similarity search kit
0.0.15

Die Ähnlichkeitsforschung ist ein Swift-Paket , das Texteinbettungen und semantische Suchfunktionen für iOS- und macOS-Anwendungen in nur wenigen Zeilen ermöglicht. Es betont Geschwindigkeit, Erweiterbarkeit und Privatsphäre und unterstützt eine Vielzahl von NLP-Modellen und Ähnlichkeitsmetriken aufgebaut, zusätzlich zu einer nahtlosen Integration für die Möglichkeiten von Optionen.
Einige potenzielle Anwendungsfälle für die Ähnlichkeitswissenschaft sind:
Dokument-Suchmaschinen mit Datenschutzgründen: Erstellen Sie eine Suchmaschine, die sensible Dokumente lokal verarbeitet, ohne Benutzerdaten externer Dienste auszusetzen. (Siehe Beispielprojekt "chatwithFileSexample" im Beispielverzeichnis.)
Offline-Frage-Antworten-Systeme: Implementieren Sie ein Fragen-Antwortensystem, das die relevantesten Antworten auf die Abfrage eines Benutzers in einem lokalen Datensatz findet.
Dokumentclustering und Empfehlungsmotoren: Gruppen und organisieren Sie Dokumente automatisch auf der Grundlage ihrer Textinhalte am Rande.
Durch die Nutzung von Ähnlichkeitswissenschaften können Entwickler problemlos leistungsstarke Anwendungen erstellen, die die Daten ohne größere Kompromisse bei Funktionalität oder Leistung in der Nähe halten.
Um Ähnlichkeitswissenschaften zu installieren, fügen Sie es einfach als Abhängigkeit zu Ihrem Swift -Projekt mit dem Swift -Paket -Manager hinzu. Ich empfehle, die XCode -Methode persönlich zu verwenden:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode sollten Ihnen die folgenden Optionen geben, um auszuwählen, welches Modell Sie hinzufügen möchten (siehe die verfügbaren Modelle unten, um Hilfe zu wählen):
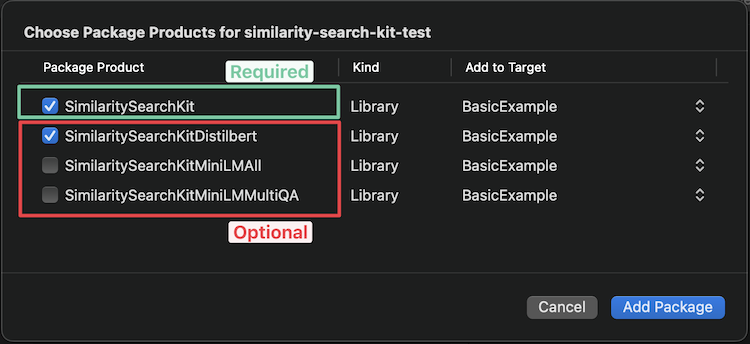
Wenn Sie es über Package.swift hinzufügen möchten, fügen Sie die folgende Zeile zu Ihrem Abhängigkeits -Array hinzu:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )Fügen Sie dann die entsprechende Zielabhängigkeit zum gewünschten Ziel hinzu:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )Wenn Sie nur eine Untergruppe der verfügbaren Modelle verwenden möchten, können Sie die entsprechende Abhängigkeit weglassen. Dies verringert die Größe Ihres endgültigen Binärs.
Importieren Sie das Framework zuerst, um die Ähnlichkeitswissenschaft in Ihrem Projekt zu verwenden:
import SimilaritySearchKitErstellen Sie als nächstes eine Instanz von Ähnlichkeitenindex mit Ihrer gewünschten Entfernungsmetrik und Einbettungsmodell (siehe unten für Optionen):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)Fügen Sie dann Ihren Text hinzu, den Sie in den Index durchsuchen möchten:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)Fragen Sie schließlich den Index für die ähnlichsten Elemente in eine bestimmte Abfrage ab:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results ) Dies gibt ein SearchResult -Array aus: [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
Das Examples -Verzeichnis enthält multiple Beispiele iOS- und macOS -Anwendungen, die demonstrieren, wie die Ähnlichkeitsforschung in vollem Umfang verwendet wird.
| Beispiel | Beschreibung | Anforderungen |
|---|---|---|
BasicExample | Eine grundlegende multiplattformige Anwendung, die die Ähnlichkeit eines kleinen Satzes hartcodierter Zeichenfolgen indiziert und vergleicht. | iOS 16.0+, macOS 13.0+ |
PDFExample | Eine Mac-Katalysator-Anwendung, die die semantische Suche nach dem Inhalt einzelner PDF-Dateien ermöglicht. | iOS 16.0+ |
ChatWithFilesExample | Eine erweiterte MacOS -Anwendung, die alle Textdateien auf Ihrem Computer indiziert. | macOS 13.0+ |
| Modell | Anwendungsfall | Größe | Quelle |
|---|---|---|---|
NaturalLanguage | Textähnlichkeit, schnellere Inferenz | Eingebaut | Apfel |
MiniLMAll | Textähnlichkeit, schnellste Inferenz | 46 MB | Umarmung |
Distilbert | Fragen und Antworten, höchste Genauigkeit | 86 MB (quantisiert) | Umarmung |
MiniLMMultiQA | Q & A -Suche, schnellste Schlussfolgerung | 46 MB | Umarmung |
Modelle entsprechen dem EmbeddingProtocol und können mit der SimilarityIndex -Klasse austauschbar verwendet werden.
Eine kleine, aber wachsende Liste vorkonvertierter Modelle finden Sie in diesem Repo auf Umarmung. Wenn Sie ein Modell haben, das Sie in der Liste hinzufügen möchten, öffnen Sie bitte ein Problem oder senden Sie eine Pull -Anfrage.
| Metrisch | Beschreibung |
|---|---|
DotProduct | Misst die Ähnlichkeit zwischen zwei Vektoren als Produkt ihrer Größen |
CosineSimilarity | Berechnet die Ähnlichkeit, indem er den Cosinus des Winkels zwischen zwei Vektoren misst |
EuclideanDistance | Berechnet den geraden Abstand zwischen zwei Punkten im euklidischen Raum |
Metriken entsprechen dem DistanceMetricProtocol und können mit der SimilarityIndex austauschbar verwendet werden.
Alle Hauptteile des SimilarityIndex können mit benutzerdefinierten Implementierungen überschrieben werden, die den folgenden Protokollen entsprechen:
Akzeptiert eine Zeichenfolge und gibt ein Array von Schwimmern zurück, die die Einbettung des Eingabetxtes darstellen.
func encode ( sentence : String ) async -> [ Float ] ?Akzeptiert einen Abfrage -Einbettungsvektor und eine Liste von Einbettungsvektoren und gibt ein Tupel der Entfernungsmetrik und des Index des nächsten Nachbarn zurück.
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]Teilt eine Schnur in Stücke einer bestimmten Größe mit einer bestimmten Überlappung. Dies ist nützlich, um lange Dokumente zum Einbetten in kleinere Stücke aufzuteilen. Es gibt die Liste der Stücke und eine optionale Liste der Tokensiden für jeden Stück zurück.
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )Tokenisiert und detokene Text. Verwenden Sie dies für benutzerdefinierte Modelle, die verschiedene Tokenizer verwenden, als in der aktuellen Liste verfügbar sind.
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> StringSpeichern und laden Indexelemente. Die Standardimplementierung verwendet JSON -Dateien. Dies kann jedoch überschrieben werden, um jeden Speichermechanismus zu verwenden.
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] Viele Teile dieses Projekts wurden aus dem vorhandenen Code entweder bereits in Swift oder dank Chatgpt in Swift übersetzt. Dies sind einige der Hauptprojekte, auf die verwiesen wurde:
Dieses Projekt wurde von den unglaublichen Fortschritten in Diensten und Anwendungen für natürliche Sprache inspiriert, die mit der Entstehung von ChatGPT entstanden sind. Während diese Dienste eine ganz neue Welt leistungsstarker textbasierter Anwendungen freigeschaltet haben, stützen sie sich häufig auf Cloud-Dienste. Insbesondere müssen Benutzer viele "Chat mit Daten" -Diensten erfordern, ihre Daten zur Verarbeitung und Speicherung auf Remote -Server hochzuladen. Obwohl dies für einige funktioniert, passt dies möglicherweise nicht für diejenigen in Umgebungen mit geringem Konnektivität oder mit vertraulichen oder sensiblen Informationen. Während Apple für ähnliche Aufgaben die Bibliothek NaturalLanguage gebündelt hat, eröffnet der COREML -Modellkonvertierungsprozess eine viel größere Reihe von Modellen und Anwendungsfällen. In diesem Sinne möchte EgyitySearchkit eine robuste Lösung für das Gerät bereitstellen, mit der Entwickler hochmoderne NLP-Anwendungen innerhalb des Apple-Ökosystems erstellen können.
Hier finden Sie eine kurze Liste einiger Funktionen, die für zukünftige Veröffentlichungen geplant sind:
Ich bin gespannt, wie die Leute diese Bibliothek verwenden und welche anderen Funktionen nützlich sind. Bitte zögern Sie nicht, über Twitter @zachnagengast oder eine E -Mail -Znagenengast (at) Gmail (DOT) com zu erreichen.


