hmtl
1.0.0
***** الجديد في 20 نوفمبر 2018: عرض تجريبي عبر الإنترنت متاح *****
أصدرنا عرضًا تجريبيًا عبر الإنترنت (جنبًا إلى جنب مع الأوزان المدربة مسبقًا) حتى تتمكن من لعب نفسك مع النموذج. رمز واجهة الويب متوفر أيضًا في المجلد demo .
لتنزيل النماذج التي تم تدريبها مسبقًا ، يرجى تثبيت GIT LFS والقيام git lfs pull . سيتم حفظ أوزان النموذج في مجلد Model_dumps.
نهج متعددة المهام هرمية لتعلم التضمينات من المهام الدلالية
فيكتور سانه ، توماس وولف ، سيباستيان رودر
مقبولة في AAAI 2019
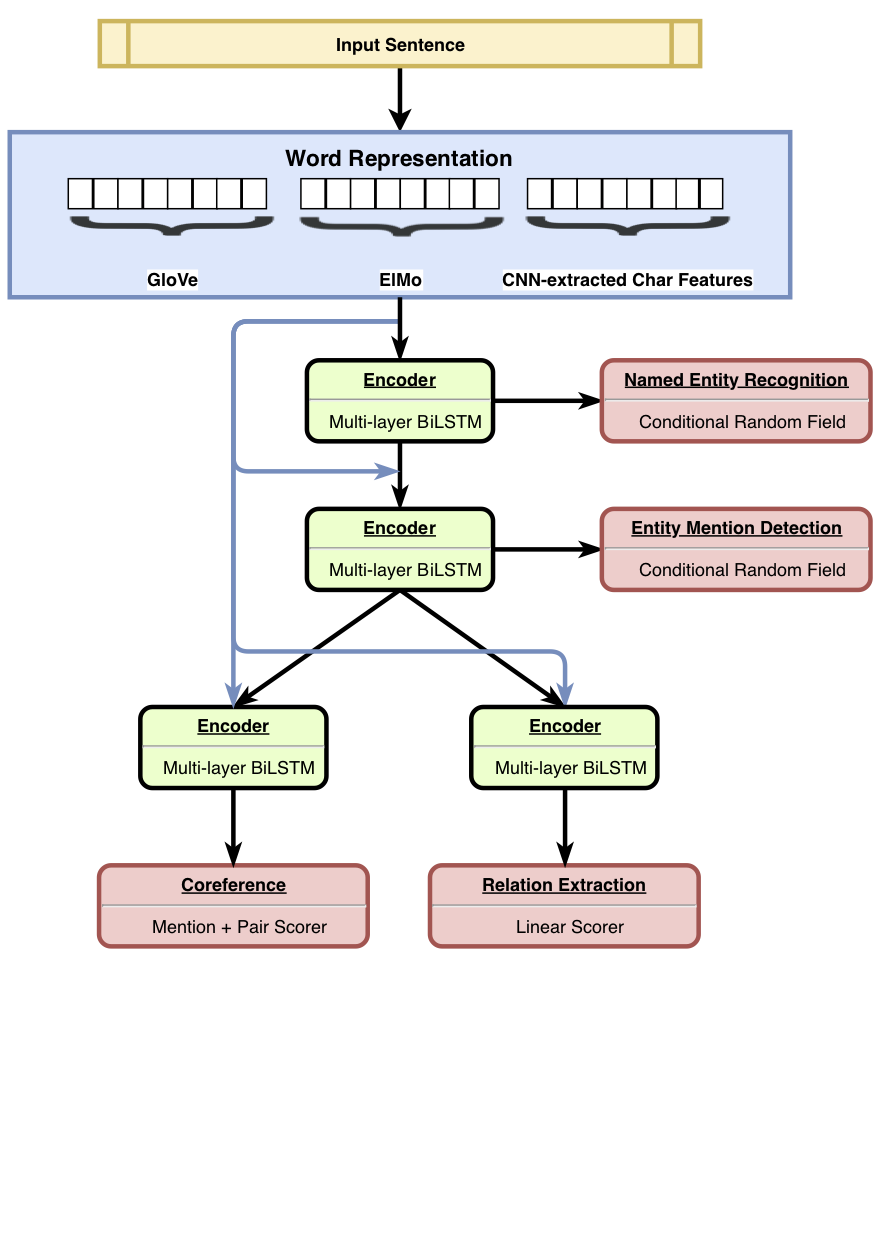
HMTL هو نموذج تعليمي متعدد المهام هرمي يجمع بين مجموعة من أربع مهام دلالية تم اختيارها بعناية (وهي إعادة تسمية الكيان المسمى ، وذكر الكيان ، واكتشاف العلاقة ، وحل العلاقة). يحقق النموذج نتائج حديثة على التعرف على الكيان المسماة ، وذكر الكيان الكشف واستخراج العلاقة. باستخدام Senteval ، نظهر أنه مع انتقالنا من أسفل إلى الطبقات العليا من النموذج ، يميل النموذج إلى معرفة تمثيل دلالي أكثر تعقيدًا.
لمزيد من التفاصيل حول النتائج ، يرجى الرجوع إلى ورقتنا.
أصدرنا رمز التدريب ، وضبط الدقيق وتقييم HMTL. نأمل أن يكون هذا الرمز مفيدًا لبناء نماذج متعددة المهام الخاصة بك (التسلسل الهرمي أم لا). الكود مكتوب في Python ويتم تشغيله بواسطة Pytorch .
التبعيات الرئيسية هي:
يعمل الرمز مع Python 3.6 . يتم سرد نسخة مستقرة من التبعيات في requirements.txt .
يمكنك إعداد بيئة عمل بسرعة عن طريق استدعاء البرنامج النصي ./script/machine_setup.sh . يقوم بتثبيت Python 3.6 ، ويقوم بإنشاء بيئة افتراضية نظيفة ، ويقوم بتثبيت جميع التبعيات المطلوبة (المدرجة في requirements.txt ). يرجى تكييف البرنامج النصي اعتمادًا على احتياجاتك.
لقد اعتمدنا تنفيذنا على مكتبة Allennlp. للحصول على مقدمة لهذه المكتبة ، يجب عليك التحقق من هذه البرامج التعليمية.
يتم تعريف التجربة في ملف تكوين JSON (انظر configs/*.json للحصول على أمثلة). يصف ملف التكوين بشكل أساسي مجموعات البيانات التي يجب تحميلها ، وهو النموذج الذي يجب إنشاؤه مع جميع المعلمات المفرطة للنموذج.
بمجرد إعداد ملف التكوين الخاص بك (والفئات المخصصة المحددة مثل DatasetReaders إذا لزم الأمر) ، يمكنك ببساطة إطلاق تدريب مع الأمر والوسائط التالية:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_trainingبمجرد بدء التدريب ، يمكنك ببساطة اتباع التدريب في المحطة أو فتح تنسورسور (يرجى التأكد من أنك قمت بتثبيت Tensorboard و Tensorflow تعتمد من قبل):
tensorboard --logdir my_first_training/log استخدمنا SentVal لتقييم الخصائص اللغوية التي تعلمتها النموذج. يعطي hmtl_senteval.py مثالاً على كيفية إنشاء واجهة بين Senteval و HMTL. إنه يقيم الخصائص اللغوية التي تعلمتها كل طبقة من hiearchy (تضمينات الكلمات المشتركة والمشتغات).
لتنزيل التضمينات التي تم تدريبها مسبقًا استخدمناها في HMTL ، يمكنك ببساطة تشغيل البرنامج النصي ./script/data_setup.sh .
لم نرفق مجموعات البيانات المستخدمة لتدريب HMTL لأسباب ترخيص ، لكننا ندعوك لجمعها بنفسك: Ontonotes 5.0 و Conll2003 و ACE2005. تتوقع ملفات التكوين وضع مجموعات البيانات في data/ المجلد.
يرجى التفكير في الاستشهاد بالورقة التالية إذا وجدت هذا المستودع مفيدًا.
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


