similarity search kit
0.0.15

SimilitySearchkit est un package rapide permettant des incorporations de texte sur disque et des fonctionnalités de recherche sémantique pour les applications iOS et macOS en quelques lignes. Soulignant la vitesse, l'extensibilité et la confidentialité, il prend en charge une variété de modèles PNL de pointe intégrés et de mesures de similitude, en plus de l'intégration transparente pour les options d'apport.
Certains cas d'utilisation potentiels pour la similitude de recherche comprennent:
Moteurs de recherche de documents axés sur la confidentialité: Créez un moteur de recherche qui traite localement des documents sensibles, sans exposer les données utilisateur aux services externes. (Voir l'exemple de projet "ChatWithFilesexample" dans le répertoire des exemples.)
Systèmes de réponses hors ligne: implémentez un système de réponse aux questions qui trouve les réponses les plus pertinentes à la requête d'un utilisateur dans un ensemble de données local.
Moteurs de clustering et de recommandation de documents: regroupant et organisez automatiquement des documents en fonction de leur contenu textuel sur le bord.
En tirant parti de similitudeSearchKit , les développeurs peuvent facilement créer des applications puissantes qui gardent les données près de la maison sans compromis majeurs dans la fonctionnalité ou les performances.
Pour installer SimilitySearchKit , ajoutez-le simplement en fonction de votre projet Swift à l'aide du gestionnaire de packages Swift. Je recommande d'utiliser la méthode Xcode personnellement via:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode devrait vous offrir les options suivantes pour choisir le modèle que vous souhaitez ajouter (voir les modèles disponibles ci-dessous pour aider à choisir):
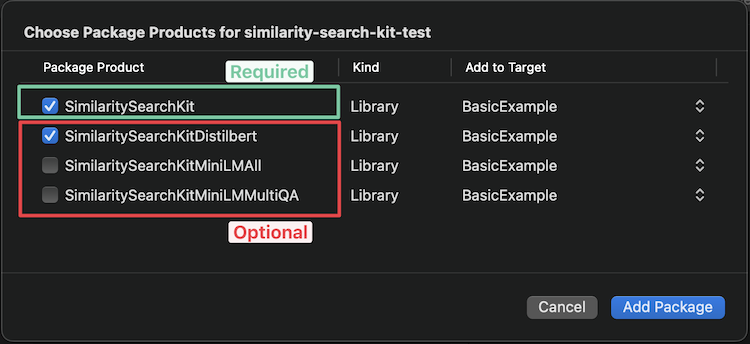
Si vous souhaitez l'ajouter via Package.swift , ajoutez la ligne suivante à votre tableau de dépendances:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )Ensuite, ajoutez la dépendance cible appropriée à la cible souhaitée:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )Si vous souhaitez seulement utiliser un sous-ensemble des modèles disponibles, vous pouvez omettre la dépendance correspondante. Cela réduira la taille de votre binaire final.
Pour utiliser SimilitySearchKit dans votre projet, importez d'abord le cadre:
import SimilaritySearchKitEnsuite, créez une instance de SimilityIndex avec le modèle de métrique et d'intégration de distance souhaitée (voir ci-dessous pour les options):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)Ensuite, ajoutez votre texte que vous souhaitez rendre consultable à l'index:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)Enfin, interrogez l'index pour les éléments les plus similaires à une requête donnée:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) Qui publie un tableau de recherche : [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
Le répertoire Examples contient des applications iOS et macOS multiples qui montrent comment utiliser la similitude de recherche dans sa mesure.
| Exemple | Description | Exigences |
|---|---|---|
BasicExample | Une application multiplateforme de base qui index et compare la similitude d'un petit ensemble de chaînes codées en dur. | iOS 16.0+, macOS 13.0+ |
PDFExample | Une application Mac-catalyst qui permet une recherche sémantique sur le contenu des fichiers PDF individuels. | iOS 16.0+ |
ChatWithFilesExample | Une application MacOS avancée qui index tous les fichiers texte sur votre ordinateur. | macOS 13.0+ |
| Modèle | Cas d'utilisation | Taille | Source |
|---|---|---|---|
NaturalLanguage | Similitude du texte, inférence plus rapide | Intégré | Pomme |
MiniLMAll | Similitude du texte, inférence la plus rapide | 46 MB | Étreinte |
Distilbert | Recherche de questions et réponses, précision la plus élevée | 86 Mb (quantifié) | Étreinte |
MiniLMMultiQA | Recherche de questions et réponses, inférence la plus rapide | 46 MB | Étreinte |
Les modèles sont conformes au EmbeddingProtocol et peuvent être utilisés de manière interchangeable avec la classe SimilarityIndex .
Une liste petite mais croissante de modèles préfabriqués se trouve dans ce dépôt sur HuggingFace. Si vous avez un modèle que vous souhaitez voir ajouté à la liste, veuillez ouvrir un problème ou soumettre une demande de traction.
| Métrique | Description |
|---|---|
DotProduct | Mesure la similitude entre deux vecteurs comme le produit de leurs amplitudes |
CosineSimilarity | Calcule la similitude en mesurant le cosinus de l'angle entre deux vecteurs |
EuclideanDistance | Calcule la distance en ligne droite entre deux points dans l'espace euclidien |
Les métriques sont conformes au DistanceMetricProtocol et peuvent être utilisées de manière interchangeable avec la classe SimilarityIndex .
Toutes les principales parties de la SimilarityIndex peuvent être remplacées par des implémentations personnalisées conformes aux protocoles suivants:
Accepte une chaîne et renvoie un tableau de flotteurs représentant l'incorporation du texte d'entrée.
func encode ( sentence : String ) async -> [ Float ] ?Accepte un vecteur d'intégration de requête et une liste de vecteurs d'intégration et renvoie un tuple du score métrique de distance et de l'indice du voisin le plus proche.
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]Fruit une chaîne en morceaux d'une taille donnée, avec un chevauchement donné. Ceci est utile pour diviser de longs documents en morceaux plus petits pour l'intégration. Il renvoie la liste des morceaux et une liste facultative de tokensids pour chaque morceau.
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )Tokenise et détokenise le texte. Utilisez-le pour des modèles personnalisés qui utilisent des tokenisants différents de ceux disponibles dans la liste actuelle.
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> StringEnregistrer et charger les éléments d'index. L'implémentation par défaut utilise des fichiers JSON, mais cela peut être remplacé pour utiliser n'importe quel mécanisme de stockage.
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] De nombreuses parties de ce projet ont été dérivées du code existant, soit déjà à Swift, soit traduites en Swift grâce à Chatgpt. Ce sont quelques-uns des principaux projets qui ont été référencés:
Ce projet a été inspiré par les progrès incroyables des services et applications en langage naturel qui ont eu lieu avec l'émergence de Chatgpt. Bien que ces services aient débloqué un tout nouveau monde d'applications de texte puissantes, elles comptent souvent sur les services cloud. Plus précisément, de nombreux services "discuter avec les données" nécessitent que les utilisateurs téléchargent leurs données sur des serveurs distants pour le traitement et le stockage. Bien que cela fonctionne pour certains, il pourrait ne pas être le mieux adapté à ceux qui dans des environnements à faible connectivité, ou à gérer des informations confidentielles ou sensibles. Bien qu'Apple ait une bibliothèque groupée NaturalLanguage pour des tâches similaires, le processus de conversion du modèle COREML ouvre un tableau beaucoup plus large de modèles et de cas d'utilisation. Dans cet esprit, SimilitySearchKit vise à fournir une solution robuste et à disque qui permet aux développeurs de créer des applications NLP de pointe dans l'écosystème Apple.
Voici une courte liste de certaines fonctionnalités prévues pour les versions futures:
Je suis curieux de voir comment les gens utilisent cette bibliothèque et quelles autres fonctionnalités seraient utiles, alors n'hésitez pas à contacter Twitter @zachnaGengast ou envoyer un courriel à Znagengast (at) gmail (dot) com.


