac-Catalyst 응용 프로그램. | iOS 16.0+ |
ChatWithFilesExample | 컴퓨터의 모든/모든 텍스트 파일을 색인화하는 고급 MACOS 응용 프로그램. | 마코스 13.0+ |
| 모델 | 유스 케이스 | 크기 | 원천 |
|---|---|---|---|
NaturalLanguage | 텍스트 유사성, 더 빠른 추론 | 내장 | 사과 |
MiniLMAll | 텍스트 유사성, 가장 빠른 추론 | 46MB | 포옹 페이스 |
Distilbert | Q & A 검색, 최고 정확도 | 86MB (양자화) | 포옹 페이스 |
MiniLMMultiQA | Q & A 검색, 가장 빠른 추론 | 46MB | 포옹 페이스 |
모델은 EmbeddingProtocol 준수하며 SimilarityIndex 클래스와 상호 교환 적으로 사용할 수 있습니다.
포옹 페이스 의이 저장소에서 작지만 성장하는 사전 변환 모델 목록을 찾을 수 있습니다. 목록에 추가하려는 모델이 있으시면 문제를 열거나 풀 요청을 제출하십시오.
| 메트릭 | 설명 |
|---|---|
DotProduct | 두 벡터 간의 유사성을 크기의 산물로 측정합니다. |
CosineSimilarity | 두 벡터 사이의 각도의 코사인을 측정하여 유사성을 계산합니다. |
EuclideanDistance | 유클리드 공간에서 두 지점 사이의 직선 거리를 계산합니다. |
메트릭은 DistanceMetricProtocol 준수하며 SimilarityIndex 클래스와 상호 교환 적으로 사용할 수 있습니다.
SimilarityIndex 의 모든 주요 부분은 다음 프로토콜을 준수하는 사용자 정의 구현으로 재정의 할 수 있습니다.
문자열을 허용하고 입력 텍스트의 임베딩을 나타내는 플로트 배열을 반환합니다.
func encode ( sentence : String ) async -> [ Float ] ?쿼리 임베딩 벡터와 임베딩 벡터 목록을 허용하고 거리 메트릭 스코어의 튜플과 가장 가까운 이웃의 인덱스를 반환합니다.
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]주어진 겹침으로 주어진 크기의 덩어리로 문자열을 분할합니다. 이것은 긴 문서를 임베딩을 위해 작은 덩어리로 나누는 데 유용합니다. 청크 목록과 각 청크에 대한 선택적 목록 목록을 반환합니다.
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )텍스트를 토큰 화하고 detoken습니다. 현재 목록에서 사용할 수있는 것보다 다른 토큰 화기를 사용하는 사용자 정의 모델에는 이것을 사용하십시오.
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> String인덱스 항목을 저장 및로드합니다. 기본 구현은 JSON 파일을 사용하지만 스토리지 메커니즘을 사용하려면 재정의 할 수 있습니다.
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] 이 프로젝트의 많은 부분은 이미 Swift에 있거나 ChatGpt 덕분에 기존 코드에서 파생되었습니다. 이들은 언급 된 주요 프로젝트 중 일부입니다.
이 프로젝트는 Chatgpt의 출현으로 자연어 서비스 및 응용 프로그램의 놀라운 발전에서 영감을 얻었습니다. 이러한 서비스는 강력한 텍스트 기반 응용 프로그램의 완전히 새로운 세계를 잠금 해제했지만 종종 클라우드 서비스에 의존합니다. 특히, 많은 "데이터와 채팅"서비스를 사용하려면 사용자가 처리 및 스토리지를 위해 원격 서버에 데이터를 업로드해야합니다. 이것은 일부에게는 효과적이지만 연결성이 낮거나 기밀 또는 민감한 정보를 처리하는 데 가장 적합하지 않을 수 있습니다. Apple은 유사한 작업을위한 번들로드 라이브러리가 NaturalLanguage 이지만 Coreml 모델 변환 프로세스는 훨씬 더 넓은 모델 및 사용 사례를 열어줍니다. 이를 염두에두고 유사한 Searchkit은 개발자가 Apple 생태계 내에서 최첨단 NLP 애플리케이션을 만들 수있는 강력한 기기 솔루션을 제공하는 것을 목표로합니다.
다음은 향후 릴리스를 위해 계획된 일부 기능의 짧은 목록입니다.
사람들 이이 라이브러리를 어떻게 사용하는지, 다른 기능이 어떤 유용한 지 궁금합니다. 트위터 @zachnagengast 또는 이메일 znagengast (at) gmail (dot) com에 연락하십시오.


