text to sql epi ehr naacl2024
1.0.0
該存儲庫包含以下論文的代碼:
@misc{ziletti2024retrieval,
title={Retrieval augmented text-to-SQL generation for epidemiological question answering using electronic health records},
author={Angelo Ziletti and Leonardo D'Ambrosi},
year={2024},
eprint={2403.09226},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
請在此處找到預印本:Ziletti和D'Ambrosi,https://arxiv.org/abs/2403.09226
本文在NAACL 2024臨床NLP研討會(https://clinical-nlp.github.io/2024/)上接受。
如果您在工作或研究中使用此代碼,請引用這項工作。
這是該過程的摘要工作流程: 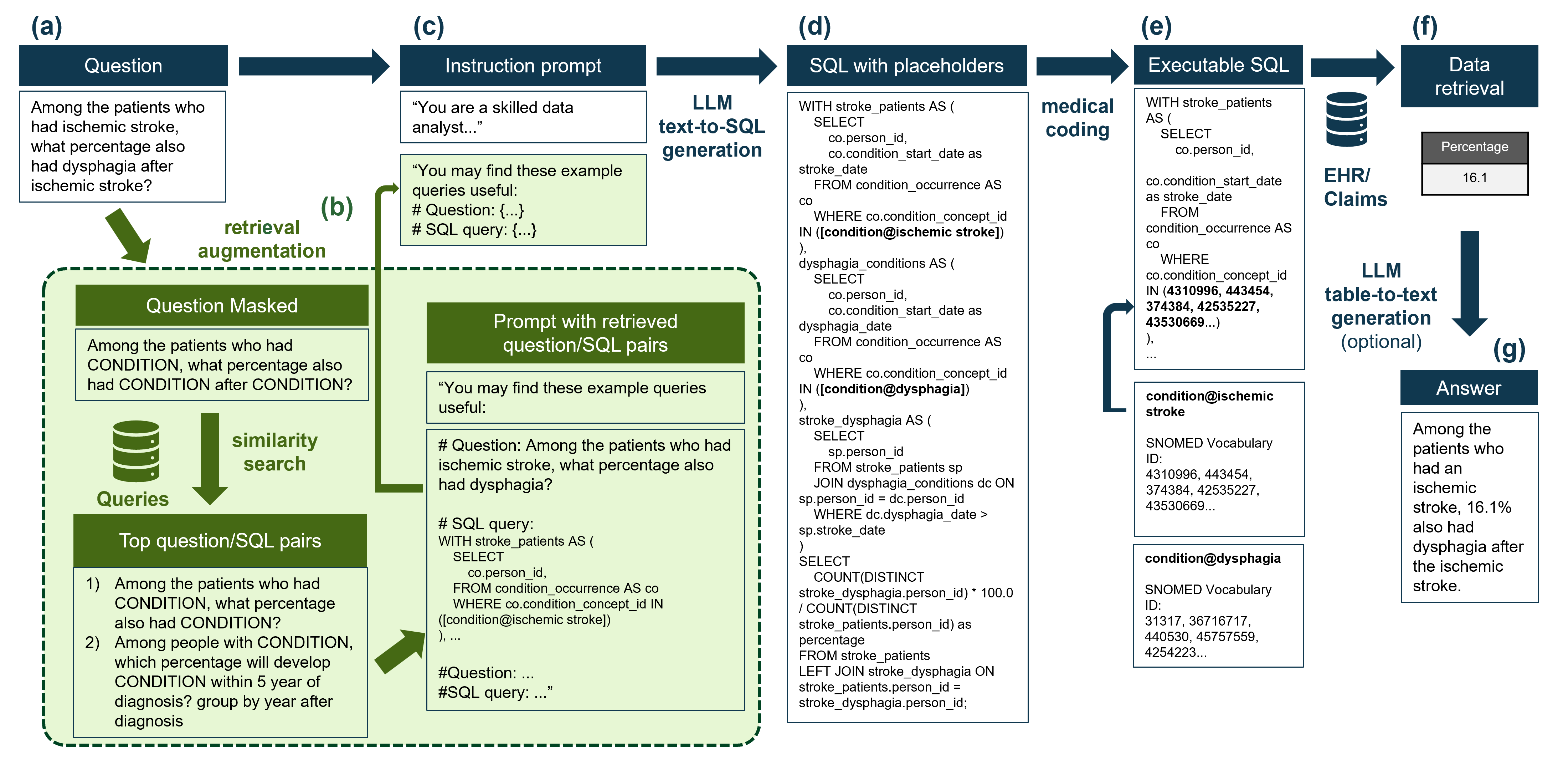 這是主要結果:
這是主要結果: 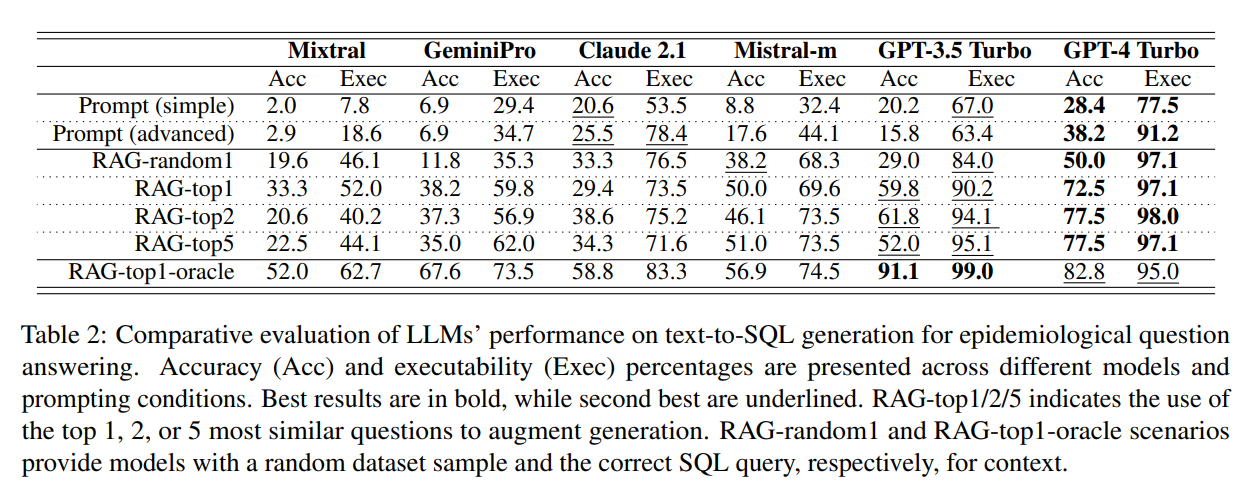
請參閱手稿以獲取更多詳細信息:https://arxiv.org/abs/2403.09226
標記的問題-SQL對在dataset集文件夾中的文件text2sql_epi_dataset_omop.xlsx中。
我們在實驗中使用了Python 3.11。
從GitHub上的Master Branch安裝最新版本:
git clone <GITHUB-URL>
cd text-to-sql-epi-ehr-naacl2024
pip install -r requirements.txt
首先,我們需要從dataset文件夾中提供的Excel文件創建一個醃製文件(查詢庫)
cd scripts
python run_querylib_calc.py
然後將使用此泡菜文件在查詢生成階段執行檢索增強生成(RAG)。
要執行預測,請用雙引號以您的問題運行腳本prediction_pipeline.py 。例如,
cd scripts
python prediction_pipeline.py --question "How many women with atopic dermatitis?"
這應該返回:
Question: How many women with atopic dermatitis?
SQL template:
SELECT COUNT(DISTINCT p.person_id) AS female_patients_with_atopic_dermatitis
FROM condition_occurrence AS co
JOIN person AS p ON co.person_id = p.person_id
WHERE co.condition_concept_id IN ([condition@atopic dermatitis])
AND p.gender_concept_id = 8532;
要執行查詢,您將是Google Cloud上的數據集的鏈接:https://console.cloud.google.com/marketplace/product/product/hhs/synpuf您可以打開鏈接(需要Google帳戶),並在Google帳戶中運行查詢。
要使查詢可在Google BigQuery上執行,您將需要修改表的生成名稱以符合Google查詢表名稱。這只是桌子的重命名。
例如,
SELECT COUNT(DISTINCT p.person_id) AS female_patients_with_atopic_dermatitis
FROM person AS p
JOIN condition_occurrence AS co ON p.person_id = co.person_id
JOIN concept AS c ON co.condition_concept_id = c.concept_id
WHERE p.gender_concept_id = 8532
AND c.concept_id IN (133834,4298597,4066382,4298599,4296193,4080929,4296192,4290738,4290734,4206125,4290736,4080928,4033671,4031630,4297478,4296190,4031631,4080927,4298598,4298601,4031013,4297362,4290740,4297495,40482226,4298600,4236759);
必須更改為
SELECT
COUNT(DISTINCT p.person_id) AS female_patients_with_atopic_dermatitis
FROM `bigquery-public-data.cms_synthetic_patient_data_omop.person` AS p
JOIN `bigquery-public-data.cms_synthetic_patient_data_omop.condition_occurrence` AS co ON p.person_id = co.person_id
JOIN `bigquery-public-data.cms_synthetic_patient_data_omop.concept` AS c ON co.condition_concept_id = c.concept_id
WHERE p.gender_concept_id = 8532
AND c.concept_id IN (133834,4298597,4066382,4298599,4296193,4080929,4296192,4290738,4290734,4206125,4290736,4080928,4033671,4031630,4297478,4296190,4031631,4080927,4298598,4298601,4031013,4297362,4290740,4297495,40482226,4298600,4236759);
在上面的BigQuery實例上運行。
如果您有自己的雪花數據倉庫,則可能不需要執行這些更改。
在存儲庫中,我們為醫學編碼提供了一個模型版本,以顯示如何將醫療編碼整合到過程中,如上圖所示。編碼是在SNOMED本體中執行的,因為這是存儲在OMOP公共數據模型(OMOP-CDM)中的數據的基本本體。該表通常在OMOP-CDM中稱為Concept_table。
我們在dataset集文件夾中準備了一個稱為medcodes_mockup.xlsx的小型模型表。在這裡,我們根據OMOP-CDM的數據結構提供合成數據。您可以在此處從國家醫學圖書館下載整個本體。 (請注意,您需要接受他們的條款和條件)
例如,可以在此處找到有關Snomed-CT的更多信息
首先,我們需要從提供的Excel文件中創建一個醃製文件(Medcodeonto庫)
cd scripts
python run_medcoding_calc.py
然後將使用此醃製文件來搜索醃製文件中的醫療代碼。運行文件還將提供一個示例,說明如何執行編碼。
請注意,這只是模型實現。對於準備生產的版本,我們建議使用矢量數據庫(例如QDRANT),例如從雪花數據庫中為整個概念表索引。
運行Medical coding compilation步驟後,您可以運行完整的管道:SQL查詢生成 +醫療編碼。
這是一個例子:
cd scripts
python prediction_pipeline.py --med_coding True --question "How many females with atopic dermatitis"
這將返回
Use medical coding: True
Use Snowflake database: False
No sentence-transformers model found with name BAAI/bge-large-en-v1.5. Creating a new one with MEAN pooling.
Question: How many females with atopic dermatitis
SQL template:
SELECT COUNT(DISTINCT p.person_id) AS female_patients_with_atopic_dermatitis
FROM condition_occurrence AS co
JOIN person AS p ON co.person_id = p.person_id
WHERE co.condition_concept_id IN ([condition@atopic dermatitis])
AND p.gender_concept_id = 8532;
Loading embedding from C:UsersGKENYOneDrive - BayerPersonal Dataascenttext-to-sql-epi-ehr-naacl2024data_outmedcodes_onto.pkl
Retrieved codes: {'atopic dermatitis': [{'Score': 0.8221014142036438, 'CONCEPT_NAME': 'Dermatitis in children', 'CONCEPT_ID': 4296192, 'DOMAIN_ID': 'Condition', 'VOCABULARY_ID': 'SNOMED', 'STANDARD_CONCEPT': 'S', 'CONCEPT_CODE': 402196005}, {'Score': 0.8056577444076538, 'CONCEPT_NAME': 'Widespread dermatitis', 'CONCEPT_ID': 4298597, 'DOMAIN_ID': 'Condition', 'VOCABULARY_ID': 'SNOMED', 'STANDARD_CONCEPT': 'S', 'CONCEPT_CODE': 402186001}, {'Score': 0.7999188899993896, 'CONCEPT_NAME': 'Early childhood dermatitis', 'CONCEPT_ID': 4298599, 'DOMAIN_ID': 'Condition', 'VOCABULARY_ID': 'SNOMED', 'STANDARD_CONCEPT': 'S', 'CONCEPT_CODE': 402195009}, {'Score': 0.7992758750915527, 'CONCEPT_NAME': 'Facial dermatitis', 'CONCEPT_ID': 4298598, 'DOMAIN_ID': 'Condition', 'VOCABULARY_ID': 'SNOMED', 'STANDARD_CONCEPT': 'S', 'CONCEPT_CODE': 402192007}]}
Please note that the medical coding is based on a mockup ontology. Results will not be reliable
SQL filled:
SELECT COUNT(DISTINCT p.person_id) AS female_patients_with_atopic_dermatitis
FROM condition_occurrence AS co
JOIN person AS p ON co.person_id = p.person_id
WHERE co.condition_concept_id IN (4296192,4298597,4298599,4298598)
AND p.gender_concept_id = 8532;
請注意,醫療編碼步驟僅在這裡示例性。為了獲得可靠的結果,您需要訪問完整的SNOMED本體(請參閱Medical coding compilation部分)。


