hmtl
1.0.0
***** Novo 20 de novembro de 2018: a demonstração da web online está disponível *****
Lançamos uma demonstração on-line (junto com pesos pré-treinados) para que você possa se jogar com o modelo. O código da interface da Web também está disponível na pasta demo .
Para baixar os modelos pré-treinados, instale o GIT LFS e faça um git lfs pull . Os pesos do modelo serão salvos na pasta Model_Dumps.
Uma abordagem hierárquica de várias tarefas para aprender incorporações de tarefas semânticas
Victor Sanh, Thomas Wolf, Sebastian Ruder
Aceito em AAAI 2019
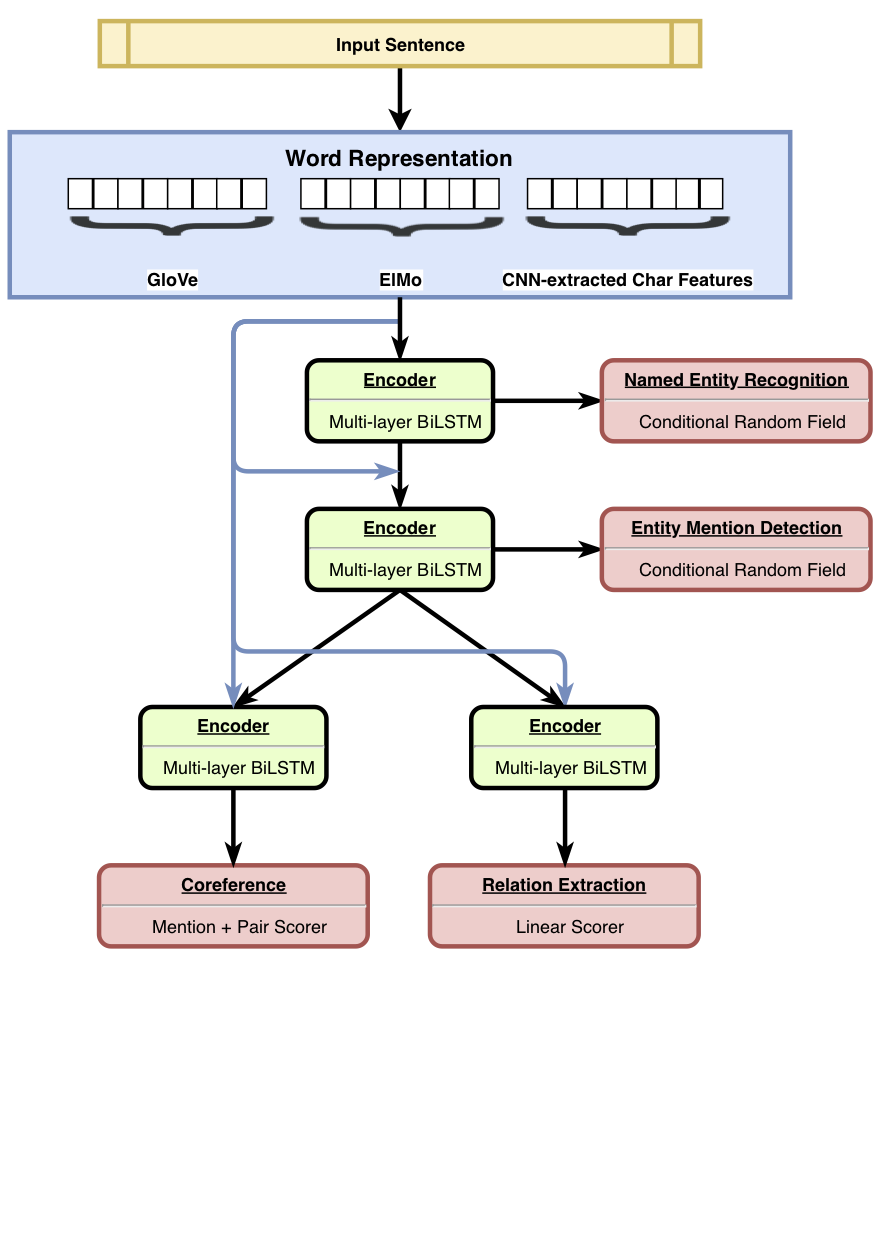
O HMTL é um modelo hierárquico de aprendizado de várias tarefas que combina um conjunto de quatro tarefas semânticas cuidadosamente selecionadas (a saber, denominado reconhecimento de entidade, detecção de menção de entidade, extração de relação e resolução de coreferência). O modelo atinge os resultados de ponta no reconhecimento de entidade nomeado, na detecção de mencionação da entidade e na extração de relação. Usando o Senteval, mostramos que, à medida que passamos de camadas de baixo para as principais do modelo, o modelo tende a aprender uma representação semântica mais complexa.
Para mais detalhes sobre os resultados, consulte o nosso artigo.
Lançamos o código para treinamento , ajuste fino e avaliação do HMTL. Esperamos que este código seja útil para criar seus próprios modelos de várias tarefas (hierárquica ou não). O código é escrito em Python e alimentado por Pytorch .
As principais dependências são:
O código funciona com o Python 3.6 . Uma versão estável das dependências está listada no requirements.txt .
Você pode configurar rapidamente um ambiente de trabalho chamando o script ./script/machine_setup.sh . Ele instala o Python 3.6, cria um ambiente virtual limpo e instala todas as dependências necessárias (listadas no requirements.txt ). Adapte o script, dependendo de suas necessidades.
Baseamos nossa implementação na biblioteca AllennLP. Para uma introdução a esta biblioteca, você deve verificar esses tutoriais.
Um experimento é definido em um arquivo de configuração JSON (consulte configs/*.json para exemplos). O arquivo de configuração descreve principalmente os conjuntos de dados a serem carregados, o modelo para criar junto com todos os hiper-parâmetros do modelo.
Depois de configurar seu arquivo de configuração (e definir as classes personalizadas como DatasetReaders , se necessário), você pode simplesmente iniciar um treinamento com o seguinte comando e argumentos:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_trainingDepois que o treinamento é iniciado, você pode simplesmente seguir o treinamento no terminal ou abrir um tensorboard (verifique se você já instalou o Tensorboard e seu tensorflow DependEcy antes):
tensorboard --logdir my_first_training/log Usamos o SentEval para avaliar as propriedades linguísticas aprendidas pelo modelo. hmtl_senteval.py fornece um exemplo de como podemos criar uma interface entre o SentEval e o HMTL. Ele avalia as propriedades linguísticas aprendidas por todas as camadas da enigma (incorporações e codificadores de palavras baseadas em compartilhamento).
Para baixar as incorporações pré-treinadas que usamos no HMTL, você pode simplesmente iniciar o script ./script/data_setup.sh .
Não anexamos os conjuntos de dados usados para treinar o HMTL por razões de licenciamento, mas convidamos você a colecioná -los sozinho: Ontontotes 5.0, CONLL2003 e ACE2005. Os arquivos de configuração esperam que os conjuntos de dados sejam colocados na data/ pasta.
Por favor, considere citar o documento a seguir se você achar esse repositório útil.
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


