hmtl
1.0.0
***** Baru 20 November 2018: Demo web online tersedia *****
Kami merilis demo online (bersama dengan bobot terlatih) sehingga Anda dapat bermain sendiri dengan model. Kode untuk antarmuka web juga tersedia di folder demo .
Untuk mengunduh model pra-terlatih, silakan instal GIT LFS dan lakukan git lfs pull . Bobot model akan disimpan di folder Model_Dumps.
Pendekatan multi-tugas hierarkis untuk belajar embeddings dari tugas semantik
Victor Sanh, Thomas Wolf, Sebastian Ruder
Diterima di AAAI 2019
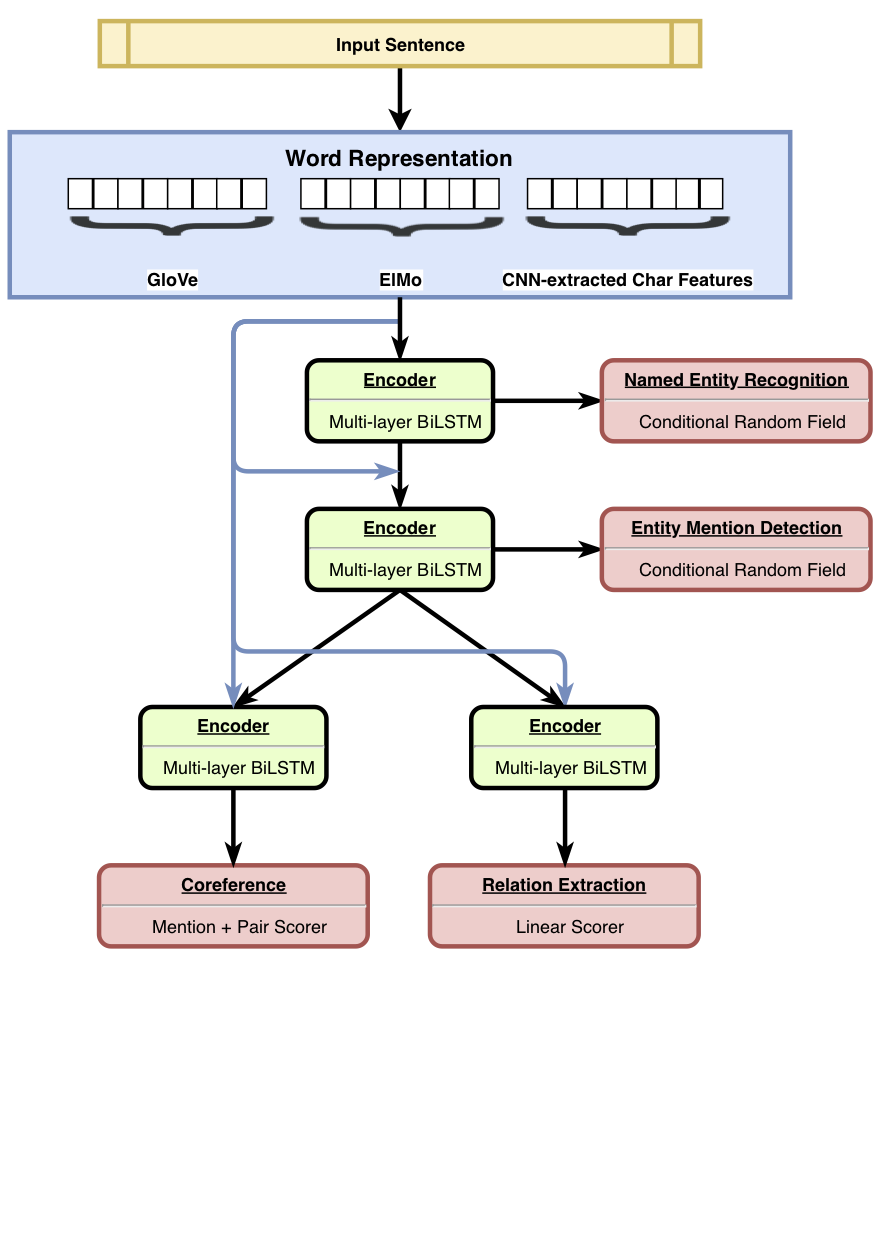
HMTL adalah model pembelajaran multi-tugas hierarkis yang menggabungkan satu set empat tugas semantik yang dipilih dengan cermat (yaitu recoginition entitas yang disebutkan, deteksi penyebutan entitas, ekstraksi relasi dan resolusi coreference). Model ini mencapai hasil canggih pada pengakuan entitas yang disebutkan, deteksi yang menyebutkan entitas dan ekstraksi hubungan. Menggunakan SentEval, kami menunjukkan bahwa saat kami bergerak dari bawah ke lapisan atas model, model cenderung mempelajari representasi semantik yang lebih kompleks.
Untuk perincian lebih lanjut tentang hasilnya, silakan merujuk ke makalah kami.
Kami merilis kode untuk pelatihan , fine tuning , dan mengevaluasi HMTL. Kami berharap kode ini akan berguna untuk membangun model multi-tugas Anda sendiri (hierarkis atau tidak). Kode ini ditulis dalam Python dan didukung oleh Pytorch .
Ketergantungan utamanya adalah:
Kode berfungsi dengan Python 3.6 . Versi dependensi yang stabil tercantum dalam requirements.txt .
Anda dapat dengan cepat mengatur lingkungan kerja dengan memanggil skrip ./script/machine_setup.sh . Ini menginstal Python 3.6, menciptakan lingkungan virtual yang bersih, dan menginstal semua dependensi yang diperlukan (tercantum dalam requirements.txt ). Harap beradaptasi skrip tergantung pada kebutuhan Anda.
Kami mendasarkan implementasi kami di Perpustakaan Allennlp. Untuk pengantar perpustakaan ini, Anda harus memeriksa tutorial ini.
Eksperimen didefinisikan dalam file konfigurasi JSON (lihat configs/*.json untuk contoh). File konfigurasi terutama menjelaskan dataset untuk dimuat, model yang akan dibuat bersama dengan semua hyper-parameter model.
Setelah Anda mengatur file konfigurasi Anda (dan kelas kustom yang ditentukan seperti DatasetReaders jika diperlukan), Anda dapat meluncurkan pelatihan dengan perintah dan argumen berikut:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_trainingSetelah pelatihan dimulai, Anda cukup mengikuti pelatihan di terminal atau membuka Tensorboard (pastikan Anda telah menginstal Tensorboard dan TensorFlow Dependecy sebelumnya):
tensorboard --logdir my_first_training/log Kami menggunakan SentEval untuk menilai sifat linguistik yang dipelajari oleh model. hmtl_senteval.py memberikan contoh bagaimana kita dapat membuat antarmuka antara SentEval dan HMTL. Ini mengevaluasi sifat -sifat linguistik yang dipelajari oleh setiap lapisan Hiarchy (kata embeddings dan encoder kata berbasis bersama).
Untuk mengunduh embeddings pra-terlatih yang kami gunakan di HMTL, Anda dapat meluncurkan skrip ./script/data_setup.sh .
Kami tidak melampirkan kumpulan data yang digunakan untuk melatih HMTL karena alasan lisensi, tetapi kami mengundang Anda untuk mengumpulkannya sendiri: Ontonotes 5.0, Conll2003, dan ACE2005. File konfigurasi mengharapkan dataset ditempatkan di data/ folder.
Harap pertimbangkan mengutip makalah berikut jika Anda menemukan repositori ini bermanfaat.
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


