similarity search kit
0.0.15

SimilaritySearchKit é um pacote SWIFT que permite incorporação de texto no dispositivo e funcionalidade de pesquisa semântica para aplicativos iOS e MacOS em apenas algumas linhas. Enfatizando a velocidade, a extensibilidade e a privacidade, ele suporta uma variedade de modelos de NLP de última geração e métricas de similaridade, além da integração perfeita para opções de trazer-seu.
Alguns casos de uso em potencial para similaritySearchKit incluem:
Mecanismos de pesquisa de documentos focados na privacidade: Crie um mecanismo de pesquisa que processe documentos confidenciais localmente, sem expor os dados do usuário a serviços externos. (Consulte Exemplo Projeto "ChatWithFileSexample" no diretório Exemplos.)
Sistemas offline de resposta a perguntas: Implemente um sistema de resposta a perguntas que encontra as respostas mais relevantes para a consulta de um usuário em um conjunto de dados local.
Documentar mecanismos de cluster e recomendação: agrupe e organize automaticamente os documentos com base em seu conteúdo textual no limite.
Ao alavancar o similaritySearchKit , os desenvolvedores podem facilmente criar aplicativos poderosos que mantêm os dados próximos de casa sem grandes trocas de funcionalidade ou desempenho.
Para instalar o similaritysearchkit , basta adicioná -lo como uma dependência ao seu projeto SWIFT usando o Swift Package Manager. Eu recomendo usar o método Xcode pessoalmente via:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
O Xcode deve fornecer as seguintes opções para escolher qual modelo você deseja adicionar (consulte os modelos disponíveis abaixo para obter ajuda para escolher):
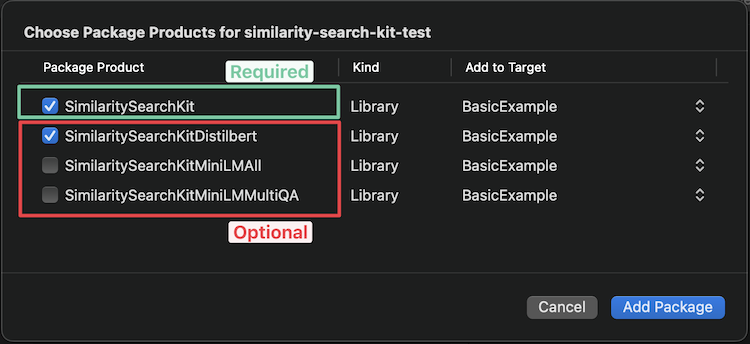
Se você deseja adicioná -lo via Package.swift , adicione a seguinte linha à sua matriz de dependências:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )Em seguida, adicione a dependência alvo apropriada ao alvo desejado:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )Se você deseja usar apenas um subconjunto dos modelos disponíveis, poderá omitir a dependência correspondente. Isso reduzirá o tamanho do seu binário final.
Para usar o similaritySearchKit em seu projeto, primeiro importe a estrutura:
import SimilaritySearchKitEm seguida, crie uma instância de similarityIndex com a métrica de distância desejada e o modelo de incorporação (veja abaixo para opções):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)Em seguida, adicione seu texto que você deseja tornar pesquisável ao índice:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)Por fim, consulte o índice para os itens mais semelhantes a uma determinada consulta:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) Que produz uma matriz de pesquisa : [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
O diretório Examples contém aplicativos iOS e macos de múltiplos amostras que demonstram como usar o similaritySearchKit em toda a sua extensão.
| Exemplo | Descrição | Requisitos |
|---|---|---|
BasicExample | Um aplicativo básico de multiplataforma que indexa e compara a similaridade de um pequeno conjunto de seqüências codificadas. | iOS 16.0+, MacOS 13.0+ |
PDFExample | Um aplicativo de catalisador MAC que permite a pesquisa semântica no conteúdo de arquivos PDF individuais. | iOS 16.0+ |
ChatWithFilesExample | Um aplicativo MacOS avançado que indexa todos os arquivos de texto no seu computador. | MacOS 13.0+ |
| Modelo | Caso de uso | Tamanho | Fonte |
|---|---|---|---|
NaturalLanguage | Similaridade de texto, inferência mais rápida | Embutido | Maçã |
MiniLMAll | Similaridade de texto, inferência mais rápida | 46 MB | Huggingface |
Distilbert | Pesquisa de perguntas e respostas, maior precisão | 86 MB (quantizado) | Huggingface |
MiniLMMultiQA | Pesquisa de perguntas e respostas, inferência mais rápida | 46 MB | Huggingface |
Os modelos estão em conformidade com o EmbeddingProtocol e podem ser usados de forma intercambiável com a classe SimilarityIndex .
Uma lista pequena, mas crescente de modelos pré-convertidos, pode ser encontrada neste repositório no Huggingface. Se você tiver um modelo que gostaria de ver adicionado à lista, abra um problema ou envie uma solicitação de tração.
| Métrica | Descrição |
|---|---|
DotProduct | Mede a semelhança entre dois vetores como o produto de suas magnitudes |
CosineSimilarity | Calcula a similaridade medindo o cosseno do ângulo entre dois vetores |
EuclideanDistance | Calcula a distância linear entre dois pontos no espaço euclidiano |
As métricas estão em conformidade com o DistanceMetricProtocol e podem ser usadas de forma intercambiável com a classe SimilarityIndex .
Todas as partes principais do SimilarityIndex podem ser substituídas com implementações personalizadas que estão em conformidade com os seguintes protocolos:
Aceita uma string e retorna uma variedade de carros alegóricos que representam a incorporação do texto de entrada.
func encode ( sentence : String ) async -> [ Float ] ?Aceita um vetor de incorporação de consulta e uma lista de vetores de incorporação e retorna uma tupla da pontuação métrica de distância e o índice do vizinho mais próximo.
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]Divide uma corda em pedaços de um determinado tamanho, com uma determinada sobreposição. Isso é útil para dividir documentos longos em pedaços menores para incorporar. Ele retorna a lista de pedaços e uma lista opcional de tokensids para cada pedaço.
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )Tokeniza e detecta o texto. Use isso para modelos personalizados que usam tokenizadores diferentes do que estão disponíveis na lista atual.
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> StringSalvar e carregar itens de índice. A implementação padrão usa arquivos JSON, mas isso pode ser superestimado para usar qualquer mecanismo de armazenamento.
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] Muitas partes deste projeto foram derivadas do código existente, já em Swift, ou traduzido em Swift, graças ao ChatGPT. Estes são alguns dos principais projetos que foram referenciados:
Este projeto foi inspirado pelos incríveis avanços nos serviços e aplicativos de linguagem natural que surgiram com o surgimento do ChatGPT. Embora esses serviços tenham desbloqueado um mundo totalmente novo de aplicativos poderosos baseados em texto, eles geralmente dependem de serviços em nuvem. Especificamente, muitos serviços "bate -papo com dados" exigem que os usuários enviem seus dados para servidores remotos para processamento e armazenamento. Embora isso funcione para alguns, pode não ser o mais adequado para aqueles em ambientes de baixa conectividade ou lidar com informações confidenciais ou confidenciais. Enquanto a Apple possui a biblioteca NaturalLanguage para tarefas semelhantes, o processo de conversão do modelo COREML abre uma variedade muito mais ampla de modelos e casos de uso. Com isso em mente, o similaritySearchKit pretende fornecer uma solução robusta e no dispositivo que permita aos desenvolvedores criar aplicativos de NLP de última geração no ecossistema da Apple.
Aqui está uma pequena lista de alguns recursos planejados para lançamentos futuros:
Estou curioso para ver como as pessoas usam essa biblioteca e quais outros recursos seriam úteis; portanto, não hesite em alcançar o Twitter @zachnagengast ou enviar um e -mail para Znagengast (AT) Gmail (DOT) com.


