similarity search kit
0.0.15

相似性SearchKit是一个Swift软件包,仅在几行中启用了iOS和MACOS应用程序的iOS和MACOS应用程序的语义搜索功能。强调速度,可扩展性和隐私性,它支持各种内置的最先进的NLP模型和相似性指标,此外,除了无缝的集成以供您实现自己的选择。
相似性搜索kit的一些潜在用例包括:
以隐私为重点的文档搜索引擎:创建一个在本地处理敏感文档的搜索引擎,而无需将用户数据暴露于外部服务。 (请参阅示例目录中的示例项目“ chatwithfilesexample”。)
离线问题撤离系统:实施一个问题避开系统,该系统在本地数据集中找到了用户查询的最相关答案。
文档群集和建议引擎:根据其边缘上的文本内容自动组织和组织文档。
通过利用相似性SearchKit ,开发人员可以轻松地创建强大的应用程序,以使数据保持在不在家里的情况下,而无需在功能或性能方面进行重大折衷。
要安装相似之处,只需使用Swift Package Manager将其添加为Swift项目的依赖项。我建议通过以下方式亲自使用Xcode方法:
File → Add Packages... → Search or Enter Package Url → https://github.com/ZachNagengast/similarity-search-kit.git
Xcode应该为您提供以下选项,以选择要添加的模型(请参见下面的可用模型以获取帮助选择):
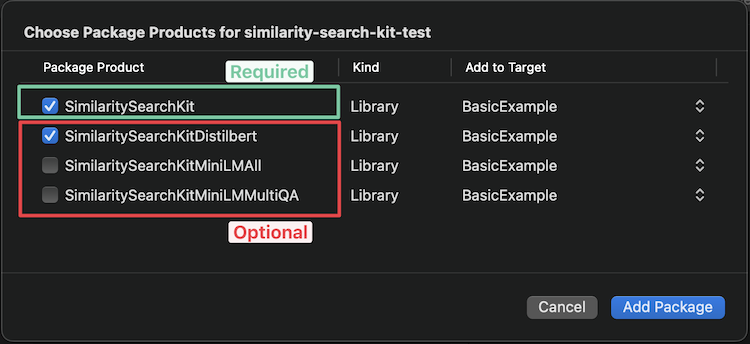
如果要通过Package.swift添加它,请在依赖项数组中添加以下行:
. package ( url : " https://github.com/ZachNagengast/similarity-search-kit.git " , from : " 0.0.1 " )然后,将适当的目标依赖性添加到所需的目标:
. target ( name : " YourTarget " , dependencies : [
" SimilaritySearchKit " ,
" SimilaritySearchKitDistilbert " ,
" SimilaritySearchKitMiniLMMultiQA " ,
" SimilaritySearchKitMiniLMAll "
] )如果您只想使用可用模型的子集,则可以省略相应的依赖关系。这将减少您最终二进制的大小。
要在您的项目中使用相似性搜索Kit,请首先导入框架:
import SimilaritySearchKit接下来,使用所需的距离度量和嵌入模型创建一个相似Index的实例(有关选项,请参见下文):
let similarityIndex = await SimilarityIndex (
model : NativeEmbeddings ( ) ,
metric : CosineSimilarity ( )
)然后,添加您要在索引中搜索的文本:
await similarityIndex . addItem (
id : " id1 " ,
text : " Metal was released in June 2014. " ,
metadata : [ " source " : " example.pdf " ]
)最后,查询与给定查询最相似项目的索引:
let results = await similarityIndex . search ( " When was metal released? " )
print ( results )输出一个搜索量数组: [SearchResult(id: "id1", score: 0.86216, metadata: ["source": "example.pdf"])]
这些Examples目录包含多个样本iOS和MACOS应用程序,这些应用程序演示了如何最大程度地使用相似之处。
| 例子 | 描述 | 要求 |
|---|---|---|
BasicExample | 一个基本的乘法应用程序,该应用程序索引并比较了一组硬编码字符串的相似性。 | iOS 16.0+,macOS 13.0+ |
PDFExample | MAC-Catalyst应用程序,可在单个PDF文件的内容上进行语义搜索。 | iOS 16.0+ |
ChatWithFilesExample | 高级MACOS应用程序,该应用程序索引计算机上的任何/所有文本文件。 | MacOS 13.0+ |
| 模型 | 用例 | 尺寸 | 来源 |
|---|---|---|---|
NaturalLanguage | 文字相似性,更快的推断 | 内置 | 苹果 |
MiniLMAll | 文字相似性,最快的推断 | 46 MB | 拥抱面 |
Distilbert | 问答搜索,准确性最高 | 86 MB(量化) | 拥抱面 |
MiniLMMultiQA | 问答搜索,最快的推理 | 46 MB | 拥抱面 |
模型符合EmbeddingProtocol ,并且可以与SimilarityIndex类互换使用。
在Huggingface上,可以在此存储库中找到一个少量但不断增长的预制模型列表。如果您有一个希望添加到列表中的模型,请打开问题或提交拉动请求。
| 公制 | 描述 |
|---|---|
DotProduct | 测量两个向量之间的相似性作为其幅度的乘积 |
CosineSimilarity | 通过测量两个向量之间的角度的余弦来计算相似性 |
EuclideanDistance | 计算欧几里得空间中两个点之间的直线距离 |
指标符合DistanceMetricProtocol ,并且可以与SimilarityIndex类别互换使用。
SimilarityIndex Index的所有主要部分都可以通过符合以下协议的自定义实现来覆盖:
接受一个字符串并返回代表输入文本嵌入的浮子数组。
func encode ( sentence : String ) async -> [ Float ] ?接受查询嵌入向量和嵌入量矢量列表,并返回距离度量评分的元组和最近邻居的索引。
func findNearest ( for queryEmbedding : [ Float ] , in neighborEmbeddings : [ [ Float ] ] , resultsCount : Int ) -> [ ( Float , Int ) ]将一根字符串分成给定尺寸的块,并具有给定的重叠。这对于将长文档分成较小的块以嵌入很有用。它返回了每个块的块列表和可选的tokensids列表。
func split ( text : String , chunkSize : Int , overlapSize : Int ) -> ( [ String ] , [ [ String ] ] ? )令牌和陈词滥调。将其用于使用与当前列表中可用的不同令牌的自定义模型。
func tokenize ( text : String ) -> [ String ]
func detokenize ( tokens : [ String ] ) -> String保存和加载索引项目。默认实现使用JSON文件,但是可以使用任何存储机制。
func saveIndex ( items : [ IndexItem ] , to url : URL , as name : String ) throws -> URL
func loadIndex ( from url : URL ) throws -> [ IndexItem ]
func listIndexes ( at url : URL ) -> [ URL ] 该项目的许多部分均来自现有代码(已经在迅速中,要么都转化为Swift,因此得益于Chatgpt。这些是引用的一些主要项目:
该项目的灵感来自于Chatgpt出现的自然语言服务和应用程序中令人难以置信的进步。尽管这些服务已经解锁了一个全新的基于文本的应用程序的全新世界,但它们通常依靠云服务。具体而言,许多“与数据聊天”服务需要用户将数据上传到远程服务器进行处理和存储。尽管这对某些人有用,但它可能并不适合低连通性环境中的人们,也不适合处理机密或敏感信息。尽管Apple确实捆绑了库的NaturalLanguage ,但Coreml模型转换过程开辟了许多模型和用例。考虑到这一点, SeplitySearchKit旨在提供一个可靠的,设备的解决方案,使开发人员能够在Apple生态系统中创建最新的NLP应用程序。
这是计划发布的一些功能的简短列表:
我很想知道人们如何使用此库以及其他哪些功能将是有用的,因此请随时通过Twitter @zachnagengast或电子邮件Znagengast(at)Gmail(dot)com伸出援手。


