similarity search kit
0.0.15

ความคล้ายคลึงกัน SearchKit เป็นแพ็คเกจ Swift ที่เปิดใช้งานการฝังตัวข้อความ บนอุปกรณ์ และฟังก์ชั่นการค้นหาความหมายสำหรับแอปพลิเคชัน iOS และ MACOS ในไม่กี่บรรทัด เน้นความเร็วความสามารถในการขยายและความเป็นส่วนตัวรองรับความหลากหลายของโมเดล NLP ที่ทันสมัยในตัวและตัวชี้วัดความคล้ายคลึงกันนอกเหนือจากการรวมที่ไร้รอยต่อสำหรับตัวเลือกที่คุณเอง
กรณีการใช้งานที่มีศักยภาพบางอย่างสำหรับ ความคล้ายคลึงกัน SearchKit รวมถึง:
เครื่องมือค้นหาเอกสารที่เน้นความเป็นส่วนตัว: สร้างเครื่องมือค้นหาที่ประมวลผลเอกสารที่ละเอียดอ่อนในเครื่องโดยไม่เปิดเผยข้อมูลผู้ใช้ไปยังบริการภายนอก (ดูตัวอย่างโครงการ "chatwithfilesexample" ในไดเรกทอรีตัวอย่าง)
ระบบการตอบคำถามออฟไลน์: ใช้ระบบการตอบคำถามที่ค้นหาคำตอบที่เกี่ยวข้องมากที่สุดสำหรับแบบสอบถามของผู้ใช้ภายในชุดข้อมูลท้องถิ่น
การจัดกลุ่มเอกสารและเอ็นจิ้นคำแนะนำ: จัดกลุ่มและจัดระเบียบเอกสารโดยอัตโนมัติตามเนื้อหาที่เป็นข้อความของพวกเขาบนขอบ
ด้วยการใช้ประโยชน์ จากความคล้ายคลึงกัน SearchKit นักพัฒนาสามารถสร้างแอพพลิเคชั่นที่ทรงพลังที่เก็บข้อมูลไว้ใกล้บ้านโดยไม่ต้องแลกเปลี่ยนที่สำคัญในการใช้งานหรือประสิทธิภาพ
ในการติดตั้ง ความคล้ายคลึงกัน SearchKit เพียงเพิ่มเป็นการพึ่งพาโครงการ Swift ของคุณโดยใช้ Swift Package Manager ฉันแนะนำให้ใช้วิธี XCode เป็นการส่วนตัวผ่าน:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
XCode ควรให้ตัวเลือกต่อไปนี้เพื่อเลือกรุ่นที่คุณต้องการเพิ่ม (ดูรุ่นที่มีอยู่ด้านล่างเพื่อขอความช่วยเหลือ):
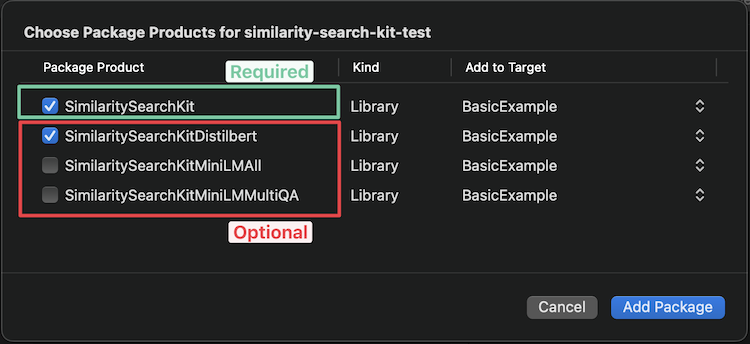
หากคุณต้องการเพิ่มผ่าน Package.swift ให้เพิ่มบรรทัดต่อไปนี้ในอาร์เรย์การพึ่งพาของคุณ:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )จากนั้นเพิ่มการพึ่งพาเป้าหมายที่เหมาะสมในเป้าหมายที่ต้องการ:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )หากคุณต้องการใช้ชุดย่อยของรุ่นที่มีอยู่เท่านั้นคุณสามารถละเว้นการพึ่งพาที่สอดคล้องกัน สิ่งนี้จะลดขนาดของไบนารีสุดท้ายของคุณ
หากต้องการใช้ความคล้ายคลึงกันในโครงการในโครงการของคุณก่อนนำเข้าเฟรมเวิร์ก:
import SimilaritySearchKitจากนั้นสร้างอินสแตนซ์ของ LamesInityIndex ด้วยตัวชี้วัดระยะทางที่คุณต้องการและโมเดลการฝัง (ดูด้านล่างสำหรับตัวเลือก):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)จากนั้นเพิ่มข้อความของคุณที่คุณต้องการค้นหาไปยังดัชนี:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)ในที่สุดสอบถามดัชนีสำหรับรายการที่คล้ายกันมากที่สุดกับแบบสอบถามที่กำหนด:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) ซึ่งส่งออกอาร์เรย์ SearchResult : [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
ไดเรกทอรี Examples มีแอปพลิเคชันตัวอย่าง iOS และ MACOS หลายตัวอย่างที่แสดงให้เห็นถึงวิธีการใช้ ความคล้ายคลึงกันของ SearchKit ในระดับที่สมบูรณ์ที่สุด
| ตัวอย่าง | คำอธิบาย | ความต้องการ |
|---|---|---|
BasicExample | แอปพลิเคชั่น Multiplatform พื้นฐานที่ดัชนีและเปรียบเทียบความคล้ายคลึงกันของชุดสตริง hardcoded ขนาดเล็ก | iOS 16.0+, macOS 13.0+ |
PDFExample | แอปพลิเคชัน MAC-catalyst ที่เปิดใช้งานการค้นหาความหมายเกี่ยวกับเนื้อหาของไฟล์ PDF แต่ละไฟล์ | iOS 16.0+ |
ChatWithFilesExample | แอปพลิเคชัน MacOS ขั้นสูงที่จัดทำดัชนีไฟล์ข้อความใด ๆ/ทั้งหมดบนคอมพิวเตอร์ของคุณ | macOS 13.0+ |
| แบบอย่าง | ใช้เคส | ขนาด | แหล่งที่มา |
|---|---|---|---|
NaturalLanguage | ข้อความที่คล้ายคลึงกันการอนุมานเร็วขึ้น | ในตัว | แอปเปิล |
MiniLMAll | ข้อความที่คล้ายคลึงกันการอนุมานที่เร็วที่สุด | 46 MB | กอด |
Distilbert | การค้นหาคำถามและคำตอบความแม่นยำสูงสุด | 86 MB (Quantized) | กอด |
MiniLMMultiQA | การค้นหาถาม - ตอบการอนุมานที่เร็วที่สุด | 46 MB | กอด |
โมเดลสอดคล้องกับ EmbeddingProtocol และสามารถใช้แทนกันได้กับคลาส SimilarityIndex
รายการขนาดเล็ก แต่กำลังเติบโตของโมเดลที่แปลงก่อนสามารถพบได้ใน repo นี้บน HuggingFace หากคุณมีโมเดลที่คุณต้องการดูเพิ่มลงในรายการโปรดเปิดปัญหาหรือส่งคำขอดึง
| ตัวชี้วัด | คำอธิบาย |
|---|---|
DotProduct | วัดความคล้ายคลึงกันระหว่างสองเวกเตอร์เป็นผลผลิตของขนาดของพวกเขา |
CosineSimilarity | คำนวณความคล้ายคลึงกันโดยการวัดโคไซน์ของมุมระหว่างสองเวกเตอร์ |
EuclideanDistance | คำนวณระยะทางเส้นตรงระหว่างสองจุดในพื้นที่ยุคลิด |
ตัวชี้วัดสอดคล้องกับ DistanceMetricProtocol และสามารถใช้แทนกันได้กับคลาส SimilarityIndex
ส่วนหลักทั้งหมดของ SimilarityIndex สามารถเอาชนะได้ด้วยการใช้งานที่กำหนดเองซึ่งสอดคล้องกับโปรโตคอลต่อไปนี้:
ยอมรับสตริงและส่งคืนอาร์เรย์ของลอยตัวแทนการฝังข้อความอินพุต
func encode ( sentence : String ) async -> [ Float ] ?ยอมรับเวกเตอร์ฝังคิวรีและรายการเวกเตอร์ฝังตัวและส่งคืน tuple ของคะแนนการวัดระยะทางและดัชนีของเพื่อนบ้านที่ใกล้ที่สุด
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]แยกสตริงออกเป็นชิ้นขนาดที่กำหนดด้วยการทับซ้อนที่กำหนด สิ่งนี้มีประโยชน์สำหรับการแยกเอกสารยาวออกเป็นชิ้นเล็ก ๆ สำหรับการฝัง มันส่งคืนรายการชิ้นส่วนและรายการเสริมของ tokensids สำหรับแต่ละก้อน
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )tokenizes และ detokenizes text ใช้สิ่งนี้สำหรับโมเดลที่กำหนดเองที่ใช้ tokenizers ที่แตกต่างกันมากกว่าที่มีอยู่ในรายการปัจจุบัน
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> Stringบันทึกและโหลดรายการดัชนี การใช้งานเริ่มต้นใช้ไฟล์ JSON แต่อาจเป็น overriden เพื่อใช้กลไกการจัดเก็บใด ๆ
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] หลายส่วนของโครงการนี้มาจากรหัสที่มีอยู่ไม่ว่าจะเป็น Swift หรือแปลเป็น Swift ขอบคุณ CHATGPT นี่คือโครงการหลักที่อ้างอิง:
โครงการนี้ได้รับแรงบันดาลใจจากความก้าวหน้าที่เหลือเชื่อในบริการภาษาธรรมชาติและแอพพลิเคชั่นที่เกิดขึ้นกับการเกิดขึ้นของ CHATGPT ในขณะที่บริการเหล่านี้ได้ปลดล็อคโลกใหม่ทั้งหมดของแอพพลิเคชั่นที่ใช้ข้อความที่ทรงพลัง แต่พวกเขามักจะพึ่งพาบริการคลาวด์ โดยเฉพาะบริการ "แชทกับข้อมูล" จำนวนมากทำให้ผู้ใช้ต้องอัปโหลดข้อมูลไปยังเซิร์ฟเวอร์ระยะไกลสำหรับการประมวลผลและการจัดเก็บ แม้ว่าสิ่งนี้จะใช้ได้กับบางคน แต่ก็อาจไม่เหมาะสมที่สุดสำหรับผู้ที่อยู่ในสภาพแวดล้อมการเชื่อมต่อต่ำหรือจัดการข้อมูลที่เป็นความลับหรือละเอียดอ่อน ในขณะที่ Apple มีการรวมห้องสมุด NaturalLanguage สำหรับงานที่คล้ายกันกระบวนการแปลงโมเดล Coreml เปิดขึ้นมาหลายรูปแบบและกรณีการใช้งานที่กว้างขึ้น ด้วยความคิดนี้ ความคล้ายคลึงกัน SearchKit จึงมีจุดมุ่งหมายเพื่อจัดหาโซลูชันที่แข็งแกร่งและมีอุปกรณ์ที่ช่วยให้นักพัฒนาสามารถสร้างแอพพลิเคชั่น NLP ที่ทันสมัยภายในระบบนิเวศของ Apple
นี่คือรายการสั้น ๆ ของคุณสมบัติบางอย่างที่วางแผนไว้สำหรับการเปิดตัวในอนาคต:
ฉันอยากรู้ว่าผู้คนใช้ห้องสมุดนี้อย่างไรและคุณสมบัติอื่น ๆ จะเป็นประโยชน์อย่างไรโปรดอย่าลังเลที่จะเข้าถึง Twitter @zachnagengast หรืออีเมล Znagengast (AT) Gmail (dot) com


