electra_pytorch
1.0.0
Implementação não oficial de Pytorch de
Electra: codificadores de texto pré-treinamento como discriminadores, em vez de geradores de Kevin Clark. Minh-Thang Luong. Quoc V. Le. Christopher D. Manning
※ Para atualizações e mais trabalho no futuro, siga
Eu pré-atreso Electra-Small do zero e repliquei com sucesso os resultados do papel em cola.
| Modelo | Cola | SST | Mrpc | Sts | Qqp | Mnli | Qnli | Rte | Avg. de avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-small-owt | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-small-owt (meu) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
Tabela 1: Resultados no conjunto de dev cola. O resultado oficial vem dos resultados esperados. As pontuações são as pontuações médias do FinetUned do mesmo ponto de verificação. (Veja esta questão) Meu resultado vem de pré -treinar um modelo do zero e tenhas assumindo a média de 10 execuções de Finetuning para cada tarefa. Ambos os resultados são treinados no OpenWebtext Corpus
| Modelo | Cola | SST | Mrpc | Sts | Qqp | Mnli | Qnli | Rte | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-small ++ (meu) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
Tabela 2: Resultados no conjunto de testes de cola. Meu resultado fino, o ponto de verificação pré -treinado carregado do huggingface.
| Curva de perda de treinamento oficial | Minha curva de perda de treinamento |
|---|---|
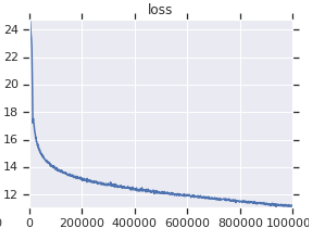 | 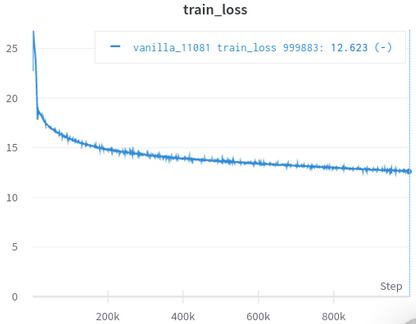 |
Tabela 3: Ambos são pequenos modelos treinados no OpenWebtext. O oficial é daqui. Você deve obter o valor da perda de treinamento com um grão de sal, pois isso não reflete o desempenho das tarefas a jusante.
Você não precisa baixar e processar os conjuntos de dados manualmente, o Scirpt cuida daqueles para você automaticamente. (Graças a Huggingface/DataSets e Hugginface/Transformers)
Afaik, a reimplementação mais próxima do original, cuidando de muitos detalhes facilmente esquecidos (descritos abaixo).
Afaik, o único valida com sucesso replicando os resultados no artigo.
Vem com notebooks Jupyter, que você pode explorar o código e inspecionar os dados processados.
Você não precisa baixar e pré -processar nada sozinho, tudo o que você precisa é executar o script de treinamento.
| Significar | Std | Máx | Min | #Models |
|---|---|---|---|---|
| 81.38 | 0,57 | 82.23 | 80.42 | 14 |
Tabel 4: Estatísticas dos resultados do Devset de cola para modelos pequenos. Todo modelo é pré -treinado do zero com sementes diferentes e FinetUned para 10 execuções aleatórias para cada tarefa de cola. A pontuação de um modelo é a média do melhor de 10 para cada tarefa. (O processo é o mesmo que o descrito no artigo), como podemos ver, embora a Electra esteja zombando do treinamento da AdeasTeSarial, ele tem uma boa estabilidade de treinamento.
| Modelo | Cola | SST | Mrpc | Sts | Qqp | Mnli | Qnli | Rte |
|---|---|---|---|---|---|---|---|---|
| Electra-small-owt (meu) | 1,30 | 0,49 | 0,7 | 0,29 | 0.1 | 0,15 | 0,33 | 1.93 |
Tabela 5: Desvio padrão para cada tarefa. Este é o mesmo modelo da Tabela 1, que Finetunes 10 executa para cada tarefa.
Postagem do Fórum de Huggingface
Postagem do fórum fastai
Nota: Este projeto é realmente para minha pesquisa pessoal. Por isso, não tentei facilitar o uso de todos os usuários, mas tentando facilitar a leitura e a modificação.
pip3 install -r requirements.txt
python pretrain.pypretrained_checkcpoint em finetune.py para usar o ponto de verificação que você pré -criou e salvo em electra_pytorch/checkpoints/pretrain .python finetune.py (com do_finetune definido como True )th_runs no finetune.py de acordo com os números nos nomes das execuções que você escolheu.python finetune.py (com do_finetune definido como False ), este outpus previsões no teste de teste, você pode comprimir e enviar .tsv s em electra_pytorch/test_outputs/<group_name>/*.tsv para colar o site para obter a pontuação do teste. Não usei argumentos da CLI; portanto, configure as opções fechadas no MyConfig nos arquivos Python para suas necessidades antes de executá -las. (Existem comentários abaixo, mostrando as opções para configurações de baunilha)
Você precisará de uma conta Neptune e criará um projeto Neptune no site para registrar os resultados da cola do Finetuning. Não se esqueça de substituir richarddwang/electra-glue pelo nome do seu projeto Netuno
Os arquivos python pretrain.py , finetune.py são de fato convertidos de Pretrain.ipynb e Finetune_GLUE.ipynb . Você também pode usar esses notebooks para explorar o treinamento e o Finetuning.
Abaixo, lista os detalhes da implementação/artigo original que são fáceis de serem negligenciados e eu cuidei. Descobri que esses detalhes são indispensáveis para replicar com sucesso os resultados do artigo.
ElectraClassificationHead usa. Se você pré -atrelar, Finetune e gerar resultados de testes. electra_pytorch os gerará para você.
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


