electra_pytorch
1.0.0
Implementación no oficial de Pytorch de
Electra: codificadores de texto previos al entrenamiento como discriminadores en lugar de generadores de Kevin Clark. Minh-Thang Luong. Quoc V. LE. Christopher D. Manning
※ Para actualizaciones y más trabajo en el futuro, siga
Pretran el electro-pequeña desde cero y he replicado con éxito los resultados del documento sobre el pegamento.
| Modelo | Reajuste salarial | SST | MRPC | Sts | QQP | Mnli | Qnli | RTE | Avg. de avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electro-pala | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-Small-Owt (my) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
Tabla 1: Resultados en el conjunto de desarrollo de pegamento. El resultado oficial proviene de los resultados esperados. Los puntajes son los puntajes promedio finetos desde el mismo punto de control. (Vea este problema) Mi resultado proviene de previamente un modelo desde cero y Thens tomando un promedio de 10 ejecuciones de finising para cada tarea. Ambos resultados están entrenados en OpenWebText Corpus
| Modelo | Reajuste salarial | SST | MRPC | Sts | QQP | Mnli | Qnli | RTE | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-Small ++ (my) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
Tabla 2: Resultados en el conjunto de pruebas de pegamento. Mi resultado Finetunes el punto de control preventivo cargado de Huggingface.
| Curva de pérdida de capacitación oficial | Mi curva de pérdida de entrenamiento |
|---|---|
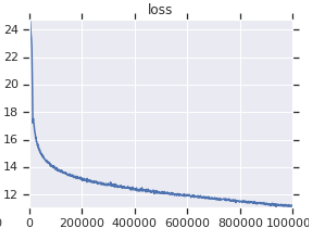 | 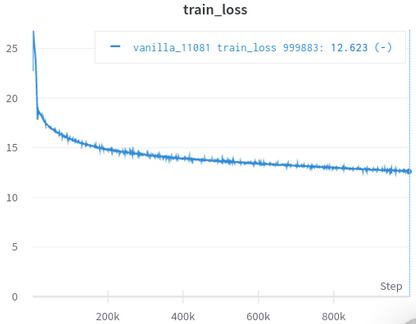 |
Tabla 3: Ambos son modelos pequeños entrenados en OpenWebText. El oficial es de aquí. Debe tomar el valor de la pérdida de entrenamiento con un grano de sal, ya que no refleja el rendimiento de las tareas aguas abajo.
No necesita descargar y procesar conjuntos de datos manualmente, el scIRPT cuidan los que se encuentran automáticamente. (Gracias a Huggingface/DataSets y Hugginface/Transformers)
AFAIK, la reimplementación más cercana al original, que se ocupa de muchos detalles fáciles de pasar por alto (descritos a continuación).
AFAIK, el único se valora con éxito replicando los resultados en el documento.
Viene con cuadernos Jupyter, que puede explorar el código e inspeccionar los datos procesados.
No necesita descargar y preprocesar nada por sí mismo, todo lo que necesita es ejecutar el script de entrenamiento.
| Significar | Std | Máximo | Mínimo | #modelos |
|---|---|---|---|---|
| 81.38 | 0.57 | 82.23 | 80.42 | 14 |
Tabel 4: Estadísticas de los resultados de Glue Devset para modelos pequeños. Cada modelo está previamente provocado desde cero con diferentes semillas y Finetuned para 10 ejecuciones aleatorias para cada tarea de pegamento. La puntuación de un modelo es el promedio de los mejores de 10 para cada tarea. (El proceso es lo mismo que el descrito en el documento) como podemos ver, aunque Electra se está burlando de la capacitación de Adeversarial, tiene una buena estabilidad de entrenamiento.
| Modelo | Reajuste salarial | SST | MRPC | Sts | QQP | Mnli | Qnli | RTE |
|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt (my) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0.15 | 0.33 | 1.93 |
Tabla 5: Desviación estándar para cada tarea. Este es el mismo modelo que la Tabla 1, que Finetunes 10 se ejecuta para cada tarea.
Publicación del foro de Huggingface
Publicación del foro de Fastai
Nota: Este proyecto es en realidad para mi investigación personal. Así que no traté de hacer que fuera fácil de usar para todos los usuarios, pero tratando de facilitar la lectura y modificación.
pip3 install -r requirements.txt
python pretrain.pypretrained_checkcpoint en finetune.py para usar el punto de control que ha pretrionado y guardado en electra_pytorch/checkpoints/pretrain .python finetune.py (con do_finetune establecido en True )th_runs en finetune.py de acuerdo con los números en los nombres de las ejecuciones que eligió.python finetune.py (con do_finetune establecido en False ), este OUTPUS predicción en TestSet, puede comprimir y enviar .tsv s en electra_pytorch/test_outputs/<group_name>/*.tsv para el sitio de pegamento para obtener la puntuación de prueba. No utilicé argumentos CLI, así que configure las opciones adjuntas dentro de MyConfig en los archivos de Python a sus necesidades antes de ejecutarlas. (Hay comentarios a continuación que muestran las opciones para la configuración de vainilla)
Necesitará una cuenta de Neptuno y creará un proyecto de Neptuno en el sitio web para registrar resultados de finete de pegamento. No olvide reemplazar richarddwang/electra-glue con el nombre de su proyecto Neptuno
Los archivos de Python pretrain.py , finetune.py se convierten de Pretrain.ipynb y Finetune_GLUE.ipynb . También puede usar esos cuadernos para explorar la capacitación de electra y la finura.
A continuación enumera los detalles de la implementación/documento original que son fáciles de pasar por alto y me he encargado. Encontré que estos detalles son indispensables para replicar con éxito los resultados del documento.
ElectraClassificationHead . Si se envía previamente, finetune y genera resultados de las pruebas. electra_pytorch generará estos para usted.
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


