similarity search kit
0.0.15

Kesamaan Penelitian adalah paket Swift yang memungkinkan embeddings teks di perangkat dan fungsi pencarian semantik untuk aplikasi iOS dan macOS hanya dalam beberapa baris. Menekankan kecepatan, ekstensibilitas, dan privasi, ini mendukung berbagai model NLP yang canggih dan metrik kesamaan, selain integrasi yang mulus untuk opsi membawa sendiri.
Beberapa kasus penggunaan potensial untuk EcualitySearchKit meliputi:
Mesin pencari dokumen yang berfokus pada privasi: Buat mesin pencari yang memproses dokumen sensitif secara lokal, tanpa mengekspos data pengguna ke layanan eksternal. (Lihat contoh proyek "chatwithfilesexample" di direktori contoh.)
Sistem Penerimaan Pertanyaan Offline: Menerapkan sistem jawaban pertanyaan yang menemukan jawaban yang paling relevan untuk permintaan pengguna dalam dataset lokal.
Dokumen Pengelompokan dan Mesin Rekomendasi: Secara otomatis mengelompokkan dan mengatur dokumen berdasarkan konten tekstual mereka di tepi.
Dengan memanfaatkan kesamaan Cendera , pengembang dapat dengan mudah membuat aplikasi yang kuat yang menjaga data tetap dekat dengan rumah tanpa pengorbanan utama dalam fungsi atau kinerja.
Untuk menginstal ExonicitySearchKit , cukup tambahkan sebagai ketergantungan pada proyek Swift Anda menggunakan Swift Package Manager. Saya sarankan menggunakan metode Xcode secara pribadi melalui:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode harus memberi Anda opsi berikut untuk memilih model mana yang ingin Anda tambahkan (lihat model yang tersedia di bawah ini untuk membantu memilih):
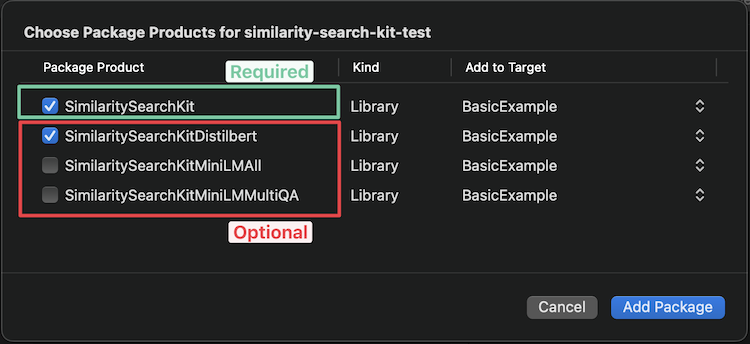
Jika Anda ingin menambahkannya melalui Package.swift , tambahkan baris berikut ke array dependensi Anda:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )Kemudian, tambahkan ketergantungan target yang sesuai ke target yang diinginkan:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )Jika Anda hanya ingin menggunakan subset dari model yang tersedia, Anda dapat menghilangkan ketergantungan yang sesuai. Ini akan mengurangi ukuran biner akhir Anda.
Untuk menggunakan kesamaan CEARTERKIT dalam proyek Anda, pertama -tama impor kerangka kerja:
import SimilaritySearchKitSelanjutnya, buat instance kesamaanindeks dengan metrik jarak dan model embedding yang Anda inginkan (lihat di bawah untuk opsi):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)Kemudian, tambahkan teks Anda yang ingin Anda dapat dicari ke indeks:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)Akhirnya, kueri indeks untuk item yang paling mirip dengan kueri yang diberikan:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) Yang mengeluarkan array searchResult : [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
Direktori Examples berisi aplikasi iOS dan macOS sampel multple yang menunjukkan cara menggunakan kesamaan CenderaKit sejauh ini.
| Contoh | Keterangan | Persyaratan |
|---|---|---|
BasicExample | Aplikasi multiplatform dasar yang mengindeks dan membandingkan kesamaan dari serangkaian kecil string hardcoded. | iOS 16.0+, MacOS 13.0+ |
PDFExample | Aplikasi Katalis Mac yang memungkinkan pencarian semantik pada konten file PDF individu. | iOS 16.0+ |
ChatWithFilesExample | Aplikasi MacOS canggih yang mengindeks setiap file teks di komputer Anda. | MacOS 13.0+ |
| Model | Gunakan kasing | Ukuran | Sumber |
|---|---|---|---|
NaturalLanguage | Kesamaan teks, inferensi yang lebih cepat | Bawaan | Apel |
MiniLMAll | Kesamaan teks, inferensi tercepat | 46 MB | Huggingface |
Distilbert | Pencarian Tanya Jawab, Akurasi Tertinggi | 86 MB (dikuantisasi) | Huggingface |
MiniLMMultiQA | Pencarian T&J, inferensi tercepat | 46 MB | Huggingface |
Model sesuai dengan EmbeddingProtocol dan dapat digunakan secara bergantian dengan kelas SimilarityIndex .
Daftar kecil model pra-konversi dapat ditemukan dalam repo ini di Huggingface. Jika Anda memiliki model yang ingin Anda lihat ditambahkan ke daftar, buka masalah atau kirimkan permintaan tarik.
| Metrik | Keterangan |
|---|---|
DotProduct | Mengukur kesamaan antara dua vektor sebagai produk dari besaran mereka |
CosineSimilarity | Menghitung kesamaan dengan mengukur kosinus sudut antara dua vektor |
EuclideanDistance | Menghitung jarak garis lurus antara dua titik di ruang Euclidean |
Metrik sesuai dengan DistanceMetricProtocol dan dapat digunakan secara bergantian dengan kelas SimilarityIndex .
Semua bagian utama dari SimilarityIndex dapat ditimpa dengan implementasi khusus yang sesuai dengan protokol berikut:
Menerima string dan mengembalikan array pelampung yang mewakili embedding dari teks input.
func encode ( sentence : String ) async -> [ Float ] ?Menerima vektor embedding kueri dan daftar vektor embeddings dan mengembalikan tuple dari skor metrik jarak dan indeks tetangga terdekat.
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]Membagi string menjadi potongan -potongan dengan ukuran tertentu, dengan tumpang tindih yang diberikan. Ini berguna untuk membagi dokumen panjang menjadi potongan yang lebih kecil untuk penyematan. Ini mengembalikan daftar potongan dan daftar opsional tokensid untuk setiap potongan.
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )Tokenisasi dan melepaskan teks. Gunakan ini untuk model khusus yang menggunakan tokenizer yang berbeda dari yang tersedia dalam daftar saat ini.
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> StringSimpan dan Muat Item Indeks. Implementasi default menggunakan file JSON, tetapi ini bisa ditimpa untuk menggunakan mekanisme penyimpanan apa pun.
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] Banyak bagian dari proyek ini berasal dari kode yang ada, baik sudah cepat, atau diterjemahkan ke dalam cepat berkat chatgpt. Ini adalah beberapa proyek utama yang dirujuk:
Proyek ini telah terinspirasi oleh kemajuan luar biasa dalam layanan bahasa alami dan aplikasi yang muncul dengan munculnya chatgpt. Sementara layanan ini telah membuka kunci dunia baru dari aplikasi berbasis teks yang kuat, mereka sering mengandalkan layanan cloud. Secara khusus, banyak layanan "obrolan dengan data" mengharuskan pengguna untuk mengunggah data mereka ke server jarak jauh untuk pemrosesan dan penyimpanan. Meskipun ini berfungsi untuk beberapa orang, itu mungkin bukan yang paling cocok untuk mereka yang berada di lingkungan konektivitas rendah, atau menangani informasi rahasia atau sensitif. Sementara Apple memang telah membundel perpustakaan NaturalLanguage untuk tugas -tugas serupa, proses konversi model COREML membuka serangkaian model yang jauh lebih luas dan kasus penggunaan. Dengan pemikiran ini, kesamaan Cebatkit bertujuan untuk memberikan solusi di perangkat yang kuat yang memungkinkan pengembang untuk membuat aplikasi NLP yang canggih dalam ekosistem Apple.
Berikut daftar pendek beberapa fitur yang direncanakan untuk rilis di masa mendatang:
Saya ingin tahu bagaimana orang menggunakan perpustakaan ini dan fitur apa yang akan berguna, jadi jangan ragu untuk menjangkau di Twitter @zachnagengast atau mengirim email kepada Znagengast (at) Gmail (DOT) com.


