hmtl
1.0.0
*****新的2018年11月20日:在線網絡演示*****
我們發布了一個在線演示(以及預先訓練的權重),以便您可以使用該模型。 Web接口的代碼也可以在demo文件夾中提供。
要下載預訓練的型號,請安裝Git LFS並進行git lfs pull 。模型的權重將保存在model_dumps文件夾中。
從語義任務中學習嵌入的層次多任務方法
Victor Sanh,Thomas Wolf,Sebastian Ruder
在AAAI 2019接受
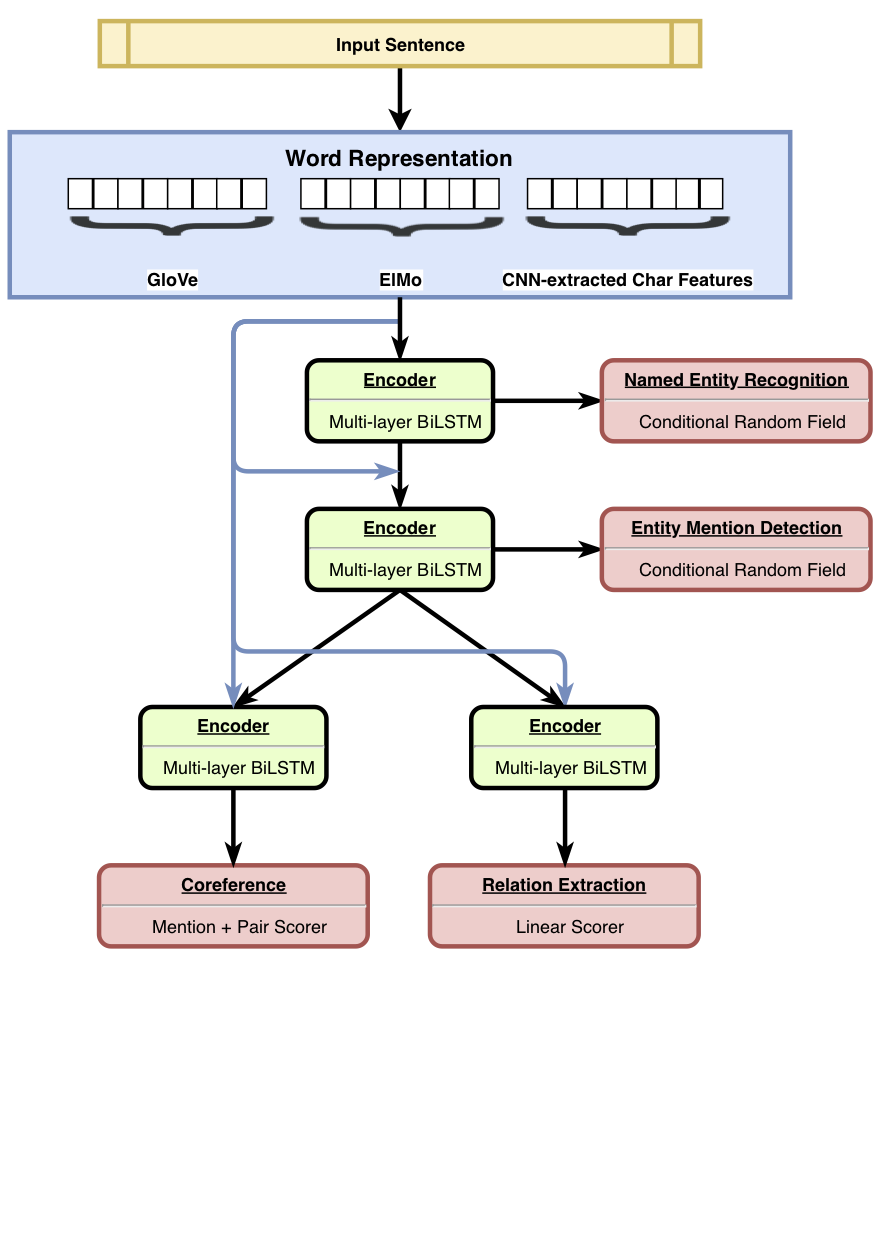
HMTL是一個層次多任務學習模型,結合了四個精心選擇的語義任務(即命名為實體重生,實體提及檢測,關係提取和核心方面的分辨率)。該模型在指定的實體識別,實體提及檢測和關係提取方面實現了最新結果。使用Senteval,我們表明,當我們從模型的底層移到頂層時,該模型傾向於學習更複雜的語義表示。
有關結果的更多詳細信息,請參閱我們的論文。
我們發布了培訓,微調和評估HMTL的代碼。我們希望此代碼對於構建自己的多任務模型(層次結構與否)有用。該代碼用Python編寫,並由Pytorch提供動力。
主要依賴性是:
該代碼可與Python 3.6一起使用。 requirements.txt列出了依賴項的穩定版本。
您可以通過調用腳本./script/machine_setup.sh快速設置工作環境。它安裝了Python 3.6,創建一個乾淨的虛擬環境,並安裝所有所需的依賴項(在requirements.txt中列出)。請根據您的需求調整腳本。
我們將實施方式基於AllennLP庫。有關此庫的介紹,您應該檢查這些教程。
JSON配置文件中定義了一個實驗(有關示例,請參見configs/*.json )。配置文件主要描述要加載的數據集,即與模型的所有超參數一起創建的模型。
設置了配置文件(並在需要時定義的自DatasetReaders類,如有需要),您可以簡單地使用以下命令和參數啟動培訓:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_training培訓開始後,您只需在終端中進行培訓或打開張板板(請確保您之前已經安裝了張量板及其張量依賴性):
tensorboard --logdir my_first_training/log我們使用Senteval來評估模型學到的語言特性。 hmtl_senteval.py給出了一個示例,說明瞭如何在Senteval和HMTL之間創建接口。它評估了Hiechyy(共享的單詞嵌入式和編碼器)所學到的語言屬性。
要下載我們在HMTL中使用的預訓練的嵌入式,您只需啟動腳本./script/data_setup.sh即可。
由於許可原因,我們沒有附加用於培訓HMTL的數據集,但我們邀請您自己收集:Ontonotes 5.0,Conll2003和ACE2005。配置文件期望數據集放置在data/文件夾中。
如果您發現此存儲庫有用,請考慮引用以下論文。
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


