electra_pytorch
1.0.0
การใช้งาน pytorch อย่างไม่เป็นทางการของ
Electra: การเข้ารหัสข้อความก่อนการฝึกอบรมในฐานะผู้จำแนกมากกว่าเครื่องกำเนิดไฟฟ้าโดยเควินคลาร์ก Minh-Thang Luong QUOC V. Le. Christopher D. Manning
※สำหรับการอัปเดตและงานเพิ่มเติมในอนาคตติดตาม
ฉัน pretrain electra-small ตั้งแต่เริ่มต้นและทำซ้ำผลลัพธ์ของกระดาษบนกาวได้สำเร็จ
| แบบอย่าง | โคล่า | SST | MRPC | STS | qqp | mnli | qnli | rte | avg. ของ avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-small-owt | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-small-owt (ฉัน) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
ตารางที่ 1: ผลลัพธ์เกี่ยวกับชุดกาว Dev ผลลัพธ์อย่างเป็นทางการมาจากผลลัพธ์ที่คาดหวัง คะแนนคือคะแนนเฉลี่ยที่ได้รับจากจุดตรวจสอบเดียวกัน (ดูปัญหานี้) ผลลัพธ์ของฉันมาจากการเตรียมโมเดลตั้งแต่เริ่มต้นและการใช้ค่าเฉลี่ยจาก 10 finetuning ทำงานสำหรับแต่ละงาน ผลลัพธ์ทั้งสองได้รับการฝึกฝนในคลังโอเพนเวบเทท
| แบบอย่าง | โคล่า | SST | MRPC | STS | qqp | mnli | qnli | rte | avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-Small ++ (ฉัน) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
ตารางที่ 2: ผลลัพธ์เกี่ยวกับชุดทดสอบกาว ผลลัพธ์ของฉัน finetunes จุดตรวจสอบที่ถูกเตรียมไว้จาก HuggingFace
| เส้นโค้งการสูญเสียการฝึกอบรมอย่างเป็นทางการ | เส้นโค้งการสูญเสียการฝึกอบรมของฉัน |
|---|---|
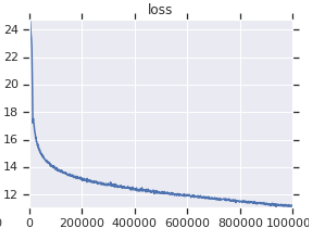 | 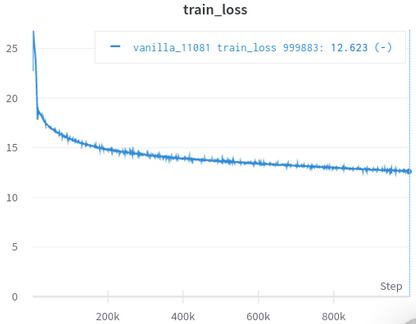 |
ตารางที่ 3: ทั้งคู่เป็นรุ่นเล็กที่ได้รับการฝึกฝนบน OpenWebText อย่างเป็นทางการมาจากที่นี่ คุณควรใช้คุณค่าของการสูญเสียการฝึกอบรมด้วยเม็ดเกลือเนื่องจากไม่ได้สะท้อนถึงประสิทธิภาพของงานดาวน์สตรีม
คุณไม่จำเป็นต้องดาวน์โหลดและประมวลผลชุดข้อมูลด้วยตนเอง Scirpt จะดูแลผู้ที่คุณดูแลโดยอัตโนมัติ (ขอบคุณ HuggingFace/ชุดข้อมูลและ Hugginface/Transformers)
AFAIK การพิจารณาใหม่ที่ใกล้เคียงที่สุดกับต้นฉบับการดูแลรายละเอียดที่มองข้ามได้ง่ายจำนวนมาก (อธิบายไว้ด้านล่าง)
Afaik ผู้เดียวที่ประสบความสำเร็จตรวจสอบตัวเองโดยการจำลองผลลัพธ์ในกระดาษ
มาพร้อมกับสมุดบันทึก Jupyter ซึ่งคุณสามารถสำรวจรหัสและตรวจสอบข้อมูลที่ประมวลผล
คุณไม่จำเป็นต้องดาวน์โหลดและประมวลผลอะไรด้วยตัวเองล่วงหน้าสิ่งที่คุณต้องการคือเรียกใช้สคริปต์การฝึกอบรม
| หมายถึง | STD | สูงสุด | นาที | #โมเดล |
|---|---|---|---|---|
| 81.38 | 0.57 | 82.23 | 80.42 | 14 |
Tabel 4: สถิติของผลการพัฒนากาวสำหรับรุ่นขนาดเล็ก ทุกรุ่นได้รับการปรับสภาพตั้งแต่เริ่มต้นด้วยเมล็ดที่แตกต่างกันและ finetuned สำหรับการวิ่งแบบสุ่ม 10 ครั้งสำหรับงานกาวแต่ละงาน คะแนนของแบบจำลองคือค่าเฉลี่ยที่ดีที่สุดของ 10 สำหรับแต่ละงาน (กระบวนการนี้เหมือนกับที่อธิบายไว้ในกระดาษ) อย่างที่เราเห็นแม้ว่า Electra กำลังเยาะเย้ยการฝึกอบรม adeversarial แต่ก็มีความมั่นคงในการฝึกอบรมที่ดี
| แบบอย่าง | โคล่า | SST | MRPC | STS | qqp | mnli | qnli | rte |
|---|---|---|---|---|---|---|---|---|
| Electra-small-owt (ฉัน) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0.15 | 0.33 | 1.93 |
ตารางที่ 5: ค่าเบี่ยงเบนมาตรฐานสำหรับแต่ละงาน นี่เป็นรุ่นเดียวกับตารางที่ 1 ซึ่ง Finetunes 10 ทำงานสำหรับแต่ละงาน
โพสต์ฟอรัม HuggingFace
โพสต์ฟอรัม Fastai
หมายเหตุ: โครงการนี้มีไว้สำหรับการวิจัยส่วนตัวของฉัน ดังนั้นฉันไม่ได้พยายามทำให้ง่ายต่อการใช้งานสำหรับผู้ใช้ทุกคน แต่พยายามทำให้ง่ายต่อการอ่านและแก้ไข
pip3 install -r requirements.txt
python pretrain.pypretrained_checkcpoint ใน finetune.py เพื่อใช้จุดตรวจสอบที่คุณเคยทำไว้และบันทึกไว้ใน electra_pytorch/checkpoints/pretrainpython finetune.py (ด้วย do_finetune ตั้งค่าเป็น True )th_runs ใน finetune.py ตามตัวเลขในชื่อของการวิ่งที่คุณเลือกpython finetune.py (ด้วย do_finetune ตั้งค่าเป็น False ) การทำนาย Outpus นี้ในชุดทดสอบคุณสามารถบีบอัดและส่ง .tsv s ใน electra_pytorch/test_outputs/<group_name>/*.tsv ไปยังไซต์กาวเพื่อรับคะแนนการทดสอบ ฉันไม่ได้ใช้อาร์กิวเมนต์ CLI ดังนั้นกำหนดค่าตัวเลือกที่อยู่ใน MyConfig ในไฟล์ Python ตามความต้องการของคุณก่อนที่จะเรียกใช้ (มีความคิดเห็นด้านล่างแสดงตัวเลือกสำหรับการตั้งค่าวานิลลา)
คุณจะต้องมีบัญชีดาวเนปจูนและสร้างโครงการเนปจูนบนเว็บไซต์เพื่อบันทึกผลลัพธ์กาว Finetuning อย่าลืมแทนที่ richarddwang/electra-glue ด้วยชื่อโครงการเนปจูนของคุณ
ไฟล์ Python pretrain.py , finetune.py ในความเป็นจริงแปลงจาก Pretrain.ipynb และ Finetune_GLUE.ipynb นอกจากนี้คุณยังสามารถใช้สมุดบันทึกเหล่านั้นเพื่อสำรวจการฝึกอบรม Electra และ Finetuning
ด้านล่างแสดงรายละเอียดของการใช้งาน/กระดาษดั้งเดิมที่มองข้ามได้ง่ายและฉันได้รับการดูแล ฉันพบว่ารายละเอียดเหล่านี้ขาดไม่ได้ในการทำซ้ำผลลัพธ์ของกระดาษ
ElectraClassificationHead Head ใช้ หากคุณ pretrain ให้ finetune และสร้างผลการทดสอบ electra_pytorch จะสร้างสิ่งเหล่านี้ให้คุณ
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


