electra_pytorch
1.0.0
Mise en œuvre non officielle de pytorch de
Electra: Encodeurs de texte pré-formation comme discriminateurs plutôt que générateurs de Kevin Clark. Minh-Thang Luong. Quoc V. Le. Christopher D. Manning
※ Pour les mises à jour et plus de travail à l'avenir, suivez
J'ai pré-rompre Electra-Small à partir de zéro et j'ai réussi à reproduire les résultats du papier sur la colle.
| Modèle | Cola | SST | MRPC | STS | QQP | MNLI | QNLI | Rte | Avg. d'Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-Small-Owt (MOS) | 58,72 | 88.03 | 86.04 | 86.16 | 88,63 | 80.4 | 87.45 | 67.46 | 80.36 |
Tableau 1: Résultats sur le jeu de développement de colle. Le résultat officiel provient des résultats attendus. Les scores sont les scores moyens fineturés du même point de contrôle. (Voir ce problème) Mon résultat provient de la pré-entraînement d'un modèle à partir de zéro et de la moyenne de 10 exécutions de finetun pour chaque tâche. Les deux résultats sont formés sur le corpus OpenWebText
| Modèle | Cola | SST | MRPC | STS | QQP | MNLI | QNLI | Rte | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-Small ++ (MOS) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
Tableau 2: Résultats sur l'ensemble de tests de colle. Mon résultat finet le point de contrôle pré-entraîné chargé de Huggingface.
| Courbe officielle de perte de formation | Ma courbe de perte de formation |
|---|---|
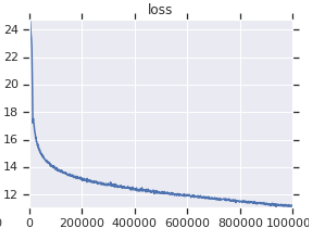 | 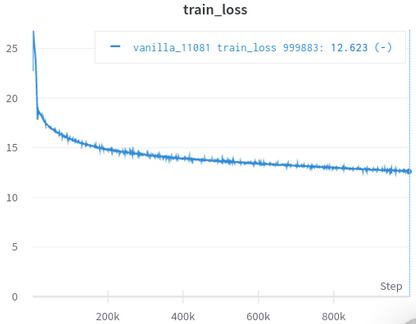 |
Tableau 3: Les deux sont de petits modèles formés sur OpenWebText. Le officiel est d'ici. Vous devez prendre la valeur de la perte de formation avec un grain de sel car il ne reflète pas les performances des tâches en aval.
Vous n'avez pas besoin de télécharger et de traiter les ensembles de données manuellement, le SCIRPT les prennent soin automatiquement. (Merci à HuggingFace / DataSets et Hugginface / Transformers)
Afaik, la réimplémentation la plus proche de celle d'origine, en prenant soin de nombreux détails facilement négligés (décrits ci-dessous).
Afaik, le seul à se valider avec succès en reproduisant les résultats dans l'article.
Livré avec Jupyter Notebooks, que vous pouvez explorer le code et inspecter les données traitées.
Vous n'avez pas besoin de télécharger et de prétraiter quoi que ce soit par vous-même, tout ce dont vous avez besoin est d'exécuter le script d'entraînement.
| Signifier | MST | Max | Min | #models |
|---|---|---|---|---|
| 81.38 | 0,57 | 82.23 | 80.42 | 14 |
Tabel 4: Statistiques des résultats des développeurs de colle pour les petits modèles. Chaque modèle est pré-entraîné à partir de zéro avec différentes graines et entiné pour 10 séries aléatoires pour chaque tâche de colle. Le score d'un modèle est la moyenne du meilleur de 10 pour chaque tâche. (Le processus est le même que celui décrit dans le document) que nous pouvons le voir, bien que Electra se moque de l'entraînement adéversarial, il a une bonne stabilité d'entraînement.
| Modèle | Cola | SST | MRPC | STS | QQP | MNLI | QNLI | Rte |
|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt (MOS) | 1.30 | 0,49 | 0.7 | 0,29 | 0.1 | 0,15 | 0,33 | 1.93 |
Tableau 5: Écart type pour chaque tâche. Il s'agit du même modèle que le tableau 1, que Finetunes 10 exécute pour chaque tâche.
Post de forum HuggingFace
Fastai Forum Post
Remarque: ce projet est en fait pour mes recherches personnelles. Je n'ai donc pas essayé de faciliter l'utilisation pour tous les utilisateurs, mais j'essaye de le rendre facile à lire et à modifier.
pip3 install -r requirements.txt
python pretrain.pypretrained_checkcpoint dans finetune.py pour utiliser le point de contrôle que vous avez prétraité et enregistré dans electra_pytorch/checkpoints/pretrain .python finetune.py (avec do_finetune réglé sur True )th_runs dans finetune.py en fonction des numéros des noms des exécutions que vous avez choisies.python finetune.py (avec do_finetune réglé sur False ), ces prévisions Outpus sur TestSet, vous pouvez ensuite compresser et envoyer .tsv s dans electra_pytorch/test_outputs/<group_name>/*.tsv sur le site de glue pour obtenir le score de test. Je n'ai pas utilisé d'arguments CLI, alors configurez des options enfermées dans MyConfig dans les fichiers Python à vos besoins avant de les exécuter. (Il y a des commentaires en dessous montrant les options pour les paramètres de vanille)
Vous aurez besoin d'un compte Neptune et de la création d'un projet Neptune sur le site Web pour enregistrer des résultats de finetuning de colle. N'oubliez pas de remplacer richarddwang/electra-glue par le nom de votre projet Neptune
Les fichiers Python pretrain.py , finetune.py sont en fait convertis à partir de Pretrain.ipynb et Finetune_GLUE.ipynb . Vous pouvez également utiliser ces ordinateurs portables pour explorer la formation Electra et les finetuning.
Vous trouverez ci-dessous les détails de l'implémentation / papier d'origine qui sont faciles à négliger et je me suis occupé. J'ai trouvé que ces détails sont indispensables pour reproduire avec succès les résultats du document.
ElectraClassificationHead utilise. Si vous pré-séjournez, finetune et générez des résultats de test. electra_pytorch les générera pour vous.
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


