electra_pytorch
1.0.0
Implementasi pytorch tidak resmi
Electra: Encoder teks pra-pelatihan sebagai diskriminator daripada generator oleh Kevin Clark. Minh-Ther Luong. Quoc V. Le. Christopher D. Manning
※ Untuk pembaruan dan lebih banyak pekerjaan di masa depan, ikuti
Saya pretrain electra-small dari awal dan telah berhasil mereplikasi hasil kertas pada lem.
| Model | Cola | SST | Mrpc | STS | QQP | Mnli | Qnli | Rte | Rata -rata. dari rata -rata. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small-owt | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-small-owt (my) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
Tabel 1: Hasil pada set dev lem. Hasil resmi berasal dari hasil yang diharapkan. Skor adalah skor rata -rata finetuned dari pos pemeriksaan yang sama. (Lihat masalah ini) Hasil saya berasal dari pretraining model dari awal dan mereka mengambil rata -rata dari 10 run finetuning untuk setiap tugas. Kedua hasilnya dilatih di OpenWebtext Corpus
| Model | Cola | SST | Mrpc | STS | QQP | Mnli | Qnli | Rte | Rata -rata. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-Small ++ (My) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
Tabel 2: Hasil pada set tes lem. Hasil saya finetunes pos pemeriksaan pretrain dimuat dari permukaan pelukan.
| Kurva Kerugian Pelatihan Resmi | Kurva Kehilangan Pelatihan Saya |
|---|---|
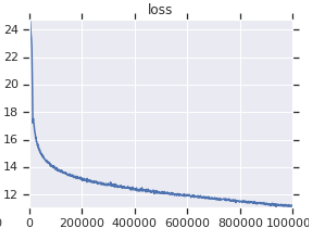 | 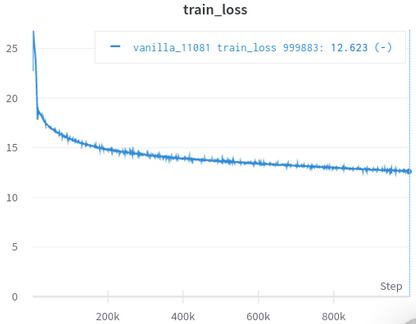 |
Tabel 3: Keduanya adalah model kecil yang dilatih di OpenWebText. Yang resmi adalah dari sini. Anda harus mengambil nilai kehilangan pelatihan dengan sebutir garam karena tidak mencerminkan kinerja tugas hilir.
Anda tidak perlu mengunduh dan memproses set data secara manual, scirpt merawatnya untuk Anda secara otomatis. (Terima kasih kepada HuggingFace/Datasets dan Hugginface/Transformers)
Afaik, penerapan ulang terdekat dengan yang asli, mengurus banyak detail yang mudah diabaikan (dijelaskan di bawah).
AFAIK, satu -satunya yang berhasil memvalidasi dirinya dengan mereplikasi hasil di koran.
Dilengkapi dengan Jupyter Notebooks, yang dapat Anda jelajahi kode dan periksa data yang diproses.
Anda tidak perlu mengunduh dan melakukan preprocess apa pun sendiri, yang Anda butuhkan hanyalah menjalankan skrip pelatihan.
| Berarti | Std | Max | Min | #models |
|---|---|---|---|---|
| 81.38 | 0,57 | 82.23 | 80.42 | 14 |
Tabel 4: Statistik hasil devset lem untuk model kecil. Setiap model pretrained dari awal dengan biji yang berbeda dan finetuned untuk 10 run acak untuk setiap tugas lem. Skor model adalah rata -rata 10 terbaik untuk setiap tugas. (Prosesnya sama dengan yang dijelaskan dalam makalah) seperti yang bisa kita lihat, meskipun Electra mengejek pelatihan adeversarial, ia memiliki stabilitas pelatihan yang baik.
| Model | Cola | SST | Mrpc | STS | QQP | Mnli | Qnli | Rte |
|---|---|---|---|---|---|---|---|---|
| Electra-small-owt (my) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0,15 | 0.33 | 1.93 |
Tabel 5: Deviasi standar untuk setiap tugas. Ini adalah model yang sama dengan Tabel 1, yang berjalan 10 tahun berjalan untuk setiap tugas.
Posting Forum Huggingface
Posting Forum Fastai
Catatan: Proyek ini sebenarnya untuk penelitian pribadi saya. Jadi saya tidak mencoba membuatnya mudah digunakan untuk semua pengguna, tetapi mencoba membuatnya mudah dibaca dan dimodifikasi.
pip3 install -r requirements.txt
python pretrain.pypretrained_checkcpoint di finetune.py untuk menggunakan pos pemeriksaan yang telah Anda pretrained dan simpan di electra_pytorch/checkpoints/pretrain .python finetune.py (dengan do_finetune diatur ke True )th_runs di finetune.py sesuai dengan angka -angka dalam nama run yang Anda pilih.python finetune.py (dengan do_finetune diatur ke False ), prediksi outpus ini pada testset, Anda kemudian dapat mengompres dan mengirim .tsv s di electra_pytorch/test_outputs/<group_name>/*.tsv untuk merekatkan situs untuk mendapatkan skor tes. Saya tidak menggunakan argumen CLI, jadi konfigurasikan opsi yang terlampir di dalam MyConfig di file Python sesuai kebutuhan Anda sebelum menjalankannya. (Ada komentar di bawah ini yang menunjukkan opsi untuk pengaturan vanilla)
Anda akan memerlukan akun Neptunus dan membuat proyek Neptunus di situs web untuk merekam hasil finetuning lem. Jangan lupa untuk menggantikan richarddwang/electra-glue dengan nama proyek Neptunus Anda
File Python pretrain.py , finetune.py sebenarnya dikonversi dari Pretrain.ipynb dan Finetune_GLUE.ipynb . Anda juga dapat menggunakan buku catatan itu untuk menjelajahi pelatihan elektra dan finetuning.
Di bawah ini mencantumkan detail implementasi/kertas asli yang mudah diabaikan dan saya telah mengurus. Saya menemukan detail ini sangat diperlukan untuk berhasil mereplikasi hasil kertas.
ElectraClassificationHead . Jika Anda pretrain, finetune, dan menghasilkan hasil tes. electra_pytorch akan menghasilkan ini untuk Anda.
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


