hmtl
1.0.0
*****新的2018年11月20日:在线网络演示*****
我们发布了一个在线演示(以及预先训练的权重),以便您可以使用该模型。 Web接口的代码也可以在demo文件夹中提供。
要下载预训练的型号,请安装Git LFS并进行git lfs pull 。模型的权重将保存在model_dumps文件夹中。
从语义任务中学习嵌入的层次多任务方法
Victor Sanh,Thomas Wolf,Sebastian Ruder
在AAAI 2019接受
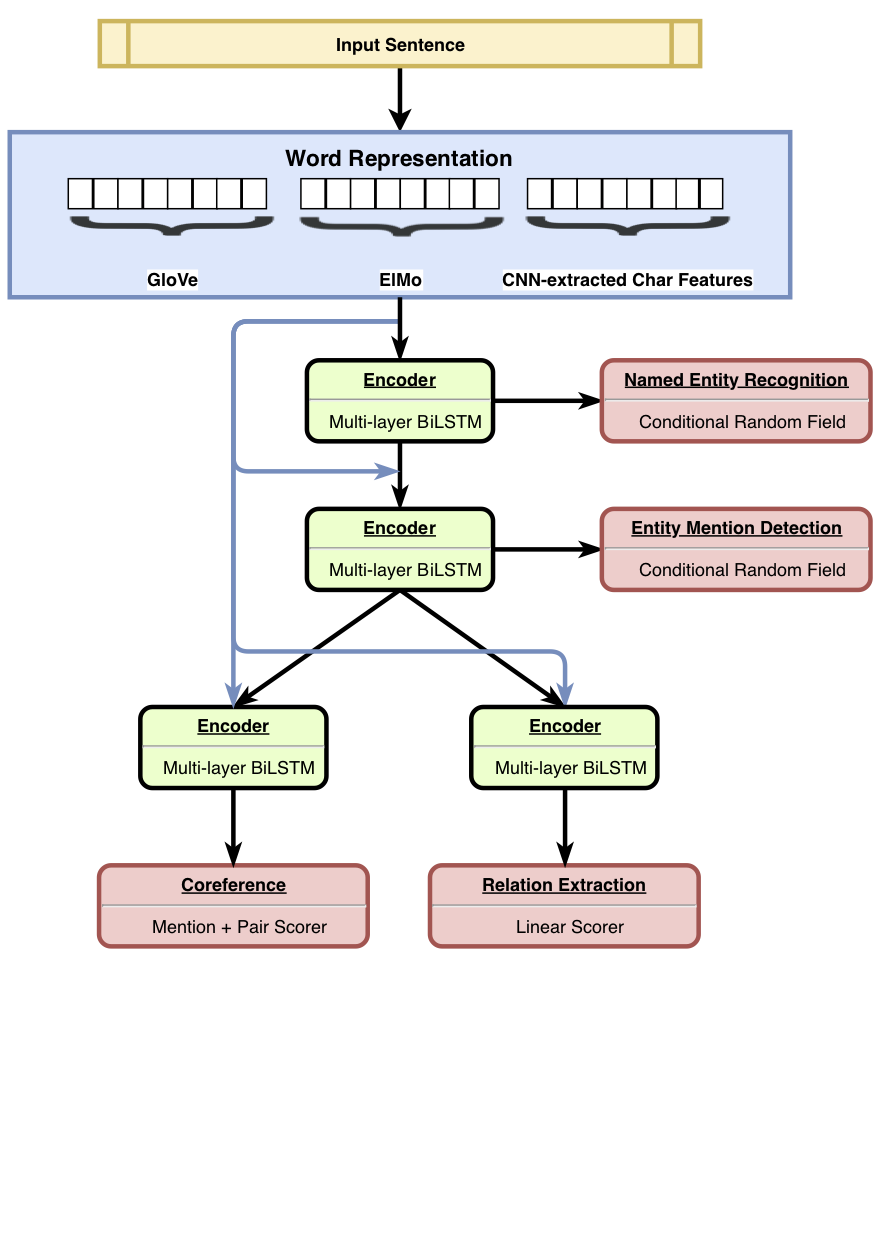
HMTL是一个层次多任务学习模型,结合了四个精心选择的语义任务(即命名为实体重生,实体提及检测,关系提取和核心方面的分辨率)。该模型在指定的实体识别,实体提及检测和关系提取方面实现了最新结果。使用Senteval,我们表明,当我们从模型的底层移到顶层时,该模型倾向于学习更复杂的语义表示。
有关结果的更多详细信息,请参阅我们的论文。
我们发布了培训,微调和评估HMTL的代码。我们希望此代码对于构建自己的多任务模型(层次结构与否)有用。该代码用Python编写,并由Pytorch提供动力。
主要依赖性是:
该代码可与Python 3.6一起使用。 requirements.txt列出了依赖项的稳定版本。
您可以通过调用脚本./script/machine_setup.sh快速设置工作环境。它安装了Python 3.6,创建一个干净的虚拟环境,并安装所有所需的依赖项(在requirements.txt中列出)。请根据您的需求调整脚本。
我们将实施方式基于AllennLP库。有关此库的介绍,您应该检查这些教程。
JSON配置文件中定义了一个实验(有关示例,请参见configs/*.json )。配置文件主要描述要加载的数据集,即与模型的所有超参数一起创建的模型。
设置了配置文件(并在需要时定义的自DatasetReaders类,如有需要),您可以简单地使用以下命令和参数启动培训:
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_training培训开始后,您只需在终端中进行培训或打开张板板(请确保您之前已经安装了张量板及其张量依赖性):
tensorboard --logdir my_first_training/log我们使用Senteval来评估模型学到的语言特性。 hmtl_senteval.py给出了一个示例,说明了如何在Senteval和HMTL之间创建接口。它评估了Hiechyy(共享的单词嵌入式和编码器)所学到的语言属性。
要下载我们在HMTL中使用的预训练的嵌入式,您只需启动脚本./script/data_setup.sh即可。
由于许可原因,我们没有附加用于培训HMTL的数据集,但我们邀请您自己收集:Ontonotes 5.0,Conll2003和ACE2005。配置文件期望数据集放置在data/文件夹中。
如果您发现此存储库有用,请考虑引用以下论文。
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}


