hmtl
1.0.0
***** NEU 20. November 2018: Online -Web -Demo ist verfügbar *****
Wir haben eine Online-Demo (zusammen mit vorgeborenen Gewichten) veröffentlicht, damit Sie sich mit dem Modell selbst spielen können. Der Code für die Webschnittstelle ist auch im demo -Ordner verfügbar.
Um die vorgeborenen Modelle herunterzuladen, installieren Sie bitte Git LFS und machen Sie einen git lfs pull . Die Gewichte des Modells werden im Ordner model_dumps gespeichert.
Ein hierarchischer Multitasking-Ansatz zum Lernen von Einbettungen aus semantischen Aufgaben
Victor Sanh, Thomas Wolf, Sebastian Ruder
Akzeptiert bei AAAI 2019
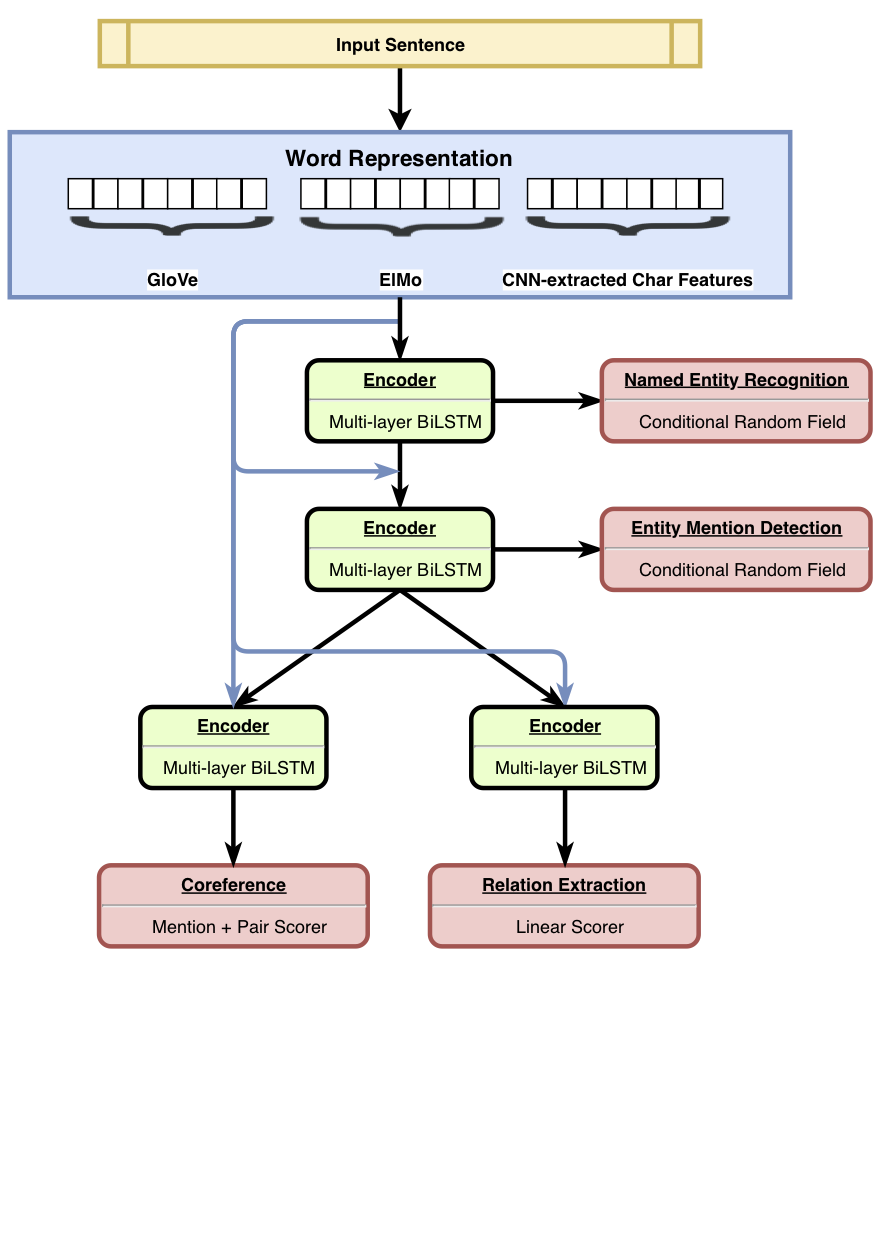
HMTL ist ein hierarchisches Multitask-Lernmodell, das einen Satz von vier sorgfältig ausgewählten semantischen Aufgaben kombiniert (nämlich als Entitätsrekoginition genannt, Entitätserkennung, Beziehungsextraktion und Koreferenzauflösung). Das Modell erzielt hochmoderne Ergebnisse zur Erkennung der Entität, Entitätserkennung und Beziehungsextraktion. Mit Sental zeigen wir, dass das Modell, wenn wir uns von unten zu den oberen Schichten des Modells bewegen, eine komplexere semantischere Darstellung erlernen.
Weitere Informationen zu den Ergebnissen finden Sie in unserem Artikel.
Wir haben den Code für Training , Feinabstimmung und Bewertung von HMTL veröffentlicht. Wir hoffen, dass dieser Code nützlich ist, um Ihre eigenen Multi-Task-Modelle (hierarchisch oder nicht) zu erstellen. Der Code ist in Python geschrieben und von Pytorch betrieben.
Die Hauptabhängigkeiten sind:
Der Code funktioniert mit Python 3.6 . Eine stabile Version der Abhängigkeiten ist in requirements.txt aufgeführt.
Sie können eine Arbeitsumgebung schnell einrichten, indem Sie das Skript aufrufen ./script/machine_setup.sh . Es installiert Python 3.6, erstellt eine saubere virtuelle Umgebung und installiert alle erforderlichen Abhängigkeiten (in requirements.txt aufgeführt.txt). Bitte passen Sie das Skript je nach Ihren Bedürfnissen an.
Wir haben unsere Implementierung auf der Allennlp -Bibliothek gestützt. Für eine Einführung in diese Bibliothek sollten Sie diese Tutorials überprüfen.
Ein Experiment wird in einer JSON -Konfigurationsdatei definiert (siehe configs/*.json für Beispiele). Die Konfigurationsdatei beschreibt hauptsächlich die zu geladenen Datensätze, das Modell, das zusammen mit allen Hyperparametern des Modells erstellt werden soll.
Sobald Sie Ihre Konfigurationsdatei eingerichtet haben (und bei Bedarf benutzerdefinierte Klassen wie DatasetReaders definiert haben), können Sie einfach ein Training mit dem folgenden Befehl und den Argumenten starten:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_trainingSobald das Training begonnen hat, können Sie einfach das Training im Terminal verfolgen oder ein Tensorboard öffnen (bitte stellen Sie sicher, dass Sie Tensorboard und seine TensorFlow Depecy installiert haben):
tensorboard --logdir my_first_training/log Wir haben Sental verwendet, um die vom Modell gelernten sprachlichen Eigenschaften zu bewerten. hmtl_senteval.py gibt ein Beispiel dafür, wie wir eine Schnittstelle zwischen Sental und HMTL erstellen können. Es bewertet die sprachlichen Eigenschaften, die von jeder Ebene der Hiearchie gelernt wurden (gemeinsam genutzte Worteinbettungen und -Codierer).
Um die in HMTL verwendeten vorgeborenen Einbettungen herunterzuladen, können Sie einfach das Skript starten ./script/data_setup.sh .
Wir haben die Datensätze, mit denen HMTL aus Lizenzgründen verwendet wurde, nicht angehängt, aber wir laden Sie ein, sie selbst zu sammeln: Ontonotes 5.0, Conll2003 und ACE2005. Die Konfigurationsdateien erwarten, dass die Datensätze im data/ Ordner platziert werden.
Bitte erwägen Sie das folgende Papier, wenn Sie dieses Repository nützlich finden.
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


