hmtl
1.0.0
***** Новый 20 ноября 2018 года: доступно онлайн -демо -версии *****
Мы выпустили онлайн-демонстрацию (наряду с предварительно обученными весами), чтобы вы могли играть сами с моделью. Код для веб -интерфейса также доступен в demo -папке.
Чтобы загрузить предварительно обученные модели, пожалуйста, установите GIT LFS и сделайте git lfs pull . Вес модели будут сохранены в папке Model_dumps.
Иерархический многозадачный подход для обучения встраиванию из семантических задач
Виктор Сан, Томас Вольф, Себастьян Рудер
Принято на AAAI 2019
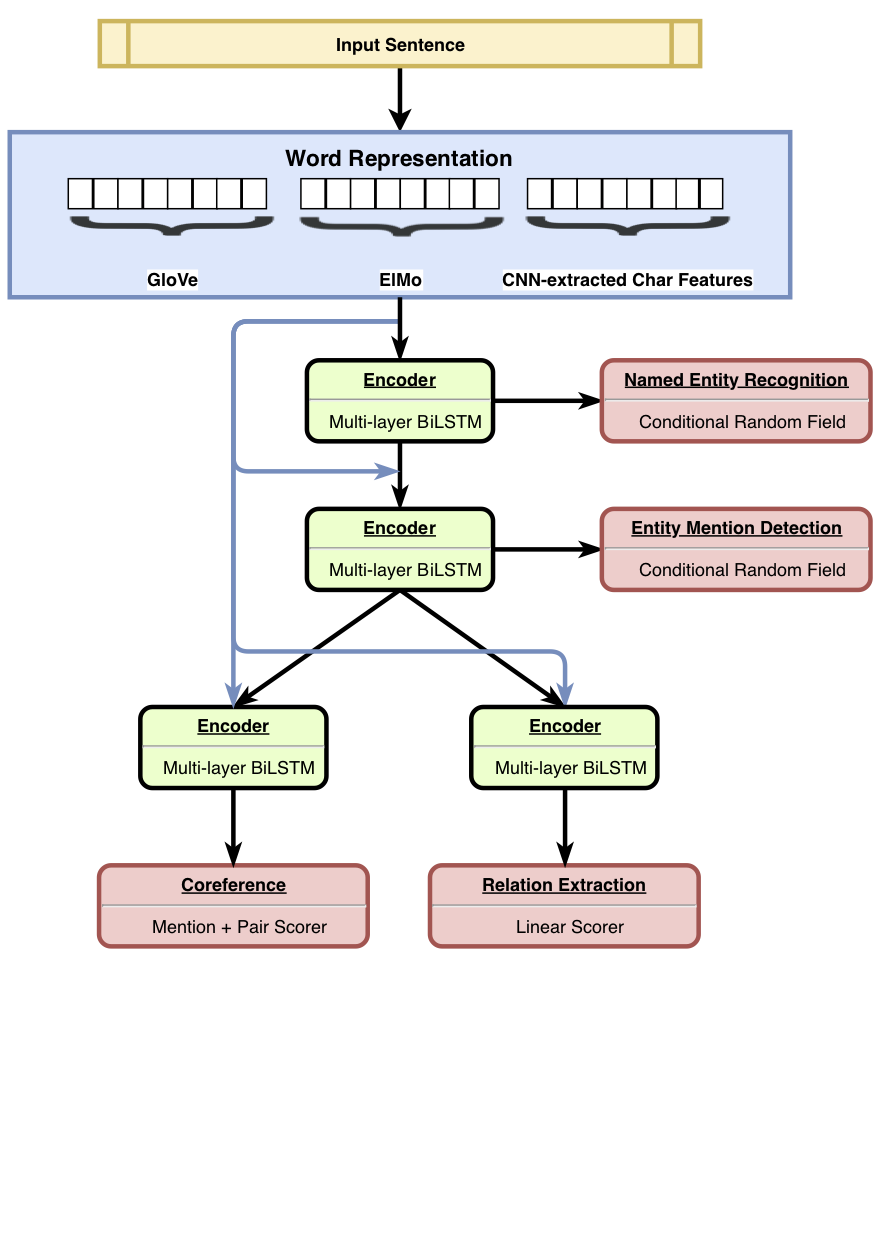
HMTL-это иерархическая модель обучения с несколькими задачами, которая объединяет набор из четырех тщательно выбранных семантических задач (а именно названная сущность Recoginition, обнаружение упоминания сущности, извлечение отношений и разрешение основной работы). Модель достигает самых современных результатов по признанию именованной организации, обнаружению и извлечении отношений. Используя Senteval, мы показываем, что по мере того, как мы перемещаемся от нижней части к верхним слоям модели, модель, как правило, изучает более сложное семантическое представление.
Для получения дополнительной информации о результатах, пожалуйста, обратитесь к нашей статье.
Мы выпустили код для обучения , тонкой настройки и оценки HMTL. Мы надеемся, что этот код будет полезен для создания ваших собственных многозадачных моделей (иерархических или нет). Код написан на Python и питается Pytorch .
Основными зависимостями являются:
Код работает с Python 3.6 . Стабильная версия зависимостей указана в requirements.txt .
Вы можете быстро настроить рабочую среду, вызвав скрипт ./script/machine_setup.sh . Он устанавливает Python 3.6, создает чистую виртуальную среду и устанавливает все необходимые зависимости (перечисленные в requirements.txt ). Пожалуйста, адаптируйте сценарий в зависимости от ваших потребностей.
Мы основали нашу реализацию на библиотеке Allennlp. Для введения в эту библиотеку вы должны проверить эти учебники.
Эксперимент определяется в файле конфигурации JSON (см configs/*.json для примеров). Файл конфигурации в основном описывает наборы данных для загрузки, модель для создания вместе со всеми гиперпараметрами модели.
После того, как вы настроили свой файл конфигурации (и определили пользовательские классы, такие как DatasetReaders если это необходимо), вы можете просто запустить обучение со следующей командой и аргументами:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_trainingПосле начала обучения вы можете просто следовать обучению в терминале или открыть тенордорд (пожалуйста, убедитесь, что вы установили Tensorboard и его зависимость Tensorflow ранее):
tensorboard --logdir my_first_training/log Мы использовали Senteval для оценки лингвистических свойств, изученных моделью. hmtl_senteval.py приводит пример того, как мы можем создать интерфейс между Senteval и HMTL. Он оценивает лингвистические свойства, изученные каждым слоем Hiearchy (общие вставки и кодеры слов на основе общих слов).
Чтобы загрузить предварительно обученные вставки, которые мы использовали в HMTL, вы можете просто запустить скрипт ./script/data_setup.sh .
Мы не прикрепляли наборы данных, используемые для обучения HMTL по соображениям лицензирования, но мы приглашаем вас забрать их самостоятельно: Ontonotes 5.0, Conll2003 и ACE2005. Файлы конфигурации ожидают, что наборы данных будут размещены в data/ папке.
Пожалуйста, рассмотрите возможность сослаться на следующую статью, если вы найдете этот репозиторий полезным.
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


