electra_pytorch
1.0.0
Inoffizielle Pytorch -Implementierung von
Electra: Textcodierer vor dem Training eher als Diskriminatoren als Generatoren von Kevin Clark. Minh-Thang Luong. Quoc V. Le. Christopher D. Manning
※ Folgen Sie für Updates und weitere Arbeiten in der Zukunft
Ich habe Electra-Small von Grund auf neu und habe die Ergebnisse des Papiers auf Kleber erfolgreich repliziert.
| Modell | Cola | Sst | MRPC | Sts | QQP | Mnli | Qnli | Rte | Avg. von avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt | 56,8 | 88.3 | 87,4 | 86,8 | 88.3 | 78,9 | 87,9 | 68,5 | 80.36 |
| Electra-Small-Owt (mein) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87,45 | 67,46 | 80.36 |
Tabelle 1: Ergebnisse am Kleber -Dev -Set. Das offizielle Ergebnis ergibt sich aus den erwarteten Ergebnissen. Die Bewertungen sind die durchschnittlichen Punktzahlen, die aus demselben Kontrollpunkt abgeschlossen sind. (Siehe dieses Problem) Mein Ergebnis kommt von der Vorbereitung eines Modells von Grund auf und nimmt für jede Aufgabe den Durchschnitt von 10 Finetuning -Läufen. Beide Ergebnisse werden auf OpenWebtext Corpus trainiert
| Modell | Cola | Sst | MRPC | Sts | QQP | Mnli | Qnli | Rte | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79,7 |
| Electra-Small ++ (mein) | 54,8 | 91.6 | 84.6 | 84.2 | 88,5 | 82 | 89 | 64.7 | 79,92 |
Tabelle 2: Ergebnisse beim Klebetestsatz. Mein Ergebnis finanziert den vorgenannten Checkpoint, der vom Umarmungsface geladen wurde.
| Offizielle Ausbildungsverlustkurve | Meine Trainingsverlustkurve |
|---|---|
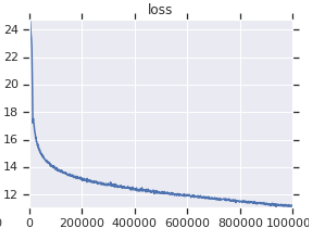 | 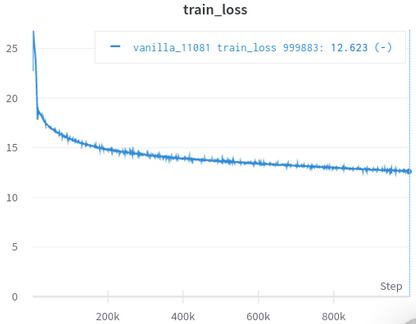 |
Tabelle 3: Beide sind kleine Modelle, die auf OpenWebtext trainiert wurden. Der Beamte ist von hier. Sie sollten den Wert des Trainingsverlusts mit einem Salzkorn nehmen, da es die Leistung von nachgeschalteten Aufgaben nicht widerspiegelt.
Sie müssen Datensätze nicht manuell herunterladen und verarbeiten, die Scirpt achten diese für Sie automatisch. (Dank an Huggingface/Datensätze und Hugginface/Transformers)
AFAIK, die engste Neuauflagen für die ursprüngliche, kümmert sich um viele leicht übersehene Details (unten beschrieben).
Afaik, der einzige, validiert sich erfolgreich, indem er die Ergebnisse im Papier repliziert.
Kommt mit Jupyter -Notizbüchern, mit denen Sie den Code untersuchen und die verarbeiteten Daten inspizieren können.
Sie müssen nichts selbst herunterladen und vorbereiten. Alles, was Sie brauchen, ist, das Trainingsskript auszuführen.
| Bedeuten | Std | Max | Min | #models |
|---|---|---|---|---|
| 81.38 | 0,57 | 82.23 | 80.42 | 14 |
Tafel 4: Statistiken der Kleberdeteergebnisse für kleine Modelle. Jedes Modell wird von Grund auf mit unterschiedlichen Samen vorbereitet und für 10 zufällige Läufe für jede Kleberaufgabe finationstuniert. Die Punktzahl eines Modells ist der Durchschnitt der besten von 10 für jede Aufgabe. (Der Prozess ist genauso wie der im Papier beschriebene.) Wie wir sehen können, verspottet Electra eine gute Trainingsstabilität.
| Modell | Cola | Sst | MRPC | Sts | QQP | Mnli | Qnli | Rte |
|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt (mein) | 1.30 | 0,49 | 0,7 | 0,29 | 0,1 | 0,15 | 0,33 | 1.93 |
Tabelle 5: Standardabweichung für jede Aufgabe. Dies ist das gleiche Modell wie Tabelle 1, die für jede Aufgabe Fünfe 10 läuft.
Umarmungsface Forum Post
Fastai Forum Post
Hinweis: Dieses Projekt ist eigentlich für meine persönliche Forschung. Ich habe also nicht versucht, für alle Benutzer zu bedienen, aber es einfach zu lesen und zu ändern.
pip3 install -r requirements.txt
python pretrain.pypretrained_checkcpoint in finetune.py vorab electra_pytorch/checkpoints/pretrainpython finetune.py (mit do_finetune auf True )th_runs in finetune.py gemäß den Zahlen in den Namen der von Ihnen ausgewählten Läufe ein.python finetune.py (mit do_finetune auf False ), diese Outpus -Vorhersagen auf Testset können Sie dann komprimieren und .tsv S in electra_pytorch/test_outputs/<group_name>/*.tsv . Ich habe keine CLI -Argumente verwendet. Konfigurieren Sie also Optionen, die in MyConfig in den Python -Dateien auf Ihre Anforderungen eingeschlossen sind, bevor Sie sie ausführen. (Darunter finden Sie die Optionen für Vanilleeinstellungen.)
Sie benötigen ein Neptune -Konto und erstellen ein Neptune -Projekt auf der Website, um die Ergebnisse der Kleberfinetunierung aufzuzeichnen. Vergessen Sie nicht richarddwang/electra-glue durch den Namen Ihres Neptune-Projekts zu ersetzen
Die Python -Dateien pretrain.py , finetune.py werden tatsächlich von Pretrain.ipynb und Finetune_GLUE.ipynb konvertiert. Sie können diese Notizbücher auch verwenden, um Electra -Training und -Feckern zu erkunden.
Im Folgenden sind die Details der ursprünglichen Implementierung/des ursprünglichen Papiers aufgeführt, die leicht übersehen werden können, und ich habe mich darum gekümmert. Ich fand, dass diese Details unverzichtbar sind, um die Ergebnisse des Papiers erfolgreich zu replizieren.
ElectraClassificationHead verwendet. Wenn Sie vorbereitet, Figune und Testergebnisse erstellen. electra_pytorch erzeugt diese für Sie.
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


