hmtl
1.0.0
***** Nuevo 20 de noviembre de 2018: la demostración web en línea está disponible *****
Lanzamos una demostración en línea (junto con pesos previamente capacitados) para que pueda jugar con el modelo. El código para la interfaz web también está disponible en la carpeta demo .
Para descargar los modelos previamente capacitados, instale Git LFS y haga un git lfs pull . Los pesos del modelo se guardarán en la carpeta Model_Dumps.
Un enfoque jerárquico de tareas múltiples para aprender incrustaciones de tareas semánticas
Victor Sanh, Thomas Wolf, Sebastian Ruder
Aceptado en AAAI 2019
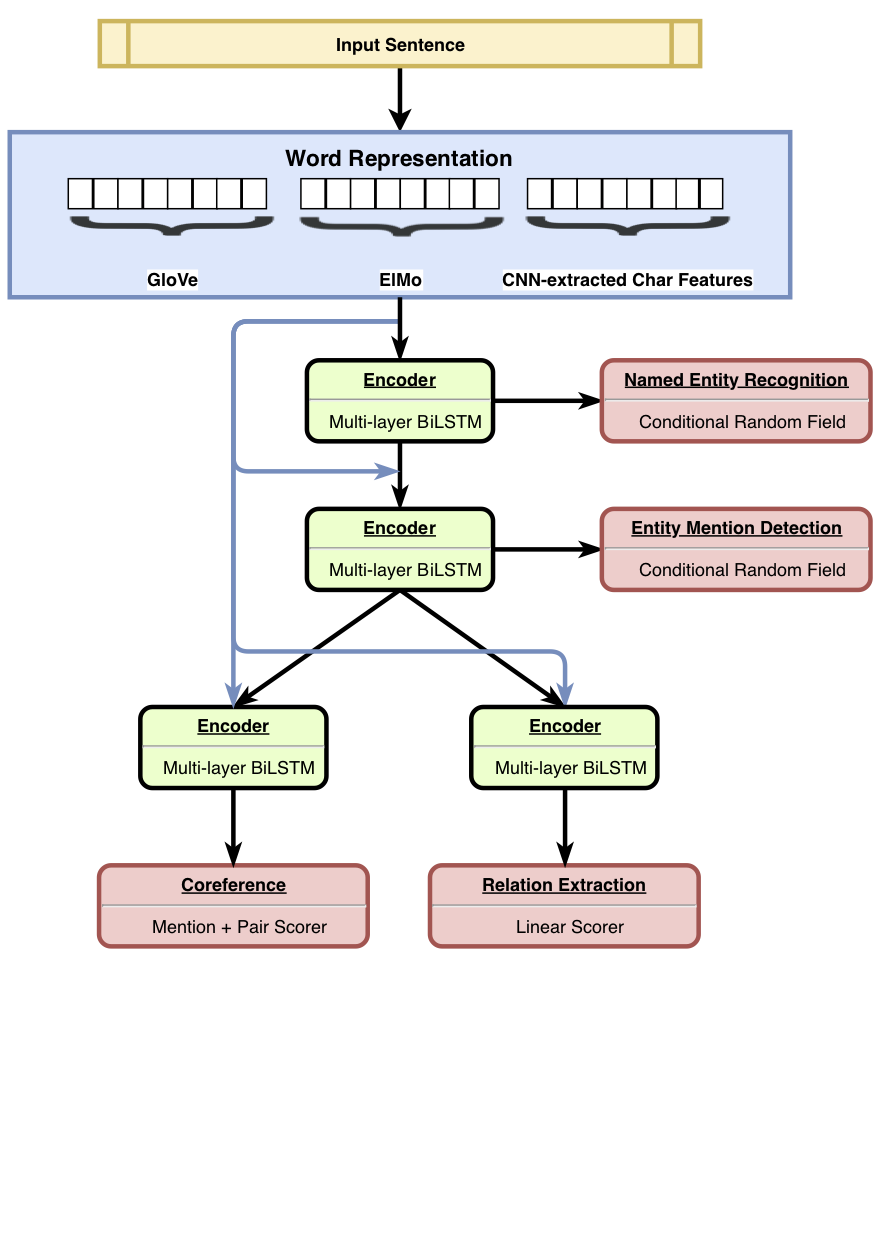
HMTL es un modelo jerárquico de aprendizaje de tareas múltiples que combina un conjunto de cuatro tareas semánticas cuidadosamente seleccionadas (a saber, la recoginición de entidad con nombre, detección de mención de entidad, extracción de relación y resolución de coreferencia). El modelo logra los resultados de vanguardia en el reconocimiento de entidad nombrado, la detección de la mención de la entidad y la extracción de relaciones. Usando Senteval, mostramos que a medida que avanzamos de las capas inferiores a las superiores del modelo, el modelo tiende a aprender una representación semántica más compleja.
Para obtener más detalles sobre los resultados, consulte nuestro documento.
Lanzamos el código para capacitar , ajustar y evaluar HMTL. Esperamos que este código sea útil para construir sus propios modelos de varias tareas (jerárquico o no). El código está escrito en Python y impulsado por Pytorch .
Las principales dependencias son:
El código funciona con Python 3.6 . Una versión estable de las dependencias se enumera en requirements.txt .
Puede configurar rápidamente un entorno de trabajo llamando al script ./script/machine_setup.sh . Instala Python 3.6, crea un entorno virtual limpio e instala todas las dependencias requeridas (enumeradas en requirements.txt ). Adapte el script dependiendo de sus necesidades.
Basamos nuestra implementación en la biblioteca Allennlp. Para una introducción a esta biblioteca, debe consultar estos tutoriales.
Un experimento se define en un archivo de configuración de JSON (consulte configs/*.json para ejemplos). El archivo de configuración describe principalmente los conjuntos de datos para cargar, el modelo para crear junto con todos los hiper-parametros del modelo.
Una vez que haya configurado su archivo de configuración (y las clases personalizadas definidas como DatasetReaders si es necesario), simplemente puede iniciar una capacitación con el siguiente comando y argumentos:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_trainingUna vez que el entrenamiento ha comenzado, simplemente puede seguir la capacitación en la terminal o abrir una placa tensor (asegúrese de haber instalado TensorBoard y su dependencia de TensorFlow antes):
tensorboard --logdir my_first_training/log Utilizamos Senteval para evaluar las propiedades lingüísticas aprendidas por el modelo. hmtl_senteval.py da un ejemplo de cómo podemos crear una interfaz entre Senteval y HMTL. Evalúa las propiedades lingüísticas aprendidas por cada capa de la HiOchy (incrustaciones y codificadores de palabras basados en base compartidos).
Para descargar los incrustaciones previamente entrenados que utilizamos en HMTL, simplemente puede iniciar el script ./script/data_setup.sh .
No adjuntamos los conjuntos de datos utilizados para entrenar HMTL por razones de licencia, pero lo invitamos a recopilarlos usted mismo: Ontonotes 5.0, Conll2003 y ACE2005. Los archivos de configuración esperan que los conjuntos de datos se coloquen en la carpeta data/ .
Considere citar el siguiente documento si encuentra útil este repositorio.
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


