LLM Survey
1.0.0
大型語言模型調查存儲庫是一項全面的彙編,該彙編專門用於探索和理解大語言模型(LLMS)。它包含各種資源,包括研究論文,博客文章,教程,代碼示例等,以深入了解LLMS的進步,方法和應用。對於AI研究人員,數據科學家或對LLMS的進步和內部運作感興趣的AI研究人員,數據科學家或愛好者來說,此存儲庫是寶貴的資源。我們鼓勵更廣泛的社區的貢獻促進協作學習,並繼續推動LLM研究的界限。
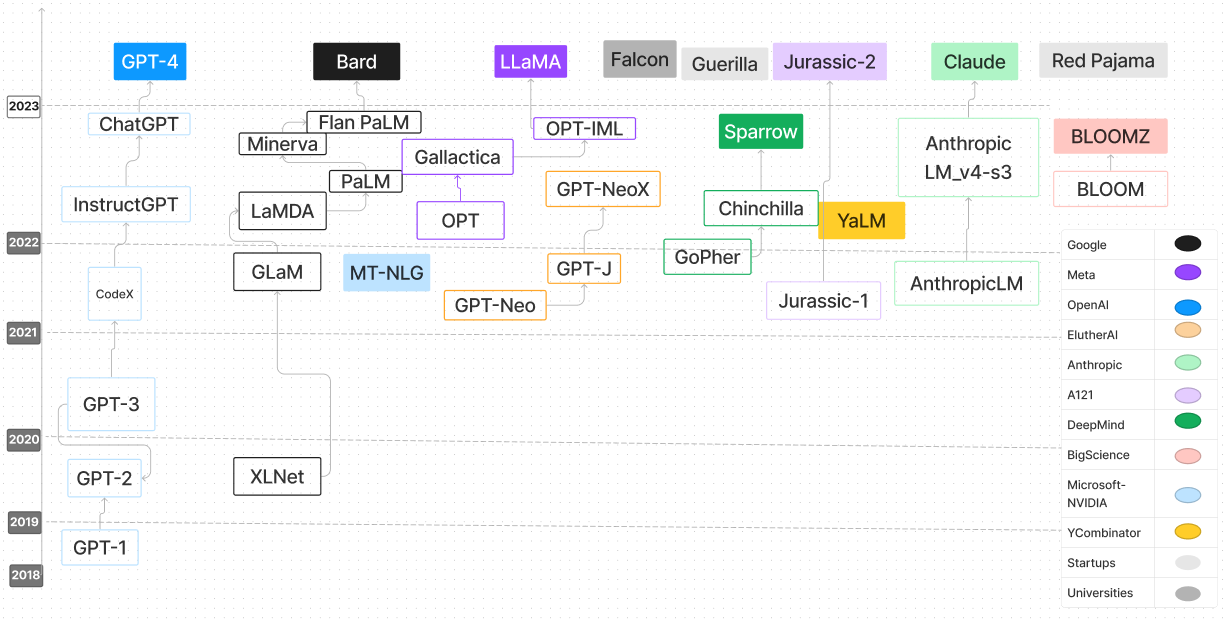
| 語言模型 | 發布日期 | 檢查點 | 紙/博客 | 參數(b) | 上下文長度 | 執照 | 嘗試一下 |
|---|---|---|---|---|---|---|---|
| T5 | 2019/10 | T5&Flan-T5,Flan-T5-XXL(HF) | 使用統一的文本到文本變壓器探索轉移學習的限制 | 0.06-11 | 512 | Apache 2.0 | t5大 |
| UL2 | 2022/10 | UL2和Flan-UL2,Flan-UL2(HF) | UL2 20B:開源統一語言學習者 | 20 | 512,2048 | Apache 2.0 | |
| 共同 | 2022/06 | 檢查點 | 代碼 | 54 | 4096 | 模型 | 網站 |
| 小腦-GPT | 2023/03 | 小腦-GPT | 小腦-GPT:一個開放,計算效率,大語言模型(紙)的家族 | 0.111-13 | 2048 | Apache 2.0 | 小腦-GPT-1.3B |
| 開放助理(腓出家族) | 2023/03 | OA-PYTHIA-12B-SFT-8,OA-PYTHIA-12B-SFT-4,OA-PYTHIA-12B-SFT-1 | 使大語模型的民主化 | 12 | 2048 | Apache 2.0 | 畢田2.8B |
| 畢田 | 2023/04 | 腓出70m -12b | 腓熱:一套用於分析跨培訓和擴展的大型語言模型的套件 | 0.07-12 | 2048 | Apache 2.0 | |
| 多莉 | 2023/04 | Dolly-V2-12b | 免費Dolly:介紹世界上第一個真正的開放指導調整的LLM | 3、7、12 | 2048 | 麻省理工學院 | |
| dlite | 2023/05 | dlite-v2-1_5b | 宣布dlite v2:輕巧,可以在任何地方運行的LLM | 0.124-1.5 | 1024 | Apache 2.0 | dlite-v2-1.5b |
| RWKV | 2021/08 | rwkv,chatrwkv | RWKV語言模型(和我的LM技巧) | 0.1-14 | 無窮大(RNN) | Apache 2.0 | |
| GPT-J-6B | 2023/06 | GPT-J-6B,GPT4All-J | GPT-J-6B:基於JAX的6B變壓器 | 6 | 2048 | Apache 2.0 | |
| GPT-Neox-20b | 2022/04 | GPT-Neox-20b | GPT-NEOX-20B:開源自回歸語言模型 | 20 | 2048 | Apache 2.0 | |
| 盛開 | 2022/11 | 盛開 | Bloom:176B參數開放式多語言模型 | 176 | 2048 | OpenRail-M V1 | |
| Stablelm-Alpha | 2023/04 | Stablelm-Alpha | 穩定性AI啟動了其第一個語言模型的Stablelm套件 | 3-65 | 4096 | CC BY-SA-4.0 | |
| FastChat-T5 | 2023/04 | fastchat-t5-3b-v1.0 | 我們很高興發布FastChat-T5:我們的緊湊型友好型聊天機器人! | 3 | 512 | Apache 2.0 | |
| H2ogpt | 2023/05 | H2ogpt | 建立世界上最好的開源大語言模型:H2O.AI的旅程 | 12-20 | 256-2048 | Apache 2.0 | |
| MPT-7B | 2023/05 | MPT-7B,MPT-7B教學 | 介紹MPT-7B:開源,商業可用LLM的新標準 | 7 | 84K(alibi) | Apache 2.0,CC BY-SA-3.0 | |
| pangu-σ | 2023/3 | pangu | 模型 | 1085 | - | 模型 | 頁 |
| redpajama-結構 | 2023/05 | redpajama-結構 | 釋放3B和7B Redpajama-結構模型家族,包括基本,指導調整和聊天模型 | 3-7 | 2048 | Apache 2.0 | Redpajama-Incite-Instruct-3B-V1 |
| Ottinllama | 2023/05 | open_llama_3b,open_llama_7b,open_llama_13b | Openllama:駱駝的開放繁殖 | 3,7 | 2048 | Apache 2.0 | optlllama-7b-preview_200bt |
| 鶻 | 2023/05 | Falcon-180B,Falcon-40B,Falcon-7b | Falcon LLM的精製網絡數據集:僅具有Web數據的策劃的Corpora和Web數據 | 180、40、7 | 2048 | Apache 2.0 | |
| MPT-30B | 2023/06 | MPT-30B,MPT-30B教學 | MPT-30B:提高開源基礎模型的標準 | 30 | 8192 | Apache 2.0,CC BY-SA-3.0 | MPT 30B推理代碼使用CPU |
| 美洲駝2 | 2023/06 | 駱駝2個權重 | 駱駝2:開放基礎和微調聊天模型 | 7-70 | 4096 | 自定義免費,如果您的用戶不到7億用戶,並且除了Llama及其衍生品外,也無法使用Llama輸出來培訓其他LLM | 擁抱 |
| OpenLM | 2023/09 | OpenLM 1B,OpenLM 7B | 開放LM:最少但表現性的語言建模(LM)存儲庫 | 1,7 | 2048 | 麻省理工學院 | |
| Mistral 7b | 2023/09 | MISTRAL-7B-V0.1,MISTRAL-7B-INSTRUCT-V0.1 | Mistral 7b | 7 | 4096-16k帶滑動窗口 | Apache 2.0 | Mistral Transformer |
| OpenHermes | 2023/09 | OpenHermes-7b,OpenHermes-13b | 研究 | 7,13 | 4096 | 麻省理工學院 | 在Mistral 7b上進行的OpenHermes-V2固定 |
| 太陽的 | 2023/12 | Solar-10.7b | 上升 | 10.7 | 4096 | Apache-2.0 | |
| PHI-2 | 2023/12 | PHI-2 2.7b | 微軟 | 2.7 | 2048 | 麻省理工學院 | |
| Santacoder | 2023/01 | Santacoder | Santacoder:不要伸手去拿星星! | 1.1 | 2048 | OpenRail-M V1 | Santacoder |
| Starcoder | 2023/05 | Starcoder | StarCoder:代碼的最先進的LLM,StarCoder:願來源與您同在! | 1.1-15 | 8192 | OpenRail-M V1 | |
| Starchat Alpha | 2023/05 | Starchat-Alpha | 用Starcoder創建編碼助手 | 16 | 8192 | OpenRail-M V1 | |
| 補充代碼 | 2023/05 | REPLIT-CODE-V1-3B | 在1週內培訓SOTA Code LLM並量化氛圍 | 2.7 | 無限? (alibi) | CC BY-SA-4.0 | REPLIT-CODE-V1-3B |
| CodeGen2 | 2023/04 | CodeGen2 1b-16b | CodeGen2:用於編程和自然語言的培訓LLM的課程 | 1-16 | 2048 | Apache 2.0 | |
| codet5+ | 2023/05 | codet5+ | CODET5+:打開代碼大型語言模型,用於代碼理解和生成 | 0.22-16 | 512 | BSD-3-C-sause | codet5+-6b |
| XGEN-7B | 2023/06 | XGEN-7B-8K基礎 | 使用XGEN的長序列建模:在8K輸入序列長度上訓練的7B LLM | 7 | 8192 | Apache 2.0 | |
| CodeGen2.5 | 2023/07 | CodeGen2.5-7B-Multi | Codegen2.5:小,但強大 | 7 | 2048 | Apache 2.0 | |
| DICODER-1B | 2023/08 | DICODER-1B | 介紹Decicoder:高效,準確代碼生成的新黃金標準 | 1.1 | 2048 | Apache 2.0 | DECICODER演示 |
| 代碼駱駝 | 2023 | Codellama模型的推理代碼 | 代碼駱駝:代碼的開放基礎模型 | 7-34 | 4096 | 模型 | 擁抱 |
| 麻雀 | 2022/09 | 推理代碼 | 代碼 | 70 | 4096 | 模型 | 網頁 |
| Mistral | 2023/09 | 推理代碼 | 代碼 | 7 | 8000 | 模型 | 網頁 |
| 無尾熊 | 2023/04 | 推理代碼 | 代碼 | 13 | 4096 | 模型 | 網頁 |
| 棕櫚2 | 2024 | N/A。 | Google AI | 540 | N/A。 | N/A。 | N/A。 |
| Tongyi Qianwen | 2024 | N/A。 | 阿里巴巴雲 | N/A。 | N/A。 | N/A。 | N/A。 |
| cohere命令 | 2024 | N/A。 | 共同 | 6-52 | N/A。 | N/A。 | N/A。 |
| Vicuna 33b | 2024 | N/A。 | meta ai | 33 | N/A。 | N/A。 | N/A。 |
| 瓜納科65B | 2024 | N/A。 | meta ai | 65 | N/A。 | N/A。 | N/A。 |
| 亞馬遜Q | 2024 | N/A。 | AWS | N/A。 | N/A。 | N/A。 | N/A。 |
| 獵鷹180b | 2024 | Falcon-180b | 技術創新研究所 | 180 | N/A。 | Apache 2.0 | N/A。 |
| yi 34b | 2024 | N/A。 | 01 AI | 34 | 最多32K | N/A。 | N/A。 |
| 混合8x7b | 2023 | 混合8x 7b | Mistral AI | 46.7(每個令牌12.9) | N/A。 | Apache 2.0 | N/A。 |
如果您發現我們的調查對您的研究有用,請引用以下論文:
@article{hadi2024large,
title={Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects},
author={Hadi, Muhammad Usman and Al Tashi, Qasem and Shah, Abbas and Qureshi, Rizwan and Muneer, Amgad and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and others},
journal={Authorea Preprints},
year={2024},
publisher={Authorea}
}


