LLM Survey
1.0.0
Das Survey Repository für große Sprachmodelle ist ein umfassendes Kompendium, das sich der Erkundung und dem Verständnis von großsprachigen Modellen (LLMs) widmet. Es beherbergt eine Auswahl an Ressourcen, einschließlich Forschungsarbeiten, Blog-Posts, Tutorials, Code-Beispielen und vielem mehr, um einen detaillierten Einblick in die Fortschritte, die Methoden und Anwendungen von LLMs zu bieten. Dieses Repo ist eine unschätzbare Ressource für KI -Forscher, Datenwissenschaftler oder Enthusiasten, die an den Fortschritten und inneren Funktionen von LLMs interessiert sind. Wir ermutigen Beiträge der breiteren Gemeinschaft, das kollaborative Lernen zu fördern und die Grenzen der LLM -Forschung weiter zu überschreiten.
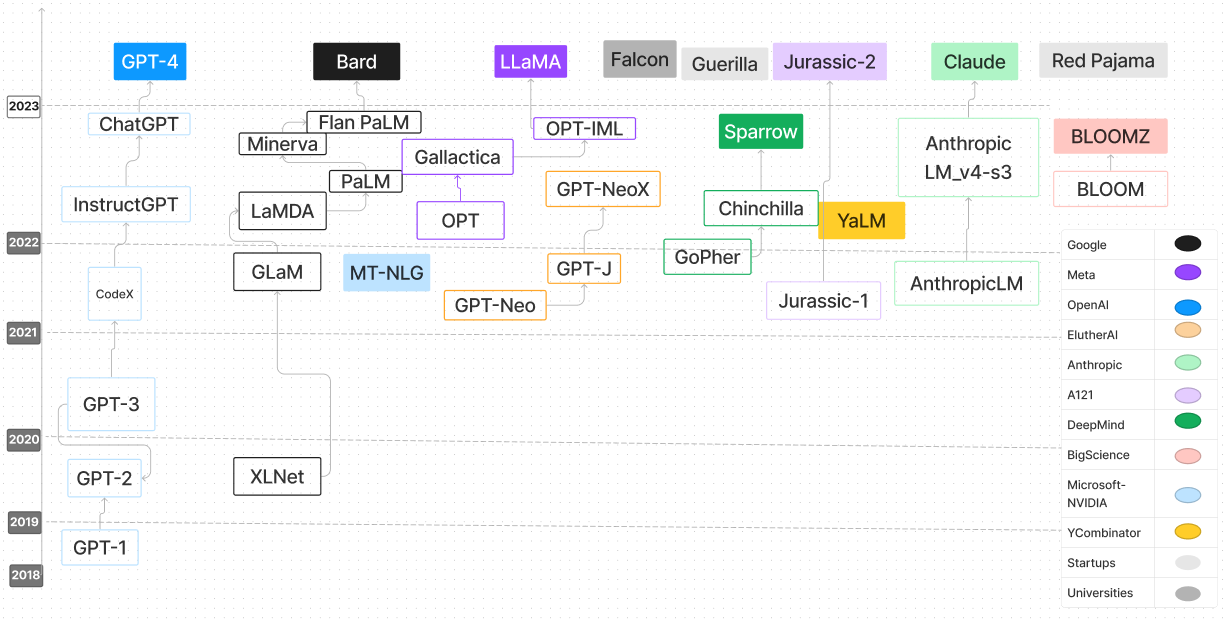
| Sprachmodell | Veröffentlichungsdatum | Kontrollpunkte | Papier/Blog | Parameter (b) | Kontextlänge | Lizenz | Versuchen Sie es |
|---|---|---|---|---|---|---|---|
| T5 | 2019/10 | T5 & Flan-T5, Flan-T5-XXL (HF) | Erforschen der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator | 0,06 - 11 | 512 | Apache 2.0 | T5-large |
| Ul2 | 2022/10 | UL2 & Flan-ul2, Flan-ul2 (HF) | UL2 20B: Ein einheitlicher Open -Source -Lerner der Sprache | 20 | 512, 2048 | Apache 2.0 | |
| Zusammenhängen | 2022/06 | Kontrollpunkt | Code | 54 | 4096 | Modell | Webseite |
| Cerebras-GPT | 2023/03 | Cerebras-GPT | Cerebras-GPT: Eine Familie offener, recheneffizienter, großer Sprachmodelle (Papier) | 0,111 - 13 | 2048 | Apache 2.0 | Cerebras-GPT-1.3b |
| Offener Assistent (Familie Pythia) | 2023/03 | OA-Pythia-12b-SFT-8, OA-Pythia-12b-SFT-4, OA-Pythia-12b-SFT-1 | Demokratisierung des großsprachigen Modellausrichts | 12 | 2048 | Apache 2.0 | Pythia-2.8b |
| Pythien | 2023/04 | Pythien 70 m - 12b | Pythien: Eine Suite zur Analyse von großsprachigen Modellen im Training und der Skalierung | 0,07 - 12 | 2048 | Apache 2.0 | |
| Dolly | 2023/04 | Dolly-V2-12b | Free Dolly: Einführung der ersten wirklich offenen Unterrichts-LLM der Welt der Welt vorstellen | 3, 7, 12 | 2048 | MIT | |
| Dlite | 2023/05 | dlite-v2-1_5b | Ankündigung von DLite V2: Leichtes, offenes LLMs, die überall laufen können | 0,124 - 1,5 | 1024 | Apache 2.0 | Dlite-v2-1.5b |
| Rwkv | 2021/08 | Rwkv, chatrwkv | Das RWKV -Sprachmodell (und meine LM -Tricks) | 0,1 - 14 | Unendlichkeit (RNN) | Apache 2.0 | |
| GPT-J-6B | 2023/06 | GPT-J-6B, GPT4ALL-J | GPT-J-6B: 6B JAX-basierter Transformator | 6 | 2048 | Apache 2.0 | |
| GPT-NEOX-20B | 2022/04 | GPT-NEOX-20B | GPT-NEOX-20B: Ein open-Source-autoregressives Sprachmodell | 20 | 2048 | Apache 2.0 | |
| Blühen | 2022/11 | Blühen | Blüte: Ein mehrsprachiges Sprachmodell mit 176B-Parameter Open-Access | 176 | 2048 | OpenRail-M v1 | |
| Stablelm-Alpha | 2023/04 | Stablelm-Alpha | Stability AI startet die erste seiner Stablelm -Suite von Sprachmodellen | 3 - 65 | 4096 | CC BY-Sa4.0 | |
| Fastchat-T5 | 2023/04 | Fastchat-T5-3b-V1.0 | Wir freuen uns, Fastchat-T5 zu veröffentlichen: unseren kompakten und kommerziellen Chatbot! | 3 | 512 | Apache 2.0 | |
| H2OGPT | 2023/05 | H2OGPT | Aufbau des weltbesten Open-Source-großsprachigen Modells: H2O.AIs Reise | 12 - 20 | 256 - 2048 | Apache 2.0 | |
| MPT-7B | 2023/05 | MPT-7B, MPT-7B-Instruct | Einführung von MPT-7B: Ein neuer Standard für Open-Source, kommerziell verwendbare LLMs | 7 | 84k (Alibi) | Apache 2.0, CC BY-SA-3.0 | |
| Pangu-σ | 2023/3 | Pangu | Modell | 1085 | - - | Modell | Seite |
| Redpajama-Eingabe | 2023/05 | Redpajama-Eingabe | Veröffentlichung von 3B- und 7B Redpajama-Einkommenfamilie von Models, einschließlich Basis-, Anleitungs- und Chat-Models | 3 - 7 | 2048 | Apache 2.0 | Redpajama-Incite-Instruct-3B-V1 |
| Openllama | 2023/05 | open_llama_3b, open_llama_7b, open_llama_13b | Openllama: Eine offene Reproduktion von Lama | 3, 7 | 2048 | Apache 2.0 | Openllama-7b-Preview_200BT |
| Falke | 2023/05 | Falcon-180b, Falcon-40b, Falcon-7b | Der RefinedWeb -Datensatz für Falcon LLM: Übertreibende kuratierte Corpora mit Webdaten und nur Webdaten übertreffen | 180, 40, 7 | 2048 | Apache 2.0 | |
| MPT-30B | 2023/06 | MPT-30B, MPT-30B-Instruktur | MPT-30B: Erhöhen Sie die Messlatte für Open-Source Foundation-Modelle | 30 | 8192 | Apache 2.0, CC BY-SA-3.0 | MPT 30B Inferenzcode mit CPU |
| Lama 2 | 2023/06 | Lama 2 Gewichte | LAMA 2: Open Foundation und Feinabstimmung Chat-Modelle | 7 - 70 | 4096 | Custom Free, wenn Sie unter 700 Millionen Benutzern haben und keine Lama -Ausgaben verwenden können, um andere LLMs neben Lama und seinen Derivaten zu trainieren | Umarmung |
| OpenLM | 2023/09 | OpenLM 1B, OpenLM 7B | Offenes LM: Ein minimales, aber performatives Repository (LM) -Plade (LM) | 1, 7 | 2048 | MIT | |
| Mistral 7b | 2023/09 | Mistral-7b-V0.1, Mistral-7b-Instruct-V0.1 | Mistral 7b | 7 | 4096-16k mit Schiebernfenstern | Apache 2.0 | Mistraltransformator |
| Openhermes | 2023/09 | Openhermes-7b, Openhermes-13b | Nous Forschung | 7, 13 | 4096 | MIT | Openhermes-V2, das auf Mistral 7b beendet ist |
| SOLAR | 2023/12 | Solar-10.7b | Upstage | 10.7 | 4096 | Apache-2.0 | |
| Phi-2 | 2023/12 | PHI-2 2.7b | Microsoft | 2.7 | 2048 | MIT | |
| Santacoder | 2023/01 | Santacoder | Santacoder: Greifen Sie nicht nach den Sternen! | 1.1 | 2048 | OpenRail-M v1 | Santacoder |
| StarCoder | 2023/05 | StarCoder | STARCODER: Ein hochmoderner LLM für Code, StarCoder: Möge die Quelle mit Ihnen sein! | 1.1-15 | 8192 | OpenRail-M v1 | |
| Starchat Alpha | 2023/05 | Starchat-Alpha | Erstellen eines Codierungsassistenten mit StarCoder | 16 | 8192 | OpenRail-M v1 | |
| Replit -Code | 2023/05 | Replit-Code-V1-3b | Training eines SOTA -Code -LLM in 1 Woche und Quantifizierung der Stimmung - mit Reza Shabani von Replit | 2.7 | Unendlichkeit? (Alibi) | CC BY-Sa4.0 | Replit-Code-V1-3b |
| CodeGen2 | 2023/04 | CODEGEN2 1B-16B | CodeGen2: Lektionen für Trainings -LLMs für Programmierung und natürliche Sprachen | 1 - 16 | 2048 | Apache 2.0 | |
| Codet5+ | 2023/05 | Codet5+ | Codet5+: Öffnen Sie Code großsprachige Modelle für das Verständnis und die Generierung von Code und Generierung | 0,22 - 16 | 512 | BSD-3-Klausel | Codet5+-6b |
| Xgen-7b | 2023/06 | XGEN-7B-8K-BASE | Lange Sequenzmodellierung mit XGen: A 7B LLM, das auf 8K -Eingangssequenzlänge trainiert wurde | 7 | 8192 | Apache 2.0 | |
| CodeGen2.5 | 2023/07 | CodeGen2.5-7b-Multi | CodeGen2.5: klein, aber mächtig | 7 | 2048 | Apache 2.0 | |
| Decicoder-1b | 2023/08 | Decicoder-1b | Einführung von Decicoder: Der neue Goldstandard in effizienter und genauer Codegenerierung | 1.1 | 2048 | Apache 2.0 | Decicoder -Demo |
| Code Lama | 2023 | Inferenzcode für Codellama -Modelle | Code LLAMA: Open Foundation -Modelle für Code offen | 7 - 34 | 4096 | Modell | Umarmung |
| Spatz | 2022/09 | Inferenzcode | Code | 70 | 4096 | Modell | Webseite |
| Mistral | 2023/09 | Inferenzcode | Code | 7 | 8000 | Modell | Webseite |
| Koala | 2023/04 | Inferenzcode | Code | 13 | 4096 | Modell | Webseite |
| Palm 2 | 2024 | N / A | Google AI | 540 | N / A | N / A | N / A |
| Tongyi Qianwen | 2024 | N / A | Alibaba Cloud | N / A | N / A | N / A | N / A |
| Cohere -Befehl | 2024 | N / A | Zusammenhängen | 6 - 52 | N / A | N / A | N / A |
| Vicuna 33b | 2024 | N / A | Meta Ai | 33 | N / A | N / A | N / A |
| Guanaco-65b | 2024 | N / A | Meta Ai | 65 | N / A | N / A | N / A |
| Amazon q | 2024 | N / A | AWS | N / A | N / A | N / A | N / A |
| Falcon 180b | 2024 | Falcon-180b | Technology Innovation Institute | 180 | N / A | Apache 2.0 | N / A |
| Yi 34b | 2024 | N / A | 01 ai | 34 | Bis zu 32k | N / A | N / A |
| Mixtral 8x7b | 2023 | Mixtral 8x 7b | Mistral Ai | 46,7 (12,9 pro Token) | N / A | Apache 2.0 | N / A |
Wenn Sie unsere Umfrage für Ihre Forschung nützlich finden, zitieren Sie bitte das folgende Papier:
@article{hadi2024large,
title={Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects},
author={Hadi, Muhammad Usman and Al Tashi, Qasem and Shah, Abbas and Qureshi, Rizwan and Muneer, Amgad and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and others},
journal={Authorea Preprints},
year={2024},
publisher={Authorea}
}


