similarity search kit
0.0.15

SexitySearchKit -это быстрый пакет, включающий в себя текстовые встроения в области текста и функциональность семантического поиска для приложений iOS и MacOS всего за несколько строк. Подчеркивая скорость, расширяемость и конфиденциальность, он поддерживает различные встроенные современные модели NLP и показатели сходства, в дополнение к бесшовной интеграции для вариантов принесения ваших владений.
Некоторые потенциальные варианты использования для сходства , включают в себя:
Поисковые системы документов, ориентированные на конфиденциальность: Создайте поисковую систему, которая обрабатывает конфиденциальные документы локально, не подвергая пользовательских данных внешним службам. (См. Пример проекта «Chatwithfilesexample» в каталоге примеров.)
Автономные системы, отвечающие вопросам: внедрить систему с ответами на вопросы, которая находит наиболее релевантные ответы на запрос пользователя в локальном наборе данных.
Кластеризация и рекомендательные двигатели документов: автоматически группируйте и организуют документы на основе их текстового контента на краю.
Используя сходство SailySearchKit , разработчики могут легко создавать мощные приложения, которые держат данные близко к дому без крупных компромиссов в функциональности или производительности.
Чтобы установить сходство SexitySearchKit , просто добавьте его в качестве зависимости к вашему проекту Swift, используя Swift Package Manager. Я рекомендую использовать метод xcode лично через:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode должен дать вам следующие параметры, чтобы выбрать, какую модель вы хотите добавить (см. Доступные модели ниже для выбора помощи):
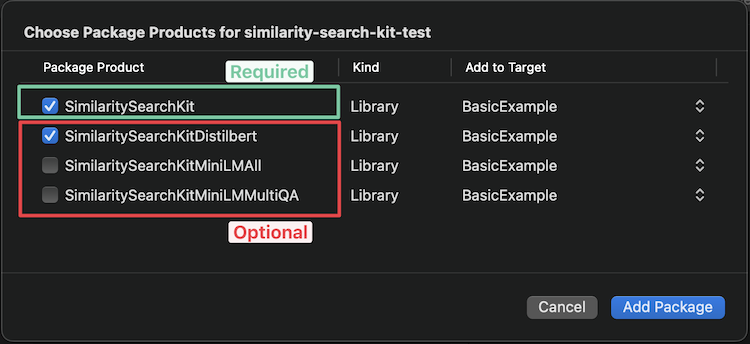
Если вы хотите добавить его через Package.swift , добавьте следующую строку в свой массив зависимостей:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )Затем добавьте соответствующую целевую зависимость к желаемой цели:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )Если вы хотите использовать только подмножество доступных моделей, вы можете опустить соответствующую зависимость. Это уменьшит размер вашего окончательного двоичного файла.
Чтобы использовать SexingSearchKit в вашем проекте, сначала импортируйте структуру:
import SimilaritySearchKitДалее, создайте экземпляр сходства Index с желаемой метрикой расстояния и модели встроенного встроения (см. Ниже для параметров):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)Затем добавьте свой текст, который вы хотите сделать для поиска в индекс:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)Наконец, запросите индекс для наиболее похожих предметов на заданный запрос:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) Который выводит массив SearchResult : [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
Справочник Examples содержит многопрочные образцы приложений iOS и MacOS, которые демонстрируют, как использовать сходство , в полной мере.
| Пример | Описание | Требования |
|---|---|---|
BasicExample | Основное многоплатформенное приложение, которое индексирует и сравнивает сходство небольшого набора жестко -кодированных строк. | iOS 16,0+, macOS 13,0+ |
PDFExample | Приложение MAC-катализатора, которое включает семантический поиск на содержимое отдельных файлов PDF. | iOS 16,0+ |
ChatWithFilesExample | Усовершенствованное приложение MacOS, которое индексирует любые/все текстовые файлы на вашем компьютере. | macOS 13,0+ |
| Модель | Вариант использования | Размер | Источник |
|---|---|---|---|
NaturalLanguage | Сходство текста, более быстрый вывод | Встроенный | Яблоко |
MiniLMAll | Сходство текста, самый быстрый вывод | 46 МБ | Объятие |
Distilbert | Поиск вопросов и ответов, самая высокая точность | 86 МБ (квантовая) | Объятие |
MiniLMMultiQA | Поиск вопросов и ответов, самый быстрый вывод | 46 МБ | Объятие |
Модели соответствуют EmbeddingProtocol и могут использоваться взаимозаменяемо с классом SimilarityIndex .
Небольшой, но растущий список предварительно преобразованных моделей можно найти в этом репо на Huggingface. Если у вас есть модель, которую вы хотели бы увидеть добавленной в список, откройте проблему или отправьте запрос на привлечение.
| Показатель | Описание |
|---|---|
DotProduct | Измеряет сходство между двумя векторами в качестве продукта их величин |
CosineSimilarity | Вычисляет сходство путем измерения косинуса угла между двумя векторами |
EuclideanDistance | Вычисляет прямолинейное расстояние между двумя точками в евклидовом пространстве |
Метрики соответствуют DistanceMetricProtocol и могут использоваться взаимозаменяемо с классом SimilarityIndex .
Все основные части SimilarityIndex , которые могут быть переопределены с помощью пользовательских реализаций, которые соответствуют следующим протоколам:
Принимает строку и возвращает массив поплавков, представляющих встроение входного текста.
func encode ( sentence : String ) async -> [ Float ] ?Принимает запрос, встраивающий вектор, и список векторов встроенных векторов и возвращает кортеж с показателем показателя расстояния и индексом ближайшего соседа.
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]Разбивает струну на куски заданного размера, с данным перекрытием. Это полезно для разделения длинных документов на более мелкие куски для внедрения. Он возвращает список кусков и необязательный список токенсоров для каждой куски.
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )Токенизируют и детоксируют текст. Используйте это для пользовательских моделей, которые используют разные токенизаторы, чем доступны в текущем списке.
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> StringСохраните и загрузите элементы индекса. Реализация по умолчанию использует файлы JSON, но это можно переопределить, чтобы использовать любой механизм хранения.
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] Многие части этого проекта были получены из существующего кода, либо уже в Swift, либо переведены в Swift благодаря Chatgpt. Это некоторые из основных проектов, на которые были упомянуты:
Этот проект был вдохновлен невероятными достижениями в сфере естественного языка и приложениях, которые возникли с появлением CHATGPT. Хотя эти услуги разблокировали целый новый мир мощных текстовых приложений, они часто полагаются на облачные сервисы. В частности, многие «чат с данными» требуют, чтобы пользователи загружали свои данные на удаленные серверы для обработки и хранения. Хотя это работает для некоторых, это может быть не лучше всего подходит для тех, кто находится в средах с низким содержанием подключения, или обрабатывает конфиденциальную или конфиденциальную информацию. В то время как Apple имеет в комплекте библиотеку NaturalLanguage для аналогичных задач, процесс преобразования модели Coreml открывает гораздо более широкий спектр моделей и вариантов использования. Имея это в виду, сходство SailingSearchKit стремится предоставить надежное, настройки решения, которое позволяет разработчикам создавать самые современные приложения NLP в экосистеме Apple.
Вот краткий список некоторых функций, которые запланированы для будущих выпусков:
Мне любопытно посмотреть, как люди используют эту библиотеку и какие другие функции будут полезны, поэтому, пожалуйста, не стесняйтесь обращаться к Twitter @zachnagengast или по электронной почте Znagengast (AT) Gmail (Dot) Com.


