electra_pytorch
1.0.0
の非公式のPytorch実装
Electra:Kevin Clarkによるジェネレーターではなく、判別器としてのテキストエンコーダーを事前に訓練するテキストエンコーダー。 Minh-Thang Luong。 Quoc V. Le。クリストファー・D・マニング
curdationアップデートと将来の作業については、フォローしてください
私はゼロからエレクトラスマールを脱直し、接着剤の紙の結果を正常に再現しました。
| モデル | コーラ | SST | MRPC | sts | QQP | mnli | Qnli | rte | 平均。 Avgの。 |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small-Owt | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| Electra-small-owt(私の) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
表1:接着剤DEVセットの結果。公式の結果は、予想される結果から来ています。スコアは、同じチェックポイントから微調整された平均スコアです。 (この問題を参照)私の結果は、モデルをゼロから前から前に入れることから来ており、各タスクの10個のFinetuning Runから平均を取得します。両方の結果は、OpenWeBtext Corpusでトレーニングされています
| モデル | コーラ | SST | MRPC | sts | QQP | mnli | Qnli | rte | 平均。 |
|---|---|---|---|---|---|---|---|---|---|
| Electra-Small ++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
| Electra-small ++(私の) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
表2:接着剤テストセットの結果。私の結果は、Huggingfaceからロードされた前提条件のチェックポイントを獲得しました。
| 公式トレーニング損失曲線 | 私のトレーニング損失曲線 |
|---|---|
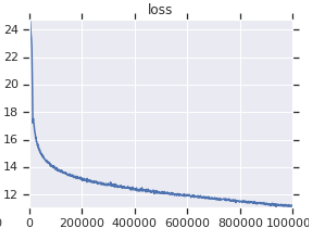 | 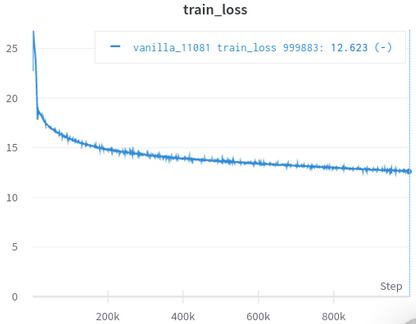 |
表3:どちらもOpenWeBtextでトレーニングされている小さなモデルです。公式のものはここからです。ダウンストリームタスクのパフォーマンスを反映していないため、一粒の塩でトレーニング損失の価値を取るべきです。
データセットを手動でダウンロードして処理する必要はありません。Scirptは、自動的にそれらの注意を払っています。 (Huggingface/DatasetsとHugginface/Transformersに感謝)
Afaikは、元のものに最も近い再実装であり、見過ごされがちな多くの詳細(以下で説明)の世話をしています。
Afaikは、結果を論文に複製することで、それ自体をうまく検証する唯一のものです。
Jupyterノートブックが付属しています。コードを調査して、処理されたデータを検査できます。
自分で何かをダウンロードして前処理する必要はありません。必要なのは、トレーニングスクリプトを実行することだけです。
| 平均 | std | マックス | 分 | #モデル |
|---|---|---|---|---|
| 81.38 | 0.57 | 82.23 | 80.42 | 14 |
Tabel 4:小規模モデルの接着剤Devted結果の統計。すべてのモデルは、さまざまな種子でゼロから前処理され、接着剤タスクごとに10回のランダムな実行に合わせてFinetunedがあります。モデルのスコアは、各タスクで最高の10の平均です。 (このプロセスは論文で説明されているものと同じです)私たちが見ることができるように、ElectraはAdeversarial Trainingをock笑していますが、良いトレーニングの安定性があります。
| モデル | コーラ | SST | MRPC | sts | QQP | mnli | Qnli | rte |
|---|---|---|---|---|---|---|---|---|
| Electra-small-owt(私の) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0.15 | 0.33 | 1.93 |
表5:各タスクの標準偏差。これは、テーブル1と同じモデルであり、Finetunes 10が各タスクに対して実行されます。
Huggingface Forum Post
Fastaiフォーラム投稿
注:このプロジェクトは、実際には私の個人的な研究のためです。そのため、すべてのユーザーが使いやすくしようとはしませんでしたが、読みやすく修正しやすくしようとしています。
pip3 install -r requirements.txt
python pretrain.pyfinetune.pyのpretrained_checkcpointを設定してelectra_pytorch/checkpoints/pretrainで前提と保存したチェックポイントを使用します。python finetune.py ( do_finetuneがTrueに設定されています)finetune.pyでth_runsを設定します。python finetune.py ( do_finetuneがFalseに設定されています)、このアウトパス予測では、 electra_pytorch/test_outputs/<group_name>/*.tsvで.tsv sを圧縮して送信できます。 私はCLI引数を使用していなかったため、PythonファイルのMyConfig内に囲まれたオプションを、実行する前に構成します。 (その下には、バニラの設定のオプションを示すコメントがあります)
Neptuneアカウントが必要になり、WebサイトにNeptuneプロジェクトを作成して、Glue Finetuningの結果を記録します。 richarddwang/electra-glue Neptune Projectの名前に置き換えることを忘れないでください
pythonファイルpretrain.py 、 finetune.pyは、実際にはPretrain.ipynbおよびFinetune_GLUE.ipynbから変換されます。これらのノートブックを使用して、ElectraトレーニングとFinetuningを探索することもできます。
以下に、見落とされやすく、私が世話をした元の実装/紙の詳細を示します。これらの詳細は、論文の結果をうまく再現するために不可欠であることがわかりました。
ElectraClassificationHeadが使用するものではなく、Glue Finetuningのために出力層にドロップアウトと線形層を使用します。前処理、微調整、およびテスト結果を生成する場合。 electra_pytorchこれらを生成します。
project root
|
|── datasets
| |── glue
| |── <task>
| ...
|
|── checkpoints
| |── pretrain
| | |── <base_run_name>_<seed>_<percent>.pth
| | ...
| |
| |── glue
| |── <group_name>_<task>_<ith_run>.pth
| ...
|
|── test_outputs
| |── <group_name>
| | |── CoLA.tsv
| | ...
| |
| | ...
@inproceedings{clark2020electra,
title = {{ELECTRA}: Pre-training Text Encoders as Discriminators Rather Than Generators},
author = {Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning},
booktitle = {ICLR},
year = {2020},
url = {https://openreview.net/pdf?id=r1xMH1BtvB}
}
@misc{electra_pytorch,
author = {Richard Wang},
title = {PyTorch implementation of ELECTRA},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/richarddwang/electra_pytorch}}
}


