electra_pytorch
1.0.0
비공식 Pytorch 구현
Electra : Kevin Clark의 발전기보다는 판별 자로 사전 훈련 텍스트 인코더. Minh-Thang Luong. Quoc V. Le. 크리스토퍼 D. 매닝
∎ 향후 업데이트 및 더 많은 작업은 다음과 같습니다.
나는 전기를 처음부터 사전에 전파하고 접착제에서 종이의 결과를 성공적으로 복제했다.
| 모델 | 콜라 | SST | MRPC | STS | QQP | mnli | qnli | RTE | avg. AVG. |
|---|---|---|---|---|---|---|---|---|---|
| 전자-매일-우트 | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-Small-owt (내) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
표 1 : 접착제 개발자 세트의 결과. 공식 결과는 예상 결과에서 비롯됩니다. 점수는 동일한 체크 포인트에서 미세한 평균 점수입니다. (이 문제 참조) 내 결과는 모델을 처음부터 사전 배치하고 각 작업에 대해 10 개의 미세 조정 실행에서 평균을 얻는 것입니다. 두 결과 모두 OpenWebText 코퍼스에서 교육을받습니다
| 모델 | 콜라 | SST | MRPC | STS | QQP | mnli | qnli | RTE | avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-Small ++ (내) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
표 2 : 접착제 테스트 세트의 결과. 내 결과는 Huggingface에서로드 된 사전 체크 포인트를 미세합니다.
| 공식 교육 손실 곡선 | 내 훈련 손실 곡선 |
|---|---|
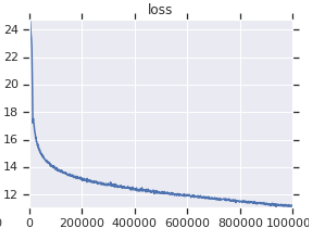 | 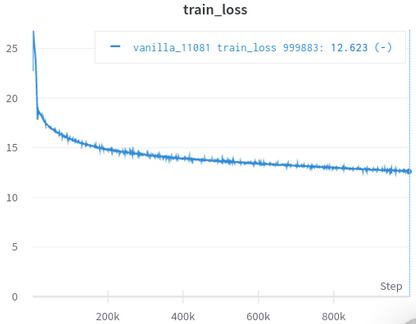 |
표 3 : 둘 다 OpenWebText에서 훈련 된 작은 모델입니다. 공식적인 것이 여기에서 왔습니다. 다운 스트림 작업의 성능을 반영하지 않기 때문에 소금 한 알로 훈련 손실의 가치를 취해야합니다.
데이터 세트를 수동으로 다운로드하여 처리 할 필요가 없으며 SCIRPT는 자동으로 귀하를 위해 관리합니다. (Huggingface/DataSets 및 Hugginface/Transformers에 감사합니다)
원래의 것과 가장 가까운 상환 인 Afaik은 쉽게 간과되는 많은 세부 사항을 처리합니다 (아래 설명).
유일한 사람은 논문에서 결과를 복제하여 스스로를 성공적으로 검증합니다.
Jupyter Notebooks와 함께 제공되어 코드를 탐색하고 처리 된 데이터를 검사 할 수 있습니다.
스스로 다운로드하여 전처리 할 필요가 없습니다. 필요한 것은 훈련 스크립트를 실행하는 것입니다.
| 평균 | std | 맥스 | 최소 | #모델 |
|---|---|---|---|---|
| 81.38 | 0.57 | 82.23 | 80.42 | 14 |
Tabel 4 : 작은 모델의 접착제 개발 결과. 모든 모델은 서로 다른 씨앗으로 처음부터 사전에 사귀고 각 접착제 작업에 대해 10 개의 임의의 실행을 위해 미세 조정됩니다. 모델의 점수는 각 작업에 대해 최고 10의 평균입니다. (이 과정은 논문에 설명 된 과정과 동일합니다) 우리가 볼 수 있듯이 Electra는 Adeversarial 훈련을 조롱하고 있지만, 훈련 안정성이 우수합니다.
| 모델 | 콜라 | SST | MRPC | STS | QQP | mnli | qnli | RTE |
|---|---|---|---|---|---|---|---|---|
| Electra-Small-owt (내) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0.15 | 0.33 | 1.93 |
표 5 : 각 작업에 대한 표준 편차. 이 모델은 표 1과 동일한 모델이며, 각 작업에 대해 10이 실행됩니다.
Huggingface 포럼 게시물
Fastai Forum Post
참고 :이 프로젝트는 실제로 개인 연구를위한 것입니다. 그래서 나는 모든 사용자에게 사용하기 쉽도록 노력하지 않았지만 읽고 수정하기 쉽게 만들려고 노력했습니다.
pip3 install -r requirements.txt
python pretrain.pyelectra_pytorch/checkpoints/pretrain 에 사전에 사기 및 저장된 체크 포인트를 사용하려면 finetune.py 에서 pretrained_checkcpoint 설정하십시오.python finetune.py ( do_finetune 이 True 로 설정)finetune.py 에서 th_runs 설정하십시오.python finetune.py ( do_finetune 이 False 로 설정된 경우),이 아웃 푸스 예측은 테스트 세트에서 압축하여 .tsv s를 압축하여 electra_pytorch/test_outputs/<group_name>/*.tsv CLI 인수를 사용하지 않았으므로 Python 파일의 MyConfig 내에 포함 된 옵션을 실행하기 전에 귀하의 요구에 맞게 구성하십시오. (바닐라 설정 옵션을 보여주는 아래에 의견이 있습니다)
해왕성 계정이 필요하고 웹 사이트에 해왕성 프로젝트를 만들어 접착제 결합 결과를 기록합니다. richarddwang/electra-glue 해왕성 프로젝트 이름으로 바꾸는 것을 잊지 마십시오.
Python 파일 pretrain.py , finetune.py 는 실제로 Pretrain.ipynb 및 Finetune_GLUE.ipynb 에서 변환됩니다. 해당 노트북을 사용하여 Electra Training 및 Finetuning을 탐색 할 수도 있습니다.
아래에는 간과하기 쉬우 며 내가 처리 한 원래 구현/용지의 세부 사항을 나열합니다. 이 세부 사항은 논문의 결과를 성공적으로 복제 할 수 없다는 것을 알았습니다.
ElectraClassificationHead 사용하는 것이 아니라. 예방주의 경우, 미세 및 테스트 결과를 생성하는 경우. electra_pytorch 가이를 생성합니다.
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


