electra_pytorch
1.0.0
非正式的Pytorch實施
Electra:訓練前文本編碼是凱文·克拉克(Kevin Clark)的歧視者而不是發電機。鐘長隆。 Quoc V. Le。克里斯托弗·D·曼寧
※對於將來的更新和更多工作,請遵循
我從頭開始預算電氣,並成功地將論文的結果復制在膠水上。
| 模型 | 可樂 | SST | MRPC | sts | QQP | mnli | Qnli | rte | avg。 avg。 |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| electra-small-owt(我) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
表1:膠水設置的結果。官方結果來自預期的結果。分數是從同一檢查點獲得冠心的平均得分。 (請參閱此問題)我的結果來自從頭開始的型號,並從每項任務的10個填充運行中平均進行。這兩個結果均在OpenWebText語料庫上進行培訓
| 模型 | 可樂 | SST | MRPC | sts | QQP | mnli | Qnli | rte | avg。 |
|---|---|---|---|---|---|---|---|---|---|
| electra-small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| electra-small ++(我) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
表2:膠測試集的結果。我的結果Finetunes從擁抱面上加載的經過驗證的檢查點。
| 官方訓練損失曲線 | 我的訓練損失曲線 |
|---|---|
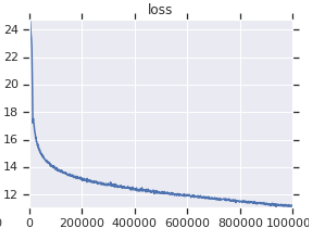 | 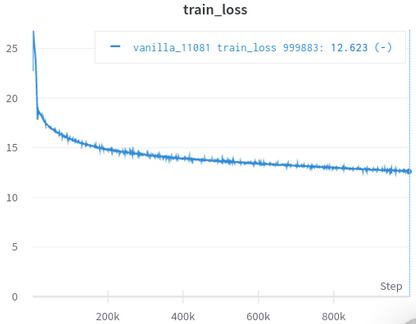 |
表3:兩者都是在OpenWebText上訓練的小型型號。官方是來自這裡的。您應該用一粒鹽的訓練損失價值,因為它不能反映下游任務的性能。
您無需手動下載和處理數據集,Scirpt會自動照顧您。 (感謝HuggingFace/DataSet和HugginFace/Transformers)
Afaik是最接近原始的重新成真,負責許多容易被忽視的細節(如下所述)。
阿法克(Afaik),唯一通過複製論文中的結果來成功驗證自己的人。
附帶Jupyter筆記本電腦,您可以探索代碼並檢查處理後的數據。
您無需獨自下載和預處理,您所需要的只是運行培訓腳本。
| 意思是 | std | 最大限度 | 最小 | #models |
|---|---|---|---|---|
| 81.38 | 0.57 | 82.23 | 80.42 | 14 |
tabel 4:小型模型的膠水開發結果的統計數據。每個模型都可以從頭開始鑑定,並對每個膠水任務進行10次隨機運行進行填充。模型的得分是每個任務最佳10的平均值。 (該過程與本文中描述的過程一樣),如我們所見,儘管Electra嘲笑Adeversarial訓練,但它具有良好的訓練穩定性。
| 模型 | 可樂 | SST | MRPC | sts | QQP | mnli | Qnli | rte |
|---|---|---|---|---|---|---|---|---|
| electra-small-owt(我) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0.15 | 0.33 | 1.93 |
表5:每個任務的標準偏差。這是與表1的模型相同的模型,該模型為每個任務運行10個。
擁抱面論壇帖子
Fastai論壇帖子
注意:這個項目實際上是用於我的個人研究。因此,我並沒有試圖使所有用戶易於使用,而是試圖使其易於閱讀和修改。
pip3 install -r requirements.txt
python pretrain.pyfinetune.py中將pretrained_checkcpoint設置為使用已預處理並保存在electra_pytorch/checkpoints/pretrain中的檢查點。python finetune.py ( do_finetune設置為True )finetune.py中設置th_runs 。python finetune.py (將do_finetune設置為False ),此預測測試集對testset上的預測,然後可以在electra_pytorch/test_outputs/<group_name>/*.tsv中壓縮並發送.tsv s,以獲得測試得分。 我沒有使用CLI參數,因此在運行Python文件中MyConfig中包含的選項以在運行之前。 (下面有評論顯示香草設置的選項)
您將需要一個Neptune帳戶,並在網站上創建一個Neptune項目,以記錄膠水固定結果。不要忘記用海王星項目的名稱代替richarddwang/electra-glue
python文件pretrain.py , finetune.py實際上是從Pretrain.ipynb和Finetune_GLUE.ipynb轉換的。您也可以使用這些筆記本探索Electra培訓和填充。
下面列出了原始實施/紙的詳細信息,這些詳細信息易於忽略,我已經照顧了。我發現這些細節是必不可少的,即可成功複製本文的結果。
ElectraClassificationHead黑頭使用。如果您預先預處理並產生測試結果。 electra_pytorch將為您生成這些。
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


